




本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:FastSAM:比SAM快50倍的零样本图像分割模型解析
介绍
图像分割是计算机视觉中的一项流行任务,其目标是将输入图像划分为多个区域,其中每个区域代表一个单独的对象。
过去的几种经典方法涉及采用模型主干(例如 U-Net)并在专门的数据集上对其进行微调。虽然微调效果很好,但 GPT-2 和 GPT-3 的出现促使机器学习社区逐渐将重点转向零样本学习解决方案的开发。
零样本学习是指模型在没有明确接收任何训练示例的情况下执行任务的能力。
零样本概念通过允许跳过微调阶段发挥着重要作用,希望模型足够智能,可以解决移动中的任何任务。
在计算机视觉的背景下,Meta 在 2023 年发布了广为人知的通用“Segment Anything Model”(SAM),它使分割任务能够以零样本的方式以不错的质量执行。

虽然SAM的大规模结果令人印象深刻,但几个月后,中国科学院图像与视频分析(CASIA IVA)小组发布了FastSAM模型。正如形容词“快速”所暗示的那样,FastSAM 通过将推理过程加速多达 50 倍来解决 SAM 的速度限制,同时保持高分割质量。
在本文中,我们将探讨 FastSAM 架构、可能的推理选项,并研究与标准 SAM 模型相比,是什么让它“快速”。此外,我们将看一个代码示例来帮助巩固我们的理解。
作为先决条件,强烈建议您熟悉计算机视觉的基础知识、YOLO 模型,并了解分割任务的目标。
结构
FastSAM 中的推理过程分两步进行:
-
-
全实例分段。 目标是为图像中的所有对象生成分割蒙版。
-
提示引导式选择。 在获得所有可能的掩码后,提示引导选择返回与输入提示相对应的图像区域。
-
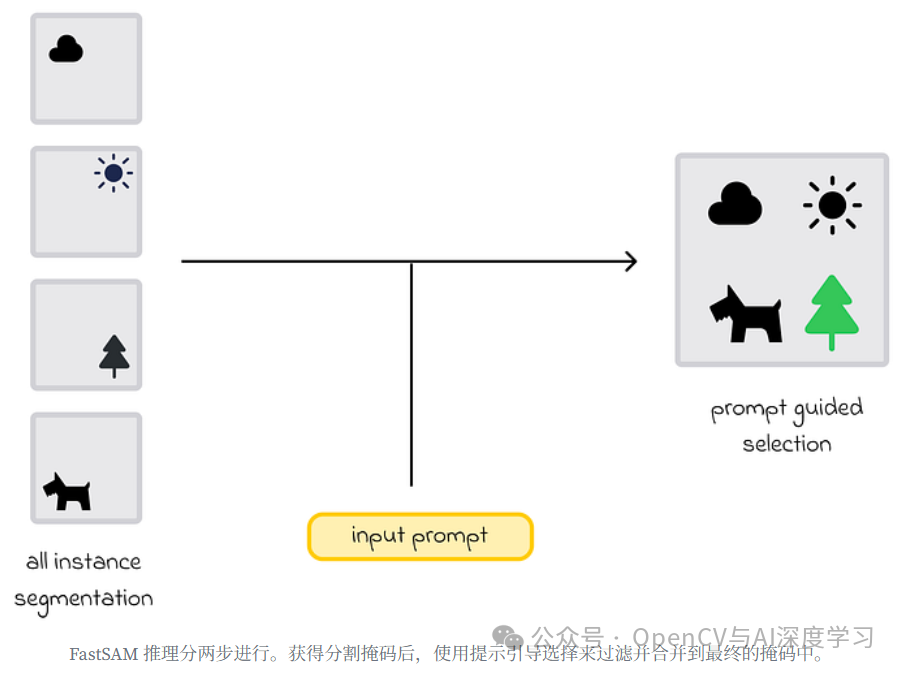
让我们从所有实例分割开始。
所有实例分割
在目视检查架构之前,让我们参考原始论文:
“FastSAM 架构基于 YOLOv8-seg -- 一种配备实例分割分支的对象检测器,它利用了 YOLACT 方法” — Fast Segment Anything 论文
https://arxiv.org/pdf/2306.12156对于那些不熟悉 YOLOv8-seg 和 YOLACT 的人来说,这个定义可能看起来很复杂。无论如何,为了更好地阐明这两个模型背后的含义,我将提供一个关于它们是什么以及如何使用它们的简单直觉。
YOLACT(你只看效率Ts)
YOLACT 是一种专注于高速检测的实时实例分割卷积模型,受 YOLO 模型的启发,实现了与 Mask R-CNN 模型相当的性能。
YOLACT 由两个主要模块(分支)组成:
-
-
原型分支。 YOLACT 创建了一组称为原型的分割掩码。
-
预测分支。 YOLACT 通过预测边界框来执行对象检测,然后估计掩码系数,这告诉模型如何线性组合原型以为每个对象创建最终掩码。
-
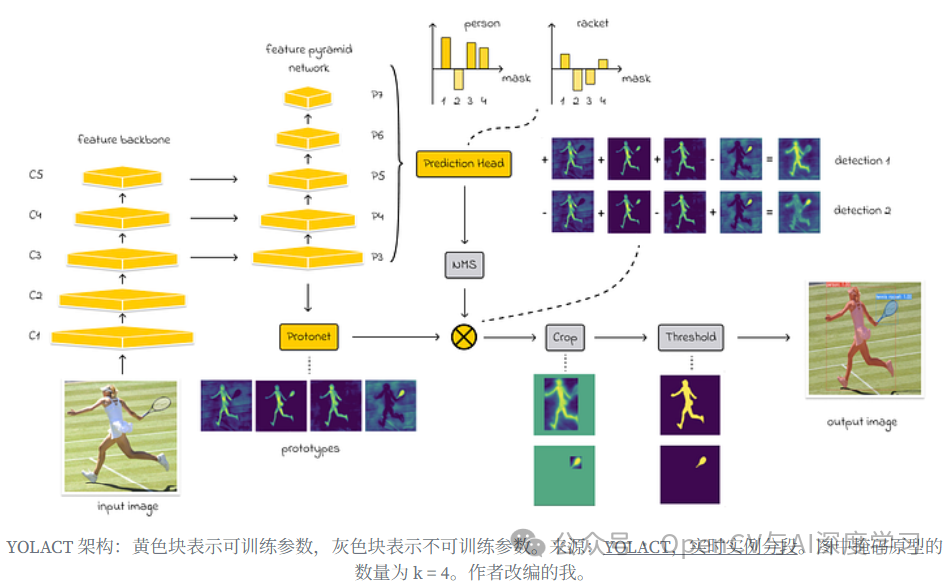
为了从图像中提取初始特征,YOLACT 使用 ResNet,然后使用特征金字塔网络 (FPN) 来获取多尺度特征。每个 P 级(如图所示)使用卷积处理不同大小的特征(例如,P3 包含最小的特征,而 P7 捕获更高级别的图像特征)。这种方法有助于 YOLACT 考虑不同规模的对象。
