






本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:小白学RAG:RAG进阶思路与研究综述
本文来分享下最新的RAG技术总结综述包含了2020年至2025年5月期间发表的高被引研究。
https://arxiv.org/pdf/2508.06401
A Systematic Literature Review of Retrieval-Augmented Generation: Techniques, Metrics, and Challenges
RAG关键部分
RAG技术的关键部分包括检索机制、数据存储、预处理、编码、训练和生成等方面。
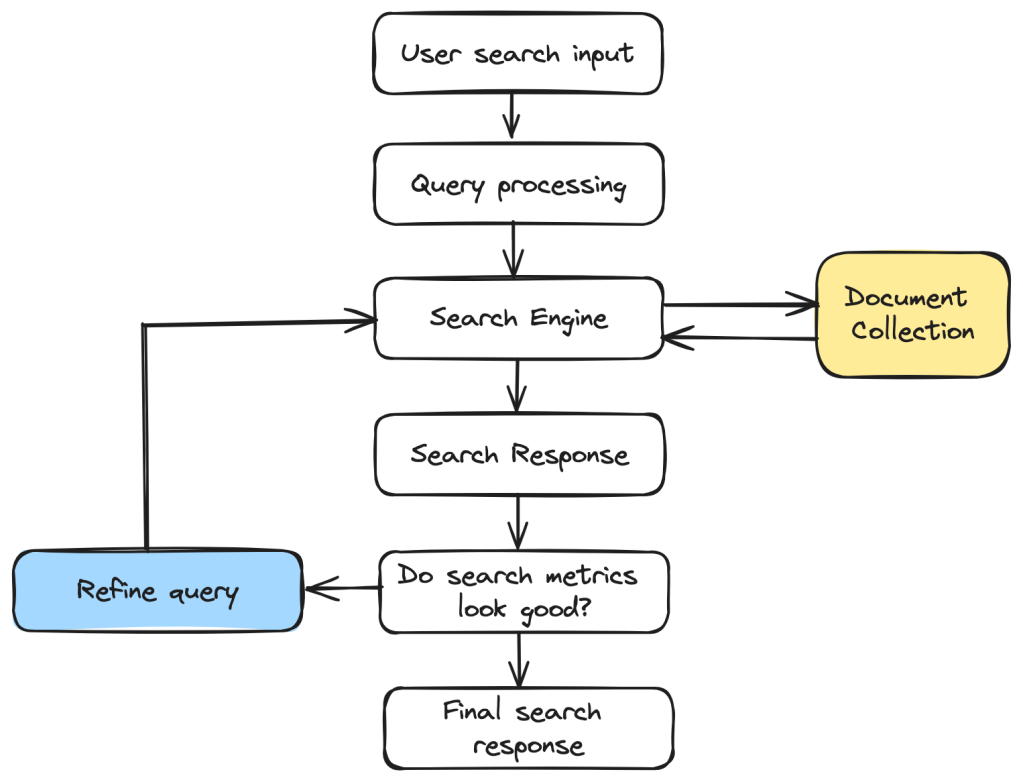
检索机制(Retrieval mechanism)
-
稀疏检索方法(Sparse term-based methods):如BM25,它们高效且可解释,但难以捕捉语义信息。
-
稠密检索器(Dense retrievers):如DPR,利用双编码器网络将查询和文档映射到连续向量空间,通过最大内积搜索(MIPS)进行语义匹配。
-
混合方法(Hybrid approaches):结合了稀疏方法和稠密方法,以平衡召回率和准确性。
-
编码器-解码器查询生成器(Encoder–decoder query generators):将复杂的查询重写为独立的搜索查询,以提高召回率。
-
重排模块(Reclassification modules):对初始检索结果进行重新排序,以消除噪音并更好地满足生成任务的需求。
-
图检索方法(Graph retrieval methods):通过知识图谱提取相关子图或路径,进行多跳推理。
-
迭代框架(Iterative frameworks):将检索和生成过程交错进行,通过反馈循环逐步完善查询。
-
专用检索器(Specialised retrievers):针对特定数据类型(如代码、图像、临床报告)设计的检索器。
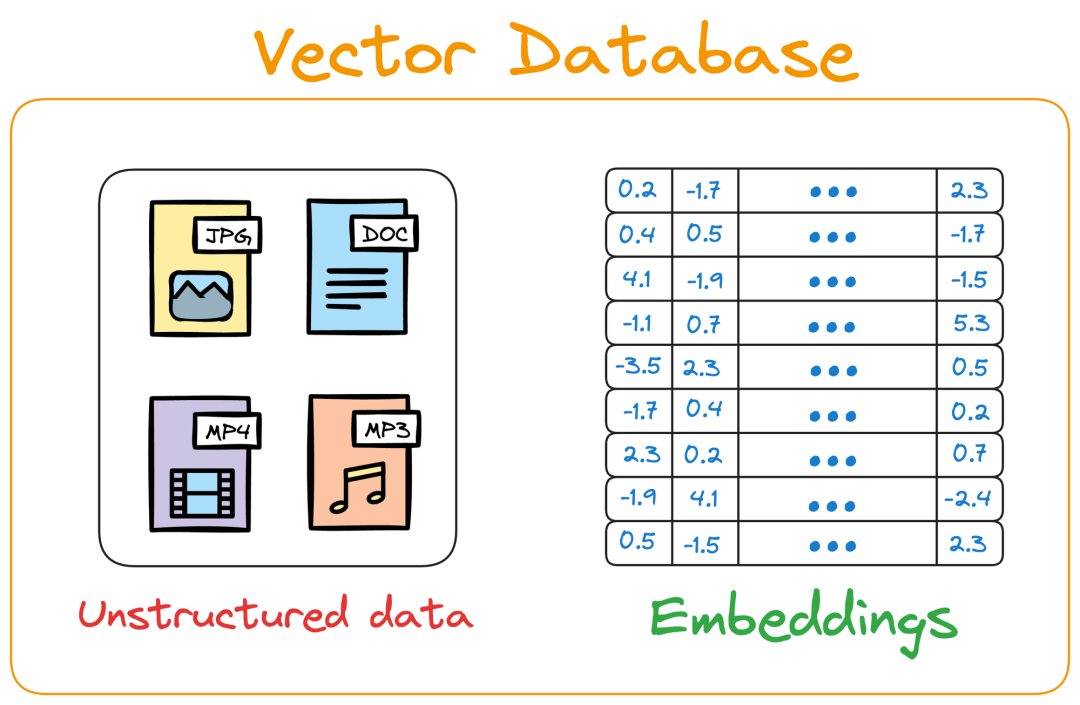
向量数据库(Vector Database)
-
核心索引技术:如HNSW图和FAISS索引,以在生产环境中实现亚毫秒级的性能。
-
