






本文来源公众号“戎易大数据”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/VyQwShDWd8lO35CQ-cL2zA
1.1 数据预览
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport warningswarnings.filterwarnings('ignore')
data = pd.read_csv('/home/mw/input/kucun8458/products.csv')data.head()
data.info()输出:
<class 'pandas.core.frame.DataFrame'>RangeIndex: 10000 entries, 0 to 9999Data columns (total 14 columns):Product ID 10000 non-null objectProduct Name 10000 non-null objectProduct Category 10000 non-null objectProduct Description 10000 non-null objectPrice 10000 non-null float64Stock Quantity 10000 non-null int64Warranty Period 10000 non-null int64Product Dimensions 10000 non-null objectManufacturing Date 10000 non-null objectExpiration Date 10000 non-null objectSKU 10000 non-null objectProduct Tags 10000 non-null objectColor/Size Variations 10000 non-null objectProduct Ratings 10000 non-null int64dtypes: float64(1), int64(3), object(10)memory usage: 1.1+ MB
data.isnull().sum()输出:
Product ID 0Product Name 0Product Category 0Product Description 0Price 0Stock Quantity 0Warranty Period 0Product Dimensions 0Manufacturing Date 0Expiration Date 0SKU 0Product Tags 0Color/Size Variations 0Product Ratings 0dtype: int64
data.duplicated().sum()
char = data.select_dtypes(include=['object']).columns.tolist()
for i in char:
print(f'{i}:')
print(data[i].unique())
输出:
Product ID:['93TGNAY7' 'TYYZ5AV7' '5C94FGTQ' ... 'FD57S4E1' 'RPYLOB1M' '3JWTGTOM']Product Name:['Laptop' 'Smartphone' 'Headphones' 'Monitor']Product Category:['Home Appliances' 'Clothing' 'Electronics']Product Description:['Product_XU5QX' 'Product_NRUMS' 'Product_IT7HG' ... 