






本文来源公众号“极市平台”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/5VYP0e648cnKk2-G4PK3Hw
极市导读
本文提出只留高亮 Token 会丢掉全局上下文,导致高剪枝率下性能雪崩。团队提出 HoloV,把图片切块后「分区给预算、重排再采样」,88.9% 视觉 Token 被砍掉,LLaVA-1.5 仍保留 95.8% 精度,推理提速 2× 以上,为端侧多模态大模型「瘦身」给出新范式。
多模态大语言模型(MLLMs)虽然功能强大,但处理高分辨率图片时,海量的视觉Token(可以理解为图像的“像素块”信息)带来了巨大的计算开销,让推理速度变得很慢。为了给这些“臃肿”的模型“瘦身”,学术界一直在研究视觉Token剪枝(Token Pruning)技术,也就是丢掉那些不重要的视觉信息。
最近,一篇被 NeurIPS 2025 接收的论文《Don't Just Chase "Highlighted Tokens" in MLLMs: Revisiting Visual Holistic Context Retention》对现有的剪枝方法提出了挑战,并带来了一个简单又高效的解决方案—— HoloV。这项研究由香港科技大学、INSAIT、索非亚大学和上海交通大学等机构的研究者们共同完成。HoloV这个名字源于“Holistic Vision”,强调了它在剪枝时所采用的“全局视觉”策略。

-
论文标题: Don't Just Chase "Highlighted Tokens" in MLLMs: Revisiting Visual Holistic Context Retention