分布式和动态环境:研究人员已将索引方法扩展到GPU分片索引和云原生服务,以处理海量向量。
-
领域特定向量库:针对代码、生物医学、金融等特定领域定制的向量存储。
-
商业化服务:如Pinecone、Weaviate和Qdrant,它们简化了部署,但也带来了潜在的供应商锁定和成本问题。
文档分块(Document chunking)

-
静态固定长度分割(Static fixed-length segmentation):简单易用,但可能破坏语义连贯性。
-
语义边界感知分割(Semantic boundary–aware splitting):根据句子、段落或章节等固有结构进行分块,以保持语义完整性,但增加了预处理复杂性。
-
领域和模态特定分块(Domain and modality specific chunking):针对不同类型数据(如源代码、知识图谱、法律文件、多模态输入)定制的分块策略。
-
自适应动态分块(Adaptive dynamic chunking):根据查询特征或检索性能动态调整块大小和重叠,旨在结合上述方法的优点,但仍处于实验阶段。
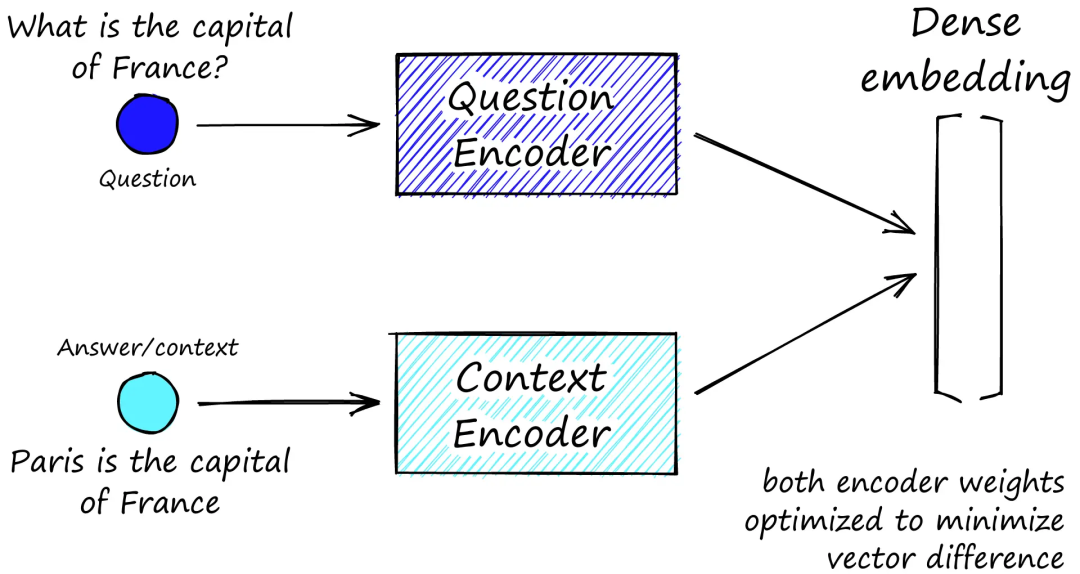
向量编码器(Vector encoders)
-
稀疏编码器(Sparse encoders):如TF-IDF和BM25,计算效率高但语义建模能力较弱。
-
稠密编码器(Dense encoders):基于深度学习模型,能捕捉上下文和语义细微之处。
-
混合和多模态编码器(Hybrid & multi-modal encoders):融合稀疏和稠密信号,或联合编码多种模态(如文本和图像),以处理异构数据源。
训练(Training)
-
联合端到端训练(Joint end-to-end training):同时优化检索器和生成器,以实现最佳对齐,但计算成本高。
-
模块化两阶段方法(Modular two-stage approaches):将检索器和生成器分开训练,提高了稳定性,但可能导致全局协调不佳。
-
参数高效微调(PEFT)和指令微调(instruction tuning):只更新模型参数的一小部分,大大降低了计算资源需求。
-
专用训练目标(specialized training objectives):使用对比损失、自批判序列训练等方法来提高任务特定指标。