'Product_GYAWW''Product_K3M9M' 'Product_I0ACF']Product Dimensions:['16x15x15 cm' '15x19x19 cm' '9x6x6 cm' ... '5x12x15 cm' '14x11x5 cm''9x19x8 cm']Manufacturing Date:['2023-01-01' '2023-03-15' '2023-07-30']Expiration Date:['2026-01-01' '2025-01-01' '2024-01-01']SKU:['8NMFZ4' '7P5YCW' 'YW5BME' ... 'MKJ0UW' 'INSC1B' 'UH0U3R']Product Tags:['VNU,NZ6' 'ZJA,0D3' 'ZNG,MAP' ... 'GO4,EZE' '0QB,U55' 'C5R,TZN']Color/Size Variations:['Green/Large' 'Red/Small' 'Blue/Medium']
商品名称和商品类别并不匹配,需要重新调整商品类别
1.2 数据清洗
# 拆分尺寸列dimension_split = data['Product Dimensions'].str.extract(r'(\d+)x(\d+)x(\d+)').astype(float)data[['Length(cm)', 'Width(cm)', 'Height(cm)']] = dimension_split# 移除原尺寸列data.drop('Product Dimensions', axis=1, inplace=True)data.head()
color_size_split = data['Color/Size Variations'].str.split('/', expand=True)data[['Color', 'Size']] = color_size_splitdata.drop(columns=['Color/Size Variations'], inplace=True)data.head()
data['Manufacturing Date'] = pd.to_datetime(data['Manufacturing Date'], format='%Y-%m-%d')data['Expiration Date'] = pd.to_datetime(data['Expiration Date'], format='%Y-%m-%d')# 创建一个字典来映射产品名称到正确的分类category_mapping = {'Laptop': 'Computer','Smartphone': 'Mobile','Headphones': 'Audio','Monitor': 'Audio'}# 应用映射来更新category列data['Product Category'] = data['Product Name'].map(category_mapping).fillna(data['Product Category'])data.head()
1.3 异常值检测
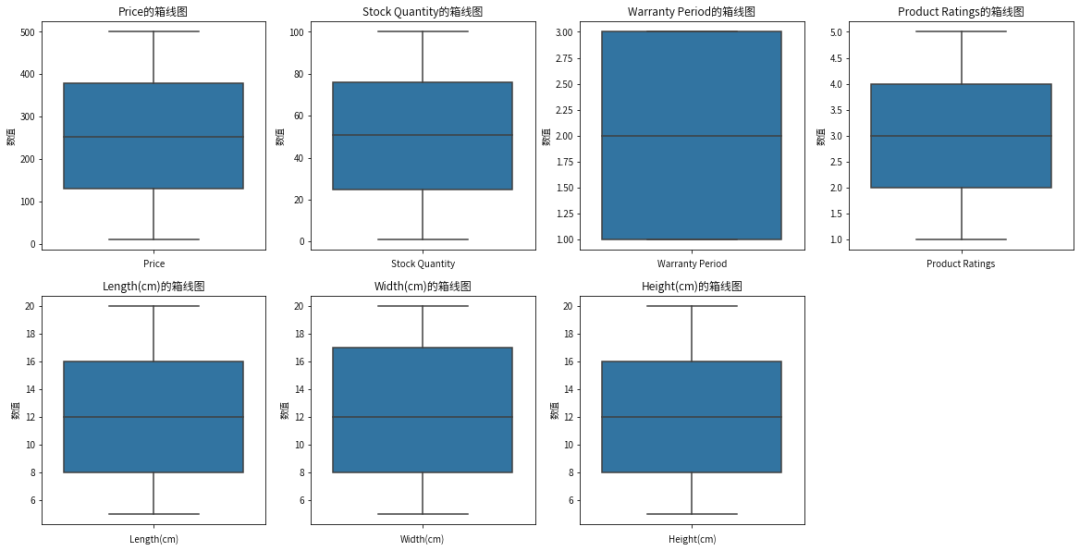
features = data.select_dtypes(include=['int64', 'float64']).columns.tolist()plt.figure(figsize=(20, 10))for i, feature in enumerate(features):plt.subplot(2, 4, i+1)sns.boxplot(y=data[feature])plt.title(f'{feature}的箱线图')plt.xlabel(f'{feature}')plt.ylabel(f'数值')plt.show()
描述性分析与可视化展示
2.1 描述性分析
data.describe(include='all').T输出:
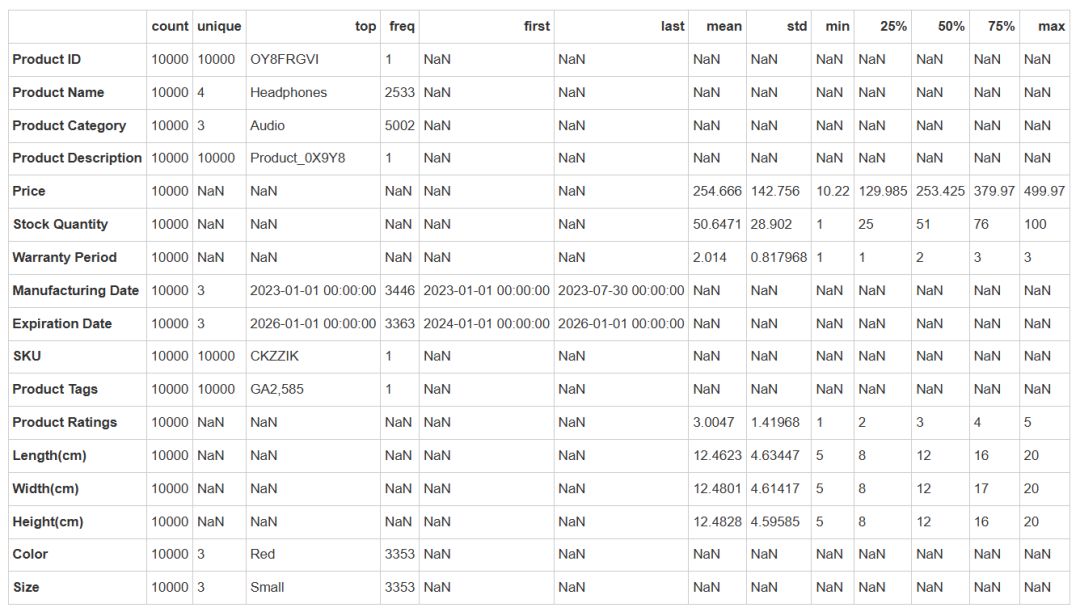
商品共4类,其中耳机的数量最多,共出现2533次。
商品类别共3类,其中音频设备的数量最多,共出现5002次。
价格的平均值是254.67美元,标准差是142.76美元,说明商品的价格差异较为明显。最小值是10.22美元,最大值是499.97美元。
库存数量的平均值是50.65,标准差是28.90,最小值是1,最大值是100。
保修期的平均值是2.01年,标准差是0.82年,最小值是1年,最大值是3年。
商品评分的平均值是3.00,标准差是1.42,最小值是1,最大值是5。
长度的平均值是12.46厘米,标准差是4.63厘米,最小值是5厘米,最大值是20厘米。
宽度的平均值是12.48厘米,标准差是4.61厘米,最小值是5厘米,最大值是20厘米。
高度的平均值是12.48厘米,标准差是4.59厘米,最小值是5厘米,最大值是20厘米。
颜色共3类,其中红色的数量最多,共出现3353次。
尺寸共3类,其中小型的数量最多,共出现3353次。
2.2 可视化展示
plt.figure(figsize=(20, 12))plt.subplot(2, 4, 1)sns.countplot(x='Product Name', data=data, palette='spring')plt.title('商品分布', fontsize=20)plt.xlabel('商品名称', fontsize=16)plt.ylabel('数量', fontsize=16)for p in plt.gca().patches:plt.gca().annotate(format(p.get_height(), '.0f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points')plt.subplot(2, 4, 2)plt.pie(data['Product Name'].value_counts(), labels=data['Product Name'].value_counts().index, autopct='%1.1f%%', startangle=90,colors=['#ff9999','#66b3ff','#99ff99','#ffcc99'])plt.title('商品占比', fontsize=20)plt.subplot(2, 4, 3)sns.countplot(x='Product Category', data=data, palette='summer')plt.title('商品类别分布', fontsize=20)plt.xlabel('商品类别', fontsize=16)plt.ylabel('数量', fontsize=16)for p in plt.gca().patches:plt.gca().annotate(format(p.get_height(), '.0f') ,(p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points')plt.subplot(2, 4, 4)plt.pie(data['Product Category'].value_counts(), labels=data['Product Category'].value_counts().index, autopct='%1.1f%%', startangle=90,colors=['#ff9999','#66b3ff','#99ff99','#ffcc99'])plt.title('商品类别占比', fontsize=20)plt.subplot(2, 4, 5)sns.countplot(x='Color', data=data, palette='autumn')plt.title('颜色分布', fontsize=20)plt.xlabel('颜色', fontsize=16)plt.ylabel('数量', fontsize=16)for