-
作者: Xin Zou, Di Lu, Yizhou Wang, Yibo Yan, Yuanhuiyi Lyu, Xu Zheng, Linfeng Zhang, Xuming Hu
-
机构: 香港科技大学(广州)、香港科技大学、INSAIT 索非亚大学、上海交通大学
-
录用会议: NeurIPS 2025
-
论文地址: https://arxiv.org/abs/2510.02912
-
项目地址: https://github.com/obananas/HoloV
01 现有方法的困境:只追“高光”,丢失全局
以往的Token剪枝方法,如FastV,大多采用一种“注意力优先”(Attention-First)的策略。它们通过计算文本和视觉之间的交叉注意力,或者利用特殊的[CLS] Token的注意力得分,来判断哪些视觉Token最“重要”,然后保留这些“高光”Token。
这种方法看似合理,但论文作者发现了一个致命缺陷:注意力机制倾向于关注那些语义相似的Token。比如,一张图里有一只猫,那么很多高注意力的Token可能都集中在描述这只猫的不同部位。在高比例剪枝(比如剪掉90%)的情况下,模型保留下来的可能是一堆关于“猫”的冗余信息,而图片中的背景、其他物体等全局上下文信息则被完全丢弃了。这导致模型性能急剧下降。
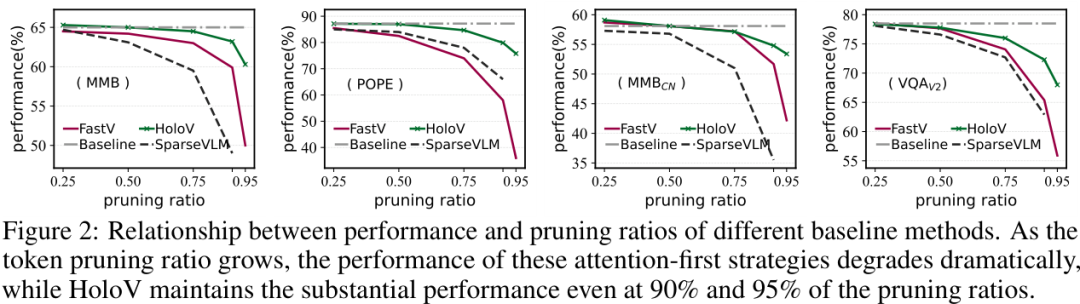
上图清晰地展示了这个问题,随着剪枝率的提高,基于注意力的方法(虚线)性能急剧恶化,而HoloV(实线)则能在高剪枝率下依然保持强大的性能。

上图右侧的可视化案例更直观,FastV保留的Token(绿色点)高度集中,存在大量冗余,而HoloV保留的Token则分布更均匀,覆盖了更丰富的上下文信息。