-
领域和模态特定适配(domain and modality specific adaptation):为特定领域(如代码、生物医学)定制训练管道。
生成模型(Generation Model)
-
早期模型:如RAG、Fusion-in-Decoder,通过跨注意力机制融合检索到的信息。
-
自回归模型:如RETRO,将片段级别的检索与自回归解码交错进行。
-
最新进展:如Self-RAG,实现了对潜在检索信号的自监督对齐。
-
专业化和多模态应用:将RAG扩展到生物医学、法律、代码生成和视觉问答等特定领域。
生成模型家族(Generative Model Families)
-
编码器-解码器模型(Encoder–decoder models):如Google的Flan-T5、Meta AI的BART,擅长多段落融合。
-
仅解码器模型(Decoder-only families):如OpenAI的GPT系列、Meta的Llama系列、Mistral AI的模型,它们通过token插入或适配器进行检索,更适合对话场景。
创新的RAG方法
与标准RAG(使用DPR + seq-to-seq,一次性检索并拼接top-k文档)相比,创新的RAG方法和途径主要更好的性能,因此有更多的步骤。
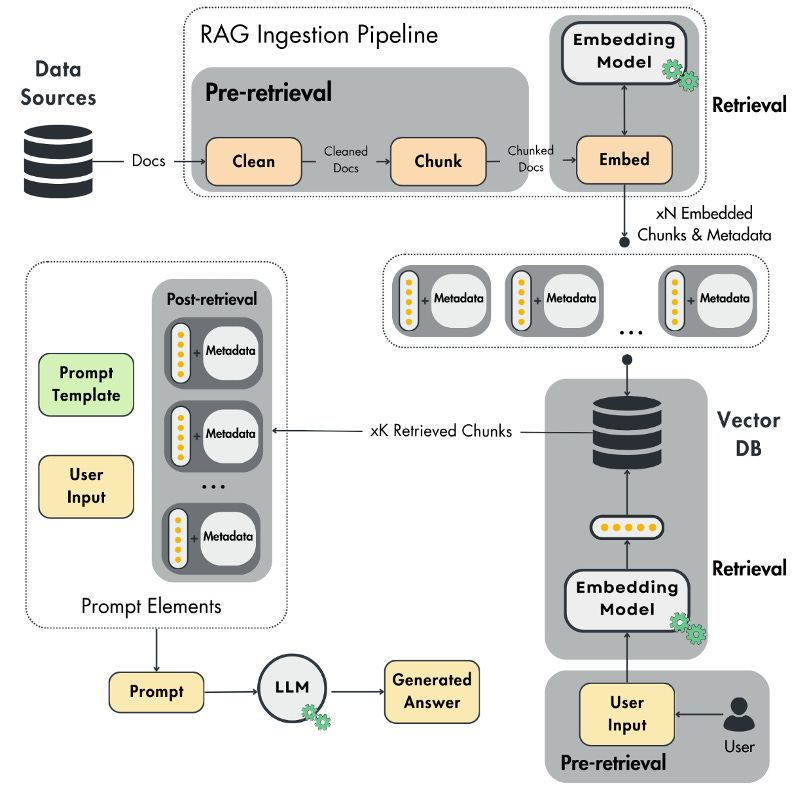
一次性的管道向模块化、策略驱动的架构演进。这种新范式通过混合索引、结构化检索和不确定性触发等方式,在不增加token负担的情况下提高了召回率。闭环、轻量级验证器和记忆的引入,使RAG成为一个交互式的“研究伙伴”。
预检索与后检索阶段(Pre-retrieval & Post-retrieval Stages)
-
预检索(Pre-retrieval):在喂给索引之前,现在的方法更注重数据的准备工作。
-
结构化分块:不再简单地按固定长度切割文档,而是根据标题、表格、叙事块等结构进行分块,以保持语义完整性。
-
内容丰富化:在分块的同时,用GPT生成关键词和微型摘要,以缩小搜索范围,提高效率。
-
语料库管理:对语料库进行精心筛选,例如只保留指导性句子,以减少不必要的输出和幻觉。
-
“长单元”处理:将整个PDF或相关联的页面作为一个“长单元”进行处理,大大减小索引规模。