p in plt.gca().patches:plt.gca().annotate(format(p.get_height(), '.0f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points')plt.subplot(2, 4, 6)plt.pie(data['Color'].value_counts(), labels=data['Color'].value_counts().index, autopct='%1.1f%%', startangle=90,colors=['#ff9999','#66b3ff','#99ff99','#ffcc99'])plt.title('颜色占比', fontsize=20)plt.subplot(2, 4, 7)sns.countplot(x='Size', data=data, palette='winter')plt.title('尺码分布', fontsize=20)plt.xlabel('尺码', fontsize=16)plt.ylabel('数量', fontsize=16)for p in plt.gca().patches:plt.gca().annotate(format(p.get_height(), '.0f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points')plt.subplot(2, 4, 8)plt.pie(data['Size'].value_counts(), labels=data['Size'].value_counts().index, autopct='%1.1f%%', startangle=90,colors=['#ff9999','#66b3ff','#99ff99','#ffcc99'])plt.title('尺码占比', fontsize=20)plt.show()
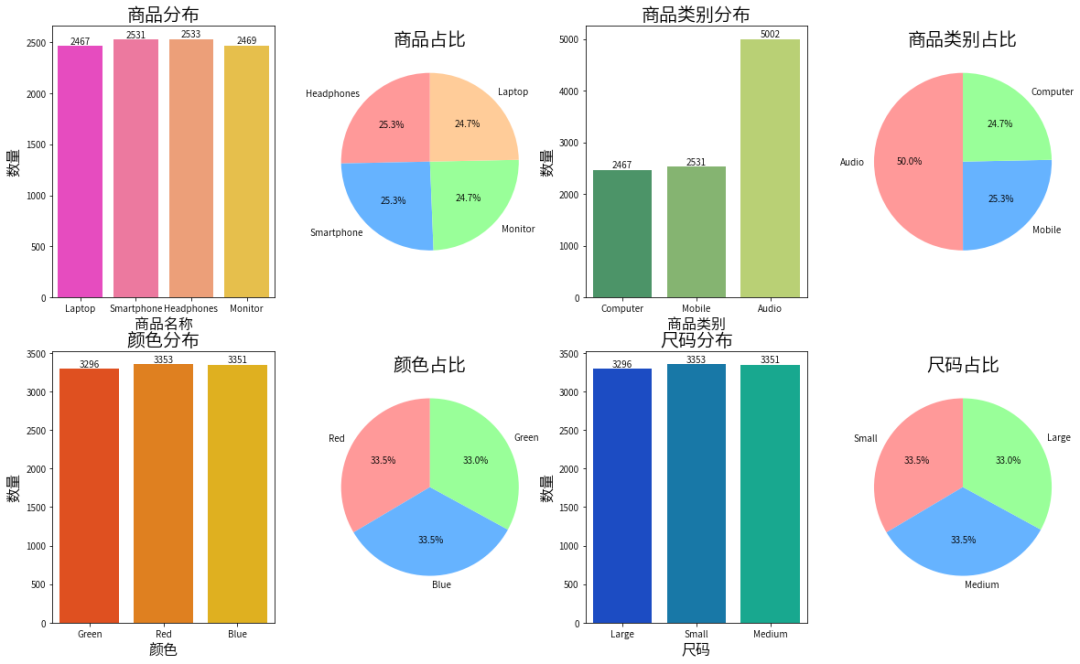
商品中共包含笔记本电脑、智能手机、耳机、显示器4类,分布较为均衡,各个商品占比均在25%左右。
商品类别中以音频设备为主,共占50%,其次为智能手机。
颜色分为绿色、红色和蓝色三类,各个颜色分布较为均匀。
尺码上分布较为均衡。
总体而言,各个分类的分布都很均匀,没有明显的偏向性。
plt.figure(figsize=(20, 10))for i, feature in enumerate(features):plt.subplot(2, 4, i+1)sns.distplot(data[feature], kde=True)plt.title(f'{feature}的直方图')plt.xlabel(f'{feature}')plt.ylabel(f'数值')plt.show()
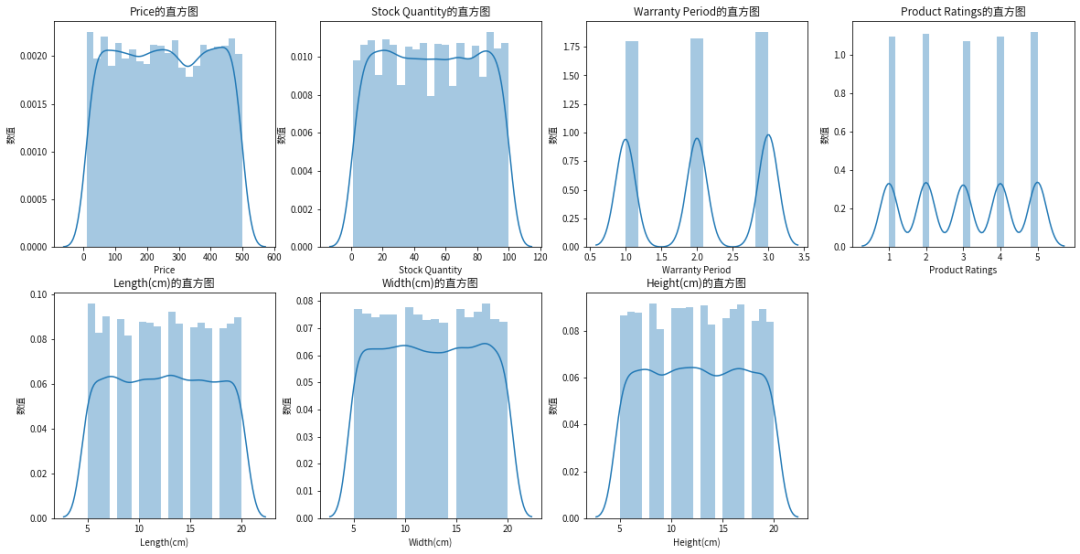
探索性数据分析
plt.figure(figsize=(20, 6))plt.subplot(1, 3, 1)sns.boxplot(x='Product Name', y='Price',data=data)plt.title('不同商品的价格分布', fontsize=20)plt.xlabel('商品名称', fontsize=16)plt.ylabel('价格', fontsize=16)plt.subplot(1, 3, 2)sns.boxplot(x='Product Name', y='Stock Quantity',data=data)plt.title('不同商品的库存分布', fontsize=20)plt.xlabel('商品名称', fontsize=16)plt.ylabel('库存数量', fontsize=16)plt.subplot(1, 3, 3)sns.boxplot(x='Product Name', y='Product Ratings',data=data)plt.title('不同商品的评分分布', fontsize=20)plt.xlabel('商品名称', fontsize=16)plt.ylabel('评分', fontsize=16)plt.show()