YOLOv8-seg
YOLOv8-seg 是一个基于 YOLACT 的模型,在原型方面采用了相同的原则。它还有两个头:
-
-
检测头。 用于预测边界框和类。
-
分割头。 用于生成掩码并组合它们。
-
主要区别在于,YOLOv8-seg 使用 YOLO 主干架构,而不是 YOLACT 中使用的 ResNet 主干和 FPN。这使得YOLOv8-seg在推理过程中更轻、更快。
YOLACT 和 YOLOv8-seg 都使用默认的原型数量 k = 32,这是一个可调的超参数。在大多数情况下,这在速度和分段性能之间提供了良好的权衡。
在这两个模型中,对于每个检测到的对象,都会预测大小为 k = 32 的向量,表示掩码原型的权重。然后使用这些权重线性组合原型,为对象生成最终蒙版。
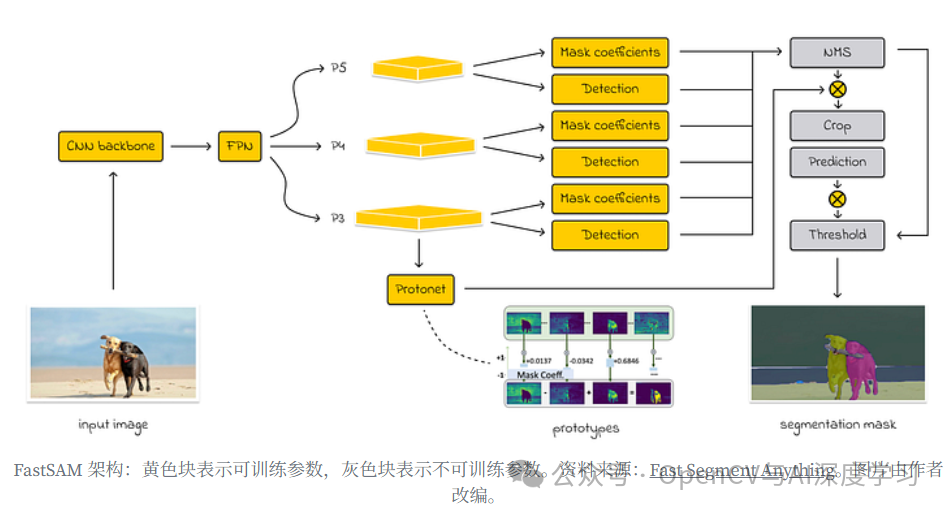
FastSAM 架构
FastSAM 的架构基于 YOLOv8-seg,但也包含一个 FPN,类似于 YOLACT。它包括检测头和分割头,有 k = 32 个原型。然而,由于 FastSAM 对图像中所有可能的对象进行分割,因此其工作流程与 YOLOv8-seg 和 YOLACT 的工作流程不同:
首先,FastSAM 通过生成 k = 32 个图像掩码来执行分割。
然后将这些掩码组合起来以生成最终的分割掩码。
在后处理过程中,FastSAM 会提取区域、计算边界框并对每个对象进行实例分割。
注意
虽然论文没有提到后处理的细节,但可以观察到,官方的 FastSAM GitHub 仓库在预测阶段使用了 OpenCV 的 cv2.findContours() 方法。
def _get_bbox_from_mask(self, mask):mask = mask.astype(np.uint8)contours, hierarchy = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)x1, y1, w, h = cv2.boundingRect(contours[0])x2, y2 = x1 + w, y1 + hif len(contours) > 1:for b in contours:x_t, y_t, w_t, h_t = cv2.boundingRect(b)# Merge multiple bounding boxes into one.x1 = min(x1, x_t)y1 = min(y1, y_t)x2 = max(x2, x_t + w_t)y2 = max(y2, y_t + h_t)h = y2 - y1w = x2 - x1return [x1, y1, x2, y2]
在实践中,有几种方法可以从最终分割掩码中提取实例掩码。一些示例包括轮廓检测(用于 FastSAM)和连接组件分析(cv2.connectedComponents())。
训 练
FastSAM 研究人员使用与 SAM 开发人员相同的 SA-1B 数据集,但仅针对 2% 的数据训练了 CNN 检测器。尽管如此,CNN 检测器仍实现了与原始 SAM 相当的性能,同时需要更少的分割资源。因此,FastSAM 中的推理速度提高了 50 倍!
