






本文来源公众号“AI新智力”,仅用于学术分享,侵权删,干货满满。
原文链接:AI | 大模型入门(十):RAG vs. KAG
“KAG是什么,与RAG有何不同?”

前文AI新智力 | AI|大模型入门(四):检索增强生成(RAG)_检索增强生成场景-优快云博客提到,相对于微调技术,RAG是大模型定制化或者私有化部署时知识增强方法的最便捷、成本最低的方式,是一种新数据引入大模型的经济高效的方法,它使生成式人工智能技术更广泛地获得和使用。
前文AI新智力 | AI | 大模型入门(九):RAG数据库-优快云博客提到,RAG使用的数据库主要有向量数据库、图数据库、知识图谱、混合架构数据库等。
那么KAG是什么,与RAG有什么不同呢?
KAG是什么
KAG (Knowledge Augmented Generation, 知识增强生成)是基于OpenSPG 引擎和大型语言模型的逻辑推理问答框架,用于构建垂直领域知识库的逻辑推理问答解决方案。
KAG通过直接将结构化知识图或外部知识库融入到大模型体系结构中来增强语言模型的生成能力。
与RAG检索非结构化数据不同,KAG侧重于结构化知识的集成,以提高生成的质量。它基于OpenSPG引擎,解决了传统问答系统的局限性。KAG可以有效克服传统RAG向量相似度计算的歧义性和OpenIE引入的GraphRAG的噪声问题。KAG支持逻辑推理、多跳事实问答等,并且明显优于目前的SOTA方法。
注1:OpenSPG是蚂蚁集团与OpenKG联合推出的基于SPG(Semantic-enhanced Programmable Graph)框架研发的知识图谱引擎。
注2:SOTA(State of the Art)是科技领域描述技术最高水平的术语,指的是最先进的技术或模型。
KAG的目标是在专业领域构建知识增强的大模型服务框架,支持逻辑推理、事实问答等。KAG充分融合了知识图谱(KG)的逻辑性和事实性特点,核心功能有:
-
知识与Chunk互索引结构,以整合更丰富的上下文文本信息
-
利用概念语义推理进行知识对齐,缓解OpenIE引入的噪音问题
-
支持Schema-Constraint知识构建,支持领域专家知识的表示与构建
-
逻辑符号引导的混合推理与检索,实现逻辑推理和多跳推理问答
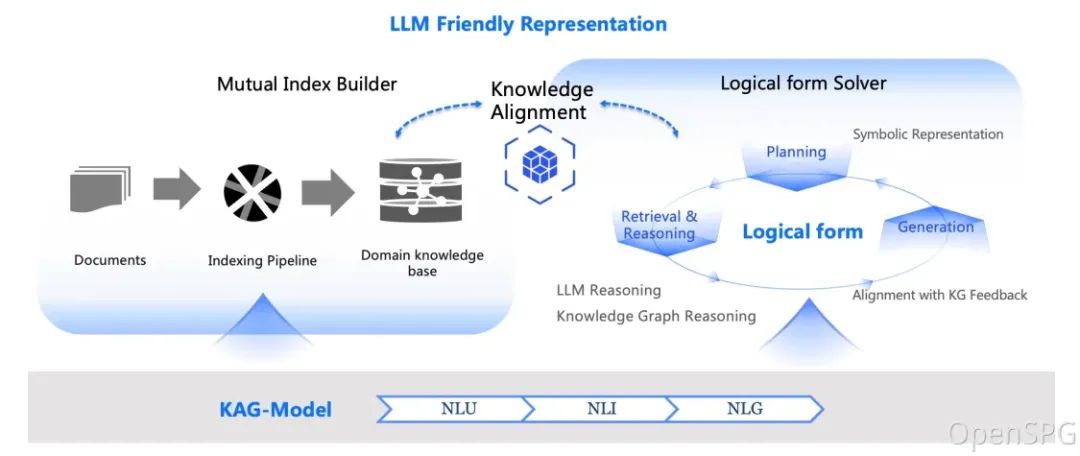
KAG技术架构图
RAG与KAG的区别
RAG和KAG都是最先进的增强生成模型能力的方法,但是它们适用于不同类型的任务。RAG擅长于需要检索和合成动态和非结构化数据的开放域任务。而KAG在需要从知识图谱中获得结构化和事实性信息的场景中更有效。
传统RAG依赖向量检索非结构化文本,虽然随着RAG技术的演进和GraphRAG(知识图谱增强的RAG)技术发展,知识图谱已成为优化RAG系统的重要工具。GraphRAG通过引入结构化知识图谱,构建了双引擎检索机制,通过向量检索实现基于文本语义匹配文档块功能,通过图谱检索通过实体关系网络实现多跳推理,例如,在医疗诊断场景中,查询“头痛伴高血压可能风险”时,GraphRAG会通过图谱中的“头痛→高血压→脑卒中”因果链推理,而非仅依赖文本相似性。