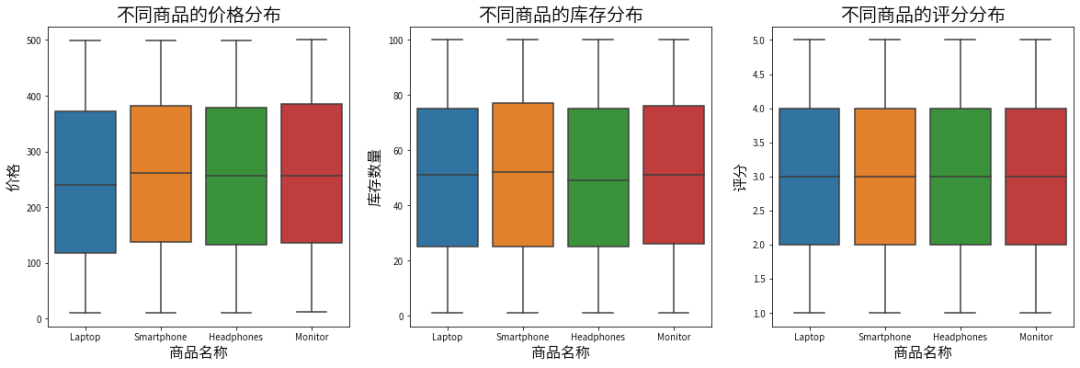
智能手机的价格稍微高一点,笔记本电脑的价格相对低一些。
库存数量上,耳机的库存数量比其他品类低一些,智能手机的库存数量也比其他品类高一些。
评分上四个品类差异不大。
plt.figure(figsize=(20, 6))plt.subplot(1, 3, 1)sns.boxplot(x='Product Category', y='Price',data=data)plt.title('不同商品的价格分布', fontsize=20)plt.xlabel('商品名称', fontsize=16)plt.ylabel('价格', fontsize=16)plt.subplot(1, 3, 2)sns.boxplot(x='Product Category', y='Stock Quantity',data=data)plt.title('不同商品的库存分布', fontsize=20)plt.xlabel('商品名称', fontsize=16)plt.ylabel('库存数量', fontsize=16)plt.subplot(1, 3, 3)sns.boxplot(x='Product Category', y='Product Ratings',data=data)plt.title('不同商品的评分分布', fontsize=20)plt.xlabel('商品名称', fontsize=16)plt.ylabel('评分', fontsize=16)plt.show()
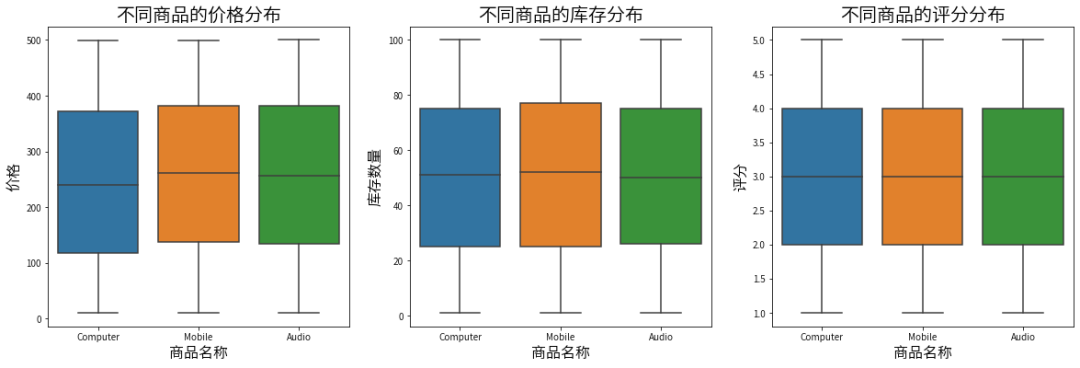
手机设备的平均价格最高,电脑设备的平均价格最低。
手机设备的库存数量最多,音频设备的库存数量最少。
三个类别的评分差异不明显。
产品生命周期聚类分析
4. 产品生命周期聚类分析
from sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_scorefrom sklearn.preprocessing import StandardScaler
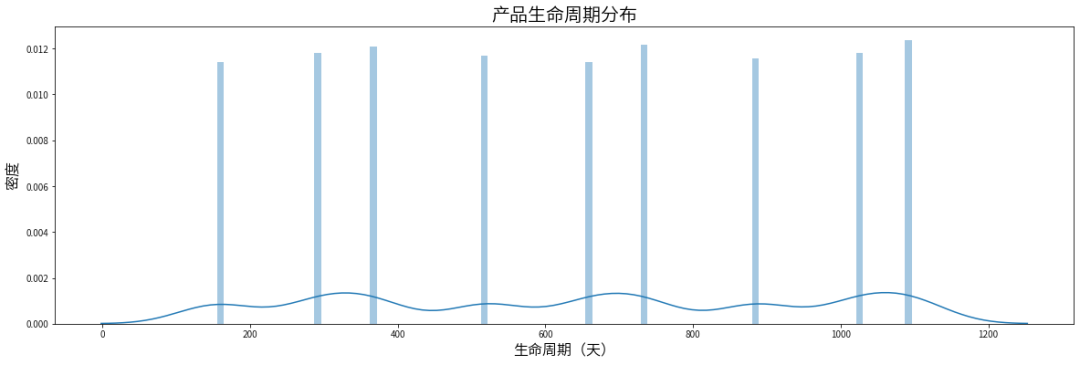
#计算产品生命周期data['life_cycle'] = (data['Expiration Date'] - data['Manufacturing Date']).dt.daysplt.figure(figsize=(20, 6))sns.distplot(data['life_cycle'], bins=100, kde=True)plt.title('产品生命周期分布', fontsize=20)plt.xlabel('生命周期(天)', fontsize=16)plt.ylabel('密度', fontsize=16)plt.show()
输出:
data['remaining_days'] = (data['Expiration Date'] - pd.Timestamp.today()).dt.daysdata['time_decay'] = data['remaining_days'] / data['life_cycle']