-
防御入口点:通过模糊代码ID、归一化嵌入和毒药过滤器等方式,增强检索器的安全性。
-
-
后检索(Post-retrieval):在检索到文档后,对其进行处理以优化传递给生成模型的上下文。
-
重排(Re-rank):使用诸如Reciprocal Rank Fusion(倒数排名融合)或自回归排序器等技术,重新排序检索到的文档,将最相关的文档放在首位。
-
精简(Trim the fat):只选择相关的句子、提供“提示”或快速摘要,以减少token数量,同时保持事实准确性。
-
效用决定:使用轻量级的评分器来决定是保留、丢弃还是重复某个文档,以适应下游生成任务。
-
噪音作为正则化:故意插入一些不相关的段落作为正则化项,让模型学会忽略噪音,从而提高事实准确性。
-
早期验证:使用小型“批评”模型在早期就标记出问题是出在检索还是生成上,并只触发必要的修复。
-
提示与查询策略(Prompting & Query Strategies)
-
查询重写和扩展:让大型语言模型(LLM)扩展或重写用户的原始问题,生成多个查询,并将所有检索到的证据进行下游融合。
-
不确定性触发:像FLARE和RIND+QFS这样的系统,只在模型对某个token的不确定性很高时才触发检索,避免了不必要的索引调用。
-
结构化任务:使用JSON、实体标签或混合文本-图模板等包装器来组织证据,强制模型输出特定格式,并减轻其认知负担。
-
检索增强上下文学习:在构建提示时,插入与查询相似的问答对,以最小的token成本提高准确性。
-
ReAct风格提示:模型可以计划工具调用(Thought, Action, Observation),运行检索工具,然后根据结果进行修正。
-
思维图(Graph-of-Thought):将问题分解为子问题,每个子问题都有自己的检索步骤,然后将答案整合起来。
混合与专用检索器(Hybrid and Specialised Retrievers)
-
分数级融合:结合词法(如BM25)和多个稠密检索器的分数,通过倒数排名融合等方法,在不进行任务微调的情况下,持续优于单个索引。
-
自适应混合检索:系统可以学习如何根据输入,自适应地决定何时以及如何混合不同的检索信号。例如,对词法查询避开稠密检索,以降低延迟。
-