02 HoloV:从全局视角保留视觉上下文
为了解决上述问题,HoloV放弃了只追逐“高光”Token的思路,而是从一个更宏观、更整体的视角(Holistic Perspective)来重新思考Token的保留策略。
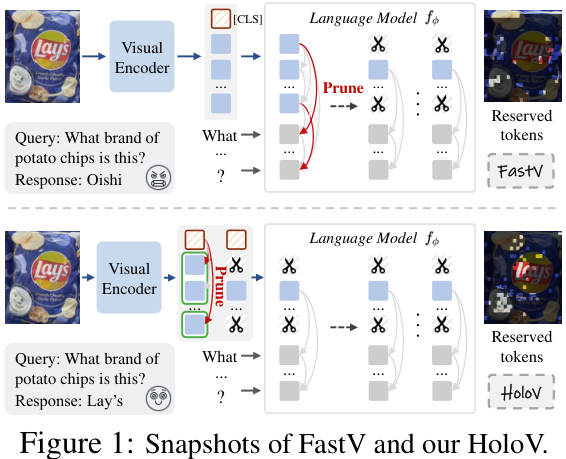
HoloV的核心机制可以概括为:
-
划分区域:将输入的图片看作由多个空间区块(Spatial Crops)组成。
-
预算分配:不再将所有“保留名额”都给注意力最高的Token,而是自适应地将剪枝预算分配到不同的空间区块中。
-
全局保留:通过对高亮Token进行重新排序,确保最终保留下来的Token能够覆盖全局的视觉上下文,而不是仅仅聚集在少数几个显著特征上。

通过这种方式,HoloV避免了“表征崩溃”(Representational Collapse)的现象,即使在极高的剪枝率下,也能有效地保留与任务相关的重要信息,实现了局部显著性和全局上下文的平衡。
03 实验结果:极致的效率-精度权衡
HoloV作为一个即插即用的框架,在多种任务、多种MLLM架构和不同剪枝率下都展现了卓越的性能。
最惊人的结果是,在LLaVA-1.5模型上,HoloV 在剪掉了88.9%的视觉Token后,依然保留了原始模型95.8%的性能,实现了顶尖的效率-精度权衡。
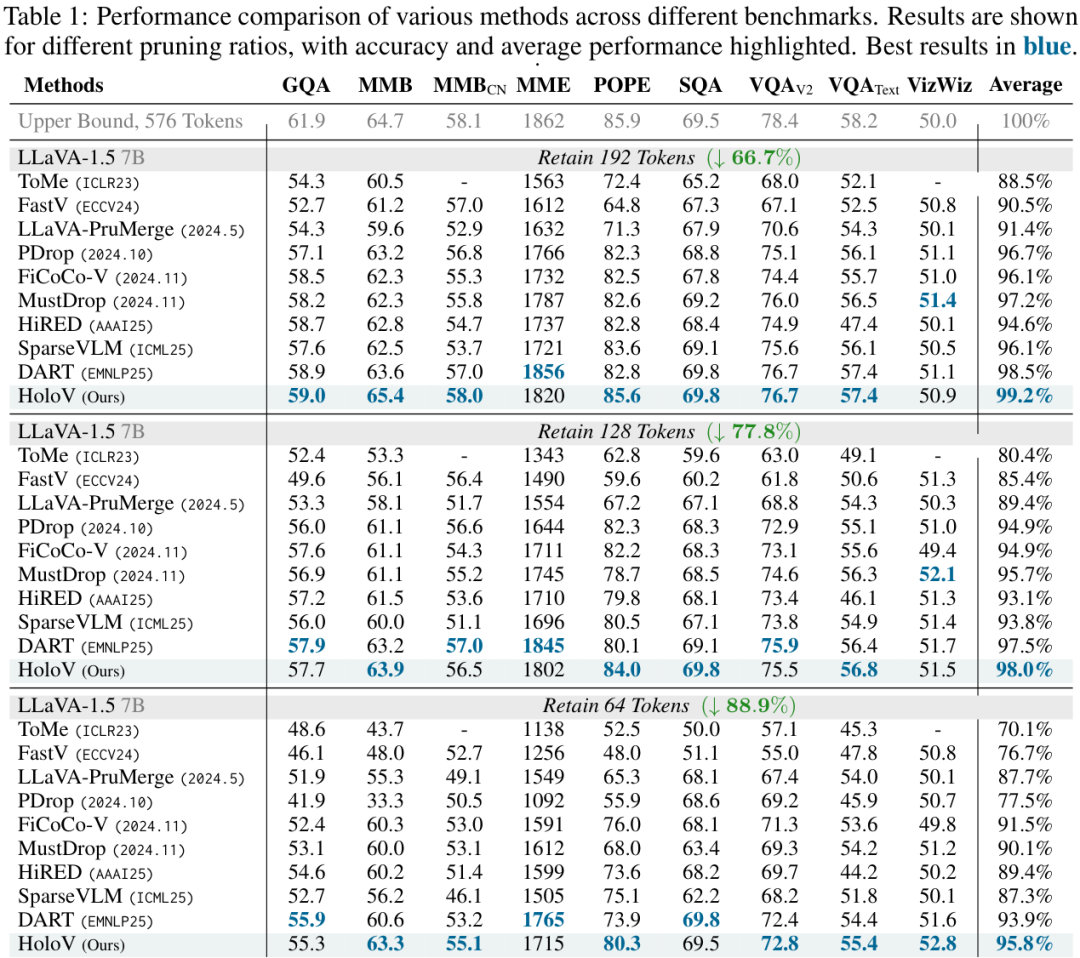
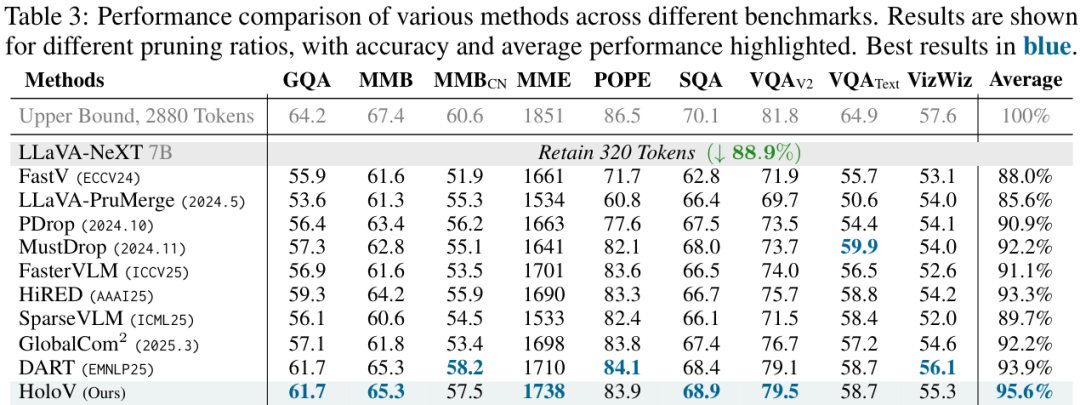
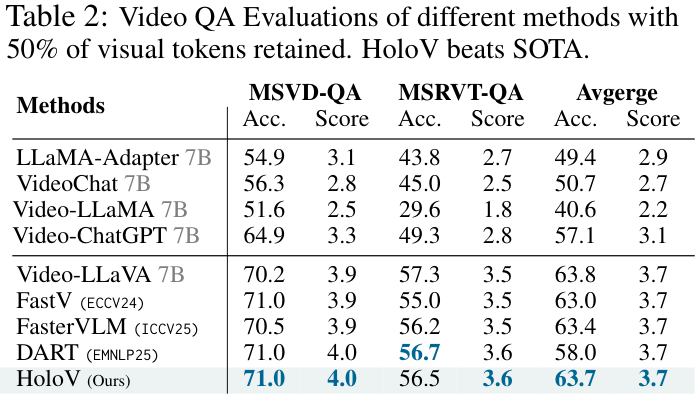