features = data[['life_cycle', 'Stock Quantity', 'time_decay', 'Product Ratings']].copy()scaler = StandardScaler()data_scaled = scaler.fit_transform(features)
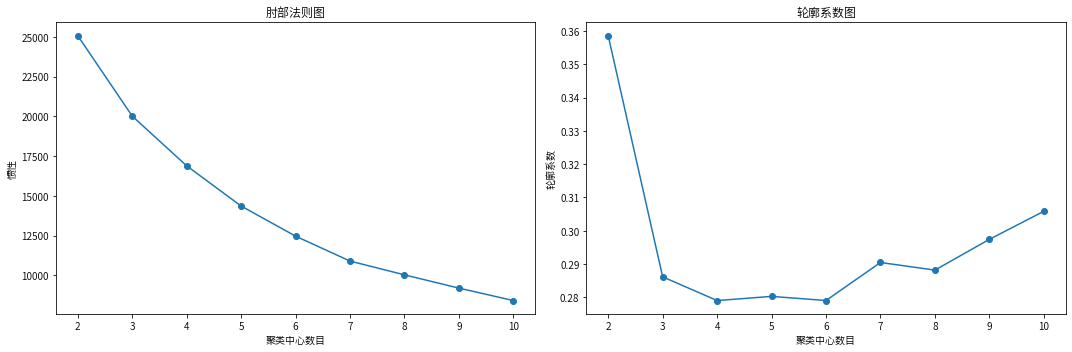
# 使用肘部法则来确定最佳聚类数inertia = []silhouette_scores = []k_range = range(2, 11)for k in k_range:kmeans = KMeans(n_clusters=k, random_state=15).fit(data_scaled)inertia.append(kmeans.inertia_)silhouette_scores.append(silhouette_score(data_scaled, kmeans.labels_))
plt.figure(figsize=(15,5))plt.subplot(1, 2, 1)plt.plot(k_range, inertia, marker='o')plt.xlabel('聚类中心数目')plt.ylabel('惯性')plt.title('肘部法则图')plt.subplot(1, 2, 2)plt.plot(k_range, silhouette_scores, marker='o')plt.xlabel('聚类中心数目')plt.ylabel('轮廓系数')plt.title('轮廓系数图')plt.tight_layout()plt.show()
输出:
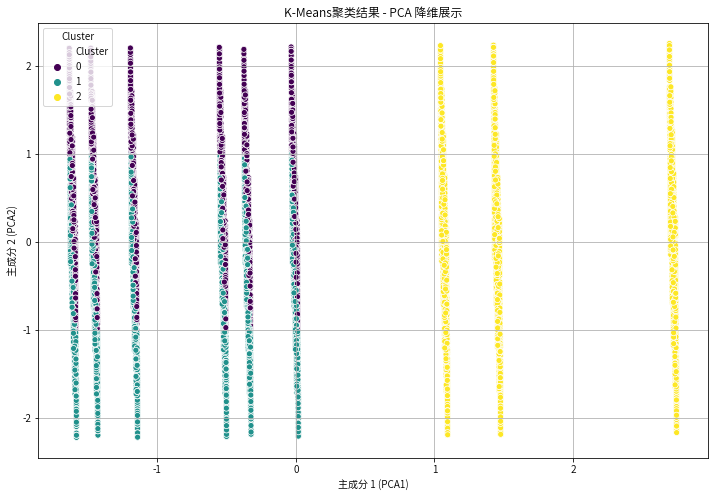
kmeans = KMeans(n_clusters=3, random_state=15)kmeans.fit(data_scaled)# 获取聚类标签cluster_labels = kmeans.labels_# 将聚类标签添加到原始数据中以进行分析data['Cluster'] = cluster_labelsfrom sklearn.decomposition import PCA# 使用 PCA 将数据降维到 2 维pca = PCA(n_components=2)data_pca = pca.fit_transform(data_scaled)# 将 PCA 结果转为 DataFrame,并添加聚类标签data_pca_df = pd.DataFrame(data_pca, columns=['PCA1', 'PCA2'])data_pca_df['Cluster'] = cluster_labels# 绘制 PCA 降维后的聚类结果plt.figure(figsize=(12, 8))sns.scatterplot(x=data_pca_df['PCA1'], y=data_pca_df['PCA2'], hue=data_pca_df['Cluster'], palette='viridis', legend='full')plt.title(f'K-Means聚类结果 - PCA 降维展示')plt.xlabel('主成分 1 (PCA1)')plt.ylabel('主成分 2 (PCA2)')plt.legend(title='Cluster', loc='upper left')plt.grid(True)plt.show()
输出:
cluster_profile = data.groupby('Cluster').agg({'life_cycle': 'median','Stock Quantity': 'median','time_decay': 'mean','Product Ratings': 'median','Price': 'median'}).reset_index()cluster_profile
输出:
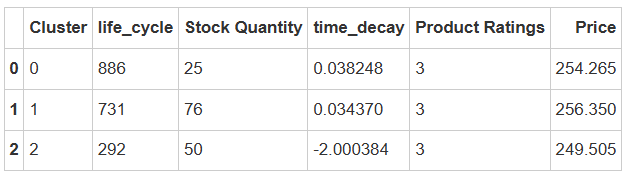
聚类0:
产品生命周期的平均值为886天,周期长
库存数量平均值为25,库存数量少
价格平均值为254.265美元,价格中等
聚类1:
产品生命周期的平均值为731天,周期中等
库存数量平均值为76,库存数量多
价格平均值为256.350美元,价格高
聚类2:
产品生命周期的平均值为292天,周期短
库存数量平均值为50,库存数量中等
价格平均值为249.505美元,价格低
库存分布合理性检验
5.1 库存分布分析
# 按商品分组,计算每个类别的库存总量category_inventory = data.groupby('Product Name')['Stock Quantity'].sum().reset_index()# 绘制库存分布图plt.figure(figsize=(20, 6))sns.barplot(x='Product Name', y='Stock Quantity', data=category_inventory, palette='Set2')plt.title('不同商品的库存数量分布', fontsize=20)plt.xlabel('商品名称', fontsize=16)plt.ylabel('库存数量', fontsize=16)for p in plt.gca().patches:plt.gca().annotate(format(p.get_height(), '.0f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha = 'center', va = 'center', xytext = (0, 5), textcoords = 'offset points')plt.show()
输出:
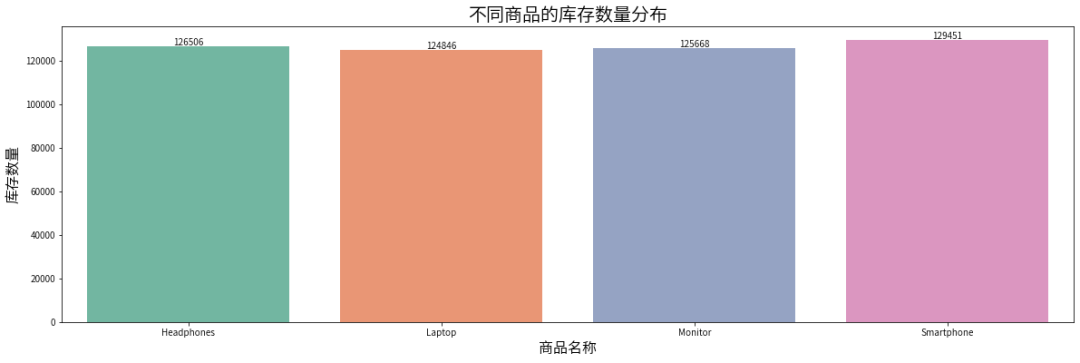
各个商品的库存数量差异不是特别明显,其中智能手机的库存数量最多,其次是耳机,再者是显示器,最后是笔记本电脑。
5.2 库存价值分析
# 计算每个商品的库存价值data['Inventory Value'] = data['Price'] * data['Stock Quantity']# 按商品分组,计算每个类别的库存总价值category_value = data.groupby('Product Name')['Inventory Value'].sum().reset_index()# 绘制库存价值分布图plt.figure(figsize=(20, 6))sns.barplot(x='Product Name', y='Inventory Value', data=category_value, palette='Set2')plt.title('不同商品的库存价值分布', fontsize=20)plt.xlabel('商品名称', fontsize=16)plt.ylabel('库存价值', fontsize=16)for p in plt.gca().patches:plt.gca().annotate(format(p.get_height(), '.2f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha = 'center', va = 'center', xytext = (0, 5), textcoords = 'offset points')plt.show()
输出:
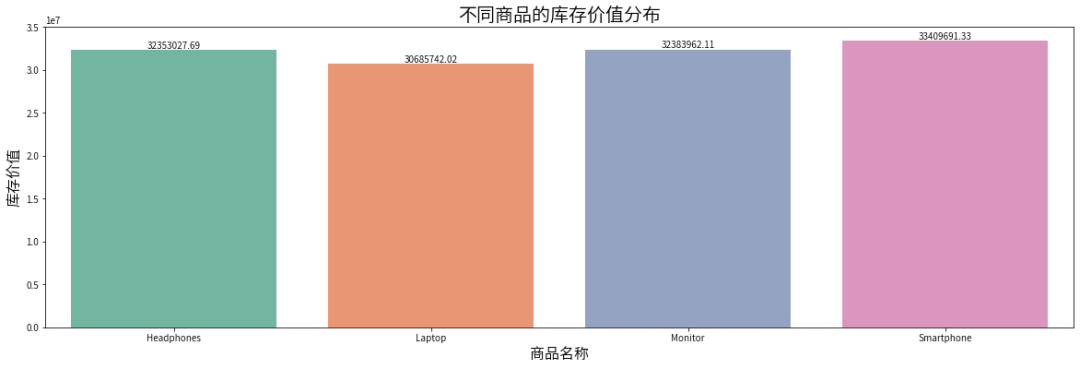
智能手机的库存价值最高,约3341万美元。
笔记本电脑的库存价值最低,约3069万美元。