利用结构信息:在知识图谱问答中,首先使用关键词匹配检索实体邻居,再用向量相似度进行精炼。在代码智能中,结合词法重叠和稠密检索来捕捉语法和语义。
-
多模态融合:使用CLIP相似度来检索图像,然后用文本编码器来检索精确的文本段落,以支持视觉问答。
结构感知与基于图的RAG(Structure-aware & Graph-based RAG)
-
图索引:将文档、标题或代码转化为节点和边,构建连接子图,在检索时就能编码多跳上下文。
-
图-token对齐:通过软提示投影或将文档嵌入作为潜在token的方式,让LLM能够处理图的语义。
-
自动化图创建:使用LLM自动从文档中提取实体和关系,并维护混合了关键词和向量的图结构。
-
解释性增强:由于模型可以引用图中的路径或节点标识符,因此答案的可信度和可解释性大大提高。
迭代与主动检索循环(Iterative & Active Retrieval Loops)
-
不确定性触发:当LLM在生成过程中检测到高不确定性时,会暂停生成并触发一次有针对性的检索,例如FLARE模型。
-
自我反思(SELF-RAG):模型使用反思token来触发检索、评估证据并批判自己的输出,实现了段落级别的控制。
-
逐步精炼:例如CHAIN-OF-NOTE(CON)框架,LLM会为每个检索到的文档写下“阅读笔记”,在综合答案之前暴露文档的可靠性。
-
验证驱动循环:如果一个验证器标记出检索或生成错误,管道会重新检索或重新生成答案,直到验证器满意为止,从而形成闭环修正。
-
智能体管道:将检索、重排、精炼和生成等每个阶段作为独立的、可编程的工具,模型可以自主规划并调用这些工具。
记忆增强型RAG(Memory-augmented RAG)
传统的RAG是无状态的,每轮查询都独立进行。记忆增强型RAG通过引入持久化记忆,实现了个性化和长时程上下文。
-
短时程对话缓冲区:在对话过程中保留最近的聊天记录,例如MoodleBot和LangChain的ConversationBufferMemory,用于增强后续问题的连贯性。
-
持久化用户记忆:为每个用户维护一个独立的记忆库,存储长期文档、短时程信号或最近的查询。例如LiVersa的肝病助手通过分离存储不同类型的信息,减少了幻觉并缩短了提示长度。
-