作为参考,SA-1B 由 1100 万张不同的图像和 11 亿个高质量分割掩码组成。
是什么让 FastSAM 比 SAM 更快?SAM 使用视觉转换器 (ViT) 架构,该架构以其繁重的计算要求而闻名。相比之下,FastSAM 使用轻得多的 CNN 进行分割。
提示引导式选择
“分割任何任务”涉及为给定提示生成一个分割掩码,该掩码可以用不同的形式表示。

点提示
在获得图像的多个原型后,可以使用点提示来指示感兴趣的对象位于(或不)在图像的特定区域中。因此,指定的点会影响原型掩模的系数。
与 SAM 类似,FastSAM 允许选择多个点并指定它们属于前景还是背景。如果与对象对应的前景点出现在多个蒙版中,则可以使用背景点过滤掉不相关的蒙版。
但是,如果过滤后仍有多个遮罩满足点提示,则应用遮罩合并以获得对象的最终遮罩。
此外,作者应用形态学运算符来平滑最终的掩模形状并消除小伪影和噪声。
框提示
框提示涉及选择其边界框与提示中指定的边界框具有最高交集的并集 (IoU) 交集的掩码。
文本提示
同样,对于文本提示,选择最符合文本描述的掩码。为此,使用了 CLIP 模型:
-
-
计算文本提示和 k = 32 原型掩码的嵌入。
-
然后计算文本嵌入和原型之间的相似性。相似度最高的原型将进行后处理并返回。
-
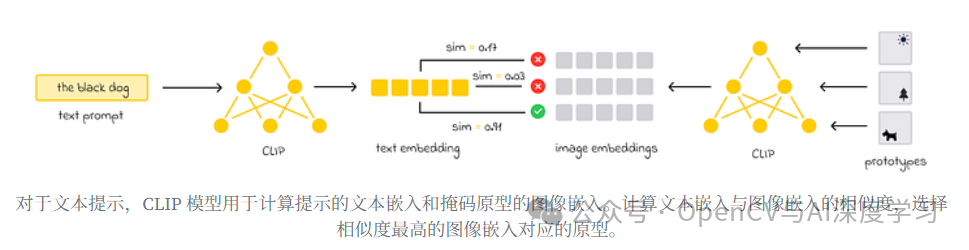
通常,对于大多数分割模型,提示通常在原型级别应用。
FastSAM 存储库
以下是 FastSAM 官方存储库的链接,其中包括清晰的 README.md 文件和文档。
GitHub - CASIA-IVA-Lab/FastSAM:快速分割任何内容
https://github.com/CASIA-IVA-Lab/FastSAM如果您计划使用 Raspberry Pi 并希望在其上运行 FastSAM 模型,请务必查看 GitHub 存储库:Hailo-Application-Code-Examples。它包含在边缘设备上启动 FastSAM 所需的所有代码和脚本。
结论
在本文中,我们研究了 FastSAM--SAM 的改进版本。FastSAM 结合了 YOLACT 和 YOLOv8-seg 模型的最佳实践,保持了高分割质量,同时显着提高了预测速度,与原始 SAM 相比,推理速度提高了几十倍。
将提示与 FastSAM 一起使用的能力提供了一种灵活的方法来检索感兴趣对象的分割掩码。此外,已经表明,将提示引导选择与所有实例分割解耦可以降低复杂性。
以下是一些不同提示的 FastSAM 使用示例,直观地表明它仍然保留了 SAM 的高分割质量:


THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1114
1114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