category_inventory['Inventory Ratio'] = category_inventory['Stock Quantity'] / category_inventory['Stock Quantity'].sum()category_value['Value Ratio'] = category_value['Inventory Value'] / category_value['Inventory Value'].sum()# 合并数据evaluation = pd.merge(category_inventory, category_value, on='Product Name')# 绘制综合评估图plt.figure(figsize=(20, 8))x = np.arange(len(evaluation['Product Name']))width = 0.35ax = plt.subplot()bars1 = ax.bar(x - width/2, evaluation['Inventory Ratio'], width, label='Inventory Ratio')bars2 = ax.bar(x + width/2, evaluation['Value Ratio'], width, label='Value Ratio', alpha=0.7)# 手动添加数值标签for bar in bars1 + bars2:height = bar.get_height()ax.text(bar.get_x() + bar.get_width() / 2., height,f'{height:.3f}', ha='center', va='bottom')# 设置x轴刻度标签ax.set_xticks(x)ax.set_xticklabels(evaluation['Product Name'])plt.title('不同商品的库存分布合理性指标', fontsize=20)plt.xlabel('商品类别', fontsize=16)plt.ylabel('指标值', fontsize=16)plt.legend()plt.show()
输出:
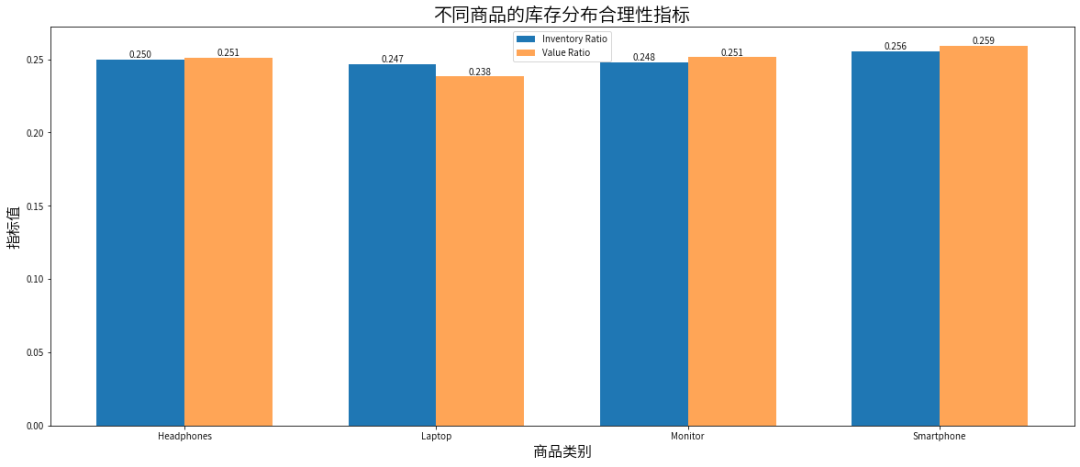
智能手机
Inventory Ratio为0.256,Value Ratio为0.259,这意味着其在库存总量和价值贡献上都占据主导地位。企业需密切监控其市场需求和库存周转情况,以确保库存水平与销售需求相匹配,避免库存积压或缺货。
耳机
Inventory Ratio为0.25,Value Ratio为0.251,这说明耳机的库存分布和价值贡献较为均衡,企业可以维持当前的库存策略,但需关注市场变化,灵活调整库存水平。
显示器
Inventory Ratio为0.248,Value Ratio为0.251,库存分布和价值贡献较为均衡,企业可以继续关注其市场需求和库存周转情况,确保库存的合理性和流动性。
笔记本电脑
Inventory Ratio为0.247,Value Ratio为0.238,库存数量较多,但库存价值相对较低,可能存在库存积压或库存周转率较低的情况,企业需要进一步分析其市场需求和销售情况,以优化库存水平,提高库存周转率。
总结
四个产品的库存结构合理性较高,库存分布和价值贡献在一定程度上是协调的。但智能手机的两个比例都最高,显示其在库存总量和价值贡献上都占据主导地位。
笔记本电脑的库存数量较多但价值贡献相对较低,企业可以进一步分析其市场需求和库存周转情况,以优化库存水平,提高库存效率。此外,企业可以对各产品类别进行更深入的市场需求预测和销售趋势分析,以进一步优化库存结构,确保库存资源的合理分配和高效利用。
篇幅略长,后续内容请看下一篇!
案例来源:
https://www.heywhale.com/mw/project/6809940c7129c4c8a5f1492c
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