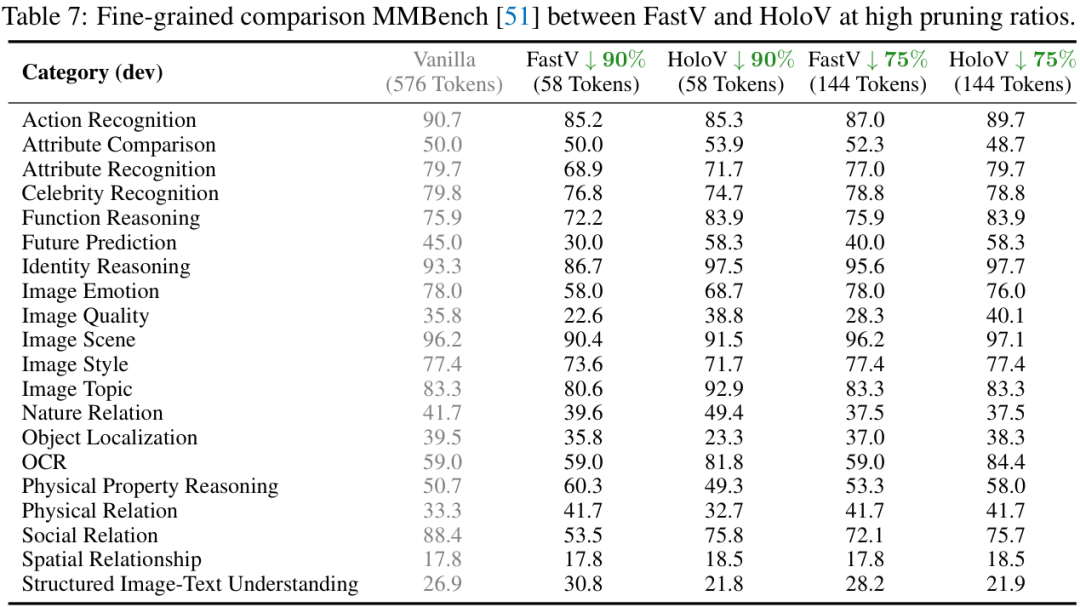
从上面两个性能对比表中可以看到,无论是在哪个基准测试上,HoloV(蓝色字体)的平均性能都远超其他SOTA方法,尤其是在高剪枝率(如87.5%)下,优势更为明显。
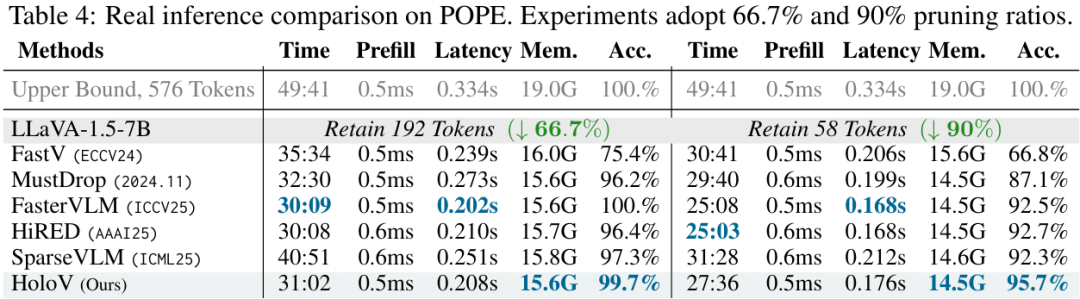
在推理速度上,HoloV也带来了实打实的提升。
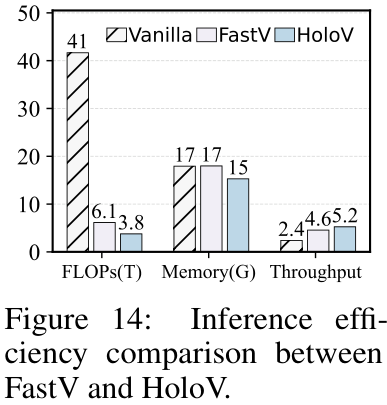
该方法不仅适用于图像任务,在视频问答(Video QA)任务上同样有效。
下面的可视化案例生动地对比了FastV和HoloV在不同剪枝率下的表现。可以看到,HoloV更好地保留了图片中的关键对象和场景信息(如路标、远处的建筑等),而FastV则丢失了大量重要上下文。




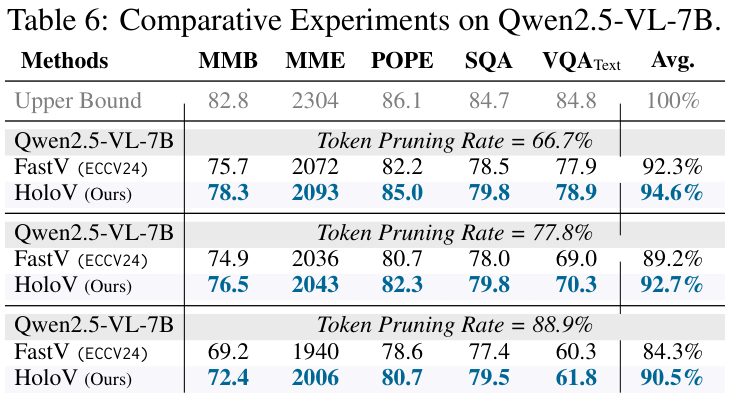
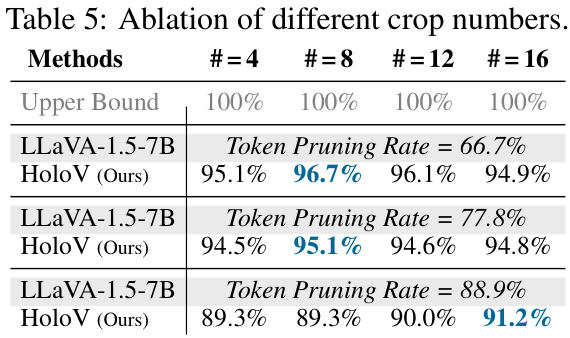
此外,作者还对不同的模型(如Qwen2.5-VL)、不同的剪枝率、不同的超参数(如区块数量)进行了广泛的实验和消融研究,均验证了HoloV的有效性和鲁棒性。
04 总结
小编认为,HoloV的思路为多模态大模型的效率优化提供了一个全新的、有价值的方向。在追求效率、进行信息压缩时,不能仅仅关注局部的显著性,更要保留信息的完整性和多样性。“全局观”在AI的世界里同样至关重要。HoloV的提出,无疑为实现更高效、更实用的MLLM应用铺平了道路。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