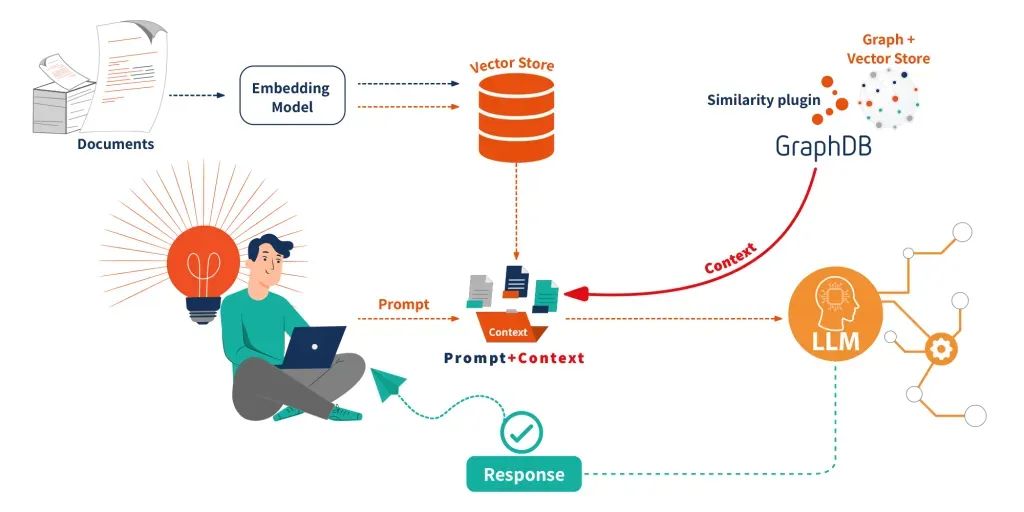
但是,RAG对知识图谱的检索召回率并不是特别理想。而KAG则是专门为知识图谱设计的大模型增强技术,因此他们的主要不同有:
1. 知识图谱的应用方式
RAG或GraphRAG使用一般知识图进行检索,但缺乏深度推理。而KAG构建特定领域的知识图谱,并使用高级推理来解释信息。
2. 推理能力
RAG检索数据,但是很难在复杂查询中组合和使用数据。而KAG采用多跳推理将信息进行连接和综合,从而得到准确的答案。
3.处理复杂查询的能力
对于简单的查询,RAG非常有效,但可能会忽略全局。而KAG则擅长将复杂的、特定领域的查询分解并综合答案。
4. 准确性
GraphRAG提高了精度,但在复杂查询中仍然容易出错。相反,KAG通过结合检索、推理和图对齐提供专业级别的准确性。
关键区别:RAG的检索基于文本相似性,而KAG的推理基于知识图谱的逻辑关系。
技术选型
RAG和KAG两者之间的选择取决于要处理的数据类型和任务性质:
对于需要根据各种文档检索和生成答案的通用应用程序,比如需要快速整合动态信息(如新闻、用户评论)的开放领域任务,例如客服聊天机器人、市场趋势分析等,RAG通常是最佳选择。
然而,对于需要基于结构化知识的一致的、基于事实的答案的任务,需严格逻辑和事实验证的专业领域(如法律条文引用、医疗诊断),或涉及多步推理的复杂问题(如“头痛+高血压→脑卒中风险”),那么KAG则可以提供更可靠的方法。
未来趋势:从工具到基础设施
随着大模型应用场景的多元化,对大模型定制化的需求愈发强烈,定制化也是大模型落地应用的必要前提。因此,需要构建一种新型多模数据库,将向量库、图库、关系库进行统一管理,消除现在的割裂状态,实现各类型数据的统一存储,实现查询使用简化操作,同时实现自主知识更新的功能,例如通过冲突检测自动修正知识图谱,实现多模态融合,将图像、视频等非文本数据纳入知识图谱。这种新型多模数据库将是未来大模型应用落地的重要的不可或缺的新型基础设施。
未来,随着多模数据库和自主更新技术的发展,RAG与KAG的边界将进一步消融,推动AI从“信息检索”向“认知理解”进行跃迁。
参考文献:
1. KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation (arXiv:2409.13731)
2. OpenSPG:https://github.com/OpenSPG
3. https://www.plainconcepts.com/rag-vs-kag/
4. https://medium.com/@aaron941001/from-rag-to-kag-a-revolution-in-knowledge-augmented-generation-4bc4196b247c
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 2080
2080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