模型内部记忆:在模型内部建立键值存储(key-value store),在推理时用于存储和检索内部状态或外部信息。例如RAM和SelfMem。
智能体与多工具管道(Agentic & Multi-tool Pipelines)
-
工具箱:智能体暴露了一系列异构能力,如混合检索器、图遍历、记忆存储和领域插件。
-
控制器:智能体通过静态图、动态规划(例如ReAct风格的“Thought, Action, Observation”循环)或学习型控制器来决定下一步行动。
-
记忆作为核心:记忆不再是事后添加的功能,而是与检索器同等重要的工具,可以记录每一次的感知-思考-行动,以辅助复杂的规划任务。
效率与压缩(Efficiency & Compression)
-
文档压缩:将整个文档或图谱分支压缩成单个投影token,大大减少上下文长度和GPU内存。
-
索引优化:使用异步重编码器来在线刷新索引,将大型PDF视为一个“长检索单元”来缩小索引规模。
-
计算优化:PipeRAG在GPU解码时并行从CPU加载文档,从而减少了端到端延迟。RAGCache则通过猜测和缓存可复用文档,进一步降低了延迟和成本。
-
自适应检索频率:根据质量需求或预设的延迟预算,动态调整检索的频率。
模态扩展(Modality Expansion)
-
统一多模态骨干:MuRAG等系统使图像和文本共享相同的嵌入空间,让模型能够同时检索和处理多种模态的信息。
-
编排框架:LangChain等工具允许工程师通过简单的配置,接入CLIP检索器、Whisper转录器或表格解析器,使单个智能体能够处理多样化的数据类型。
-
精准引用:在临床成像等领域,系统能够将生成的描述与图像中的特定区域联系起来,增强了答案的可追溯性。
评估 RAG 有效性的常用指标
评估检索增强生成(RAG)系统的有效性,需要一套能够同时衡量检索器和生成器性能的指标。这些指标通常分为三大类:自动化指标、人工评估指标和新兴的“LLM即评判者”指标。
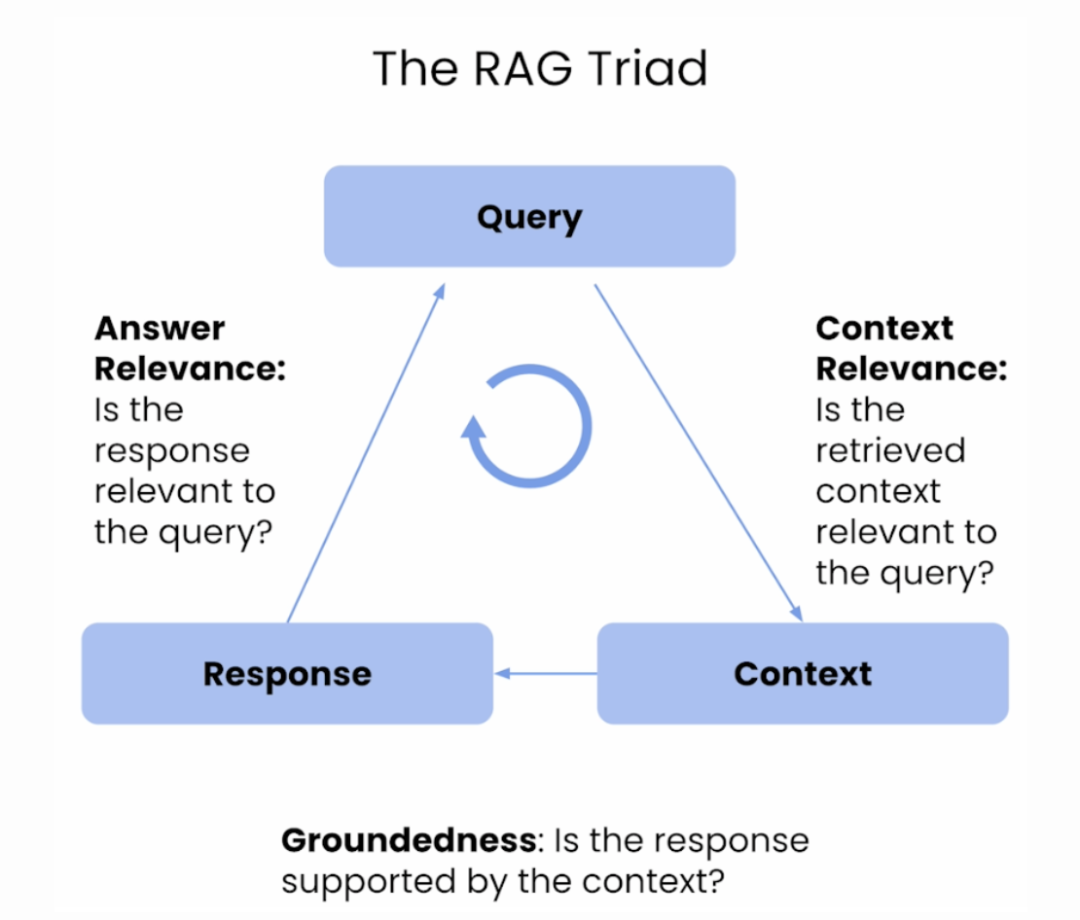
评估总览
-
自动化指标(Automated metrics):最常用,但主要关注表面重叠或检索成功,难以捕捉深层语义。其中,准确率(accuracy)、EM(精确匹配)**和**F1分数最为常见。
-
人工评估指标(Human-judged metrics):较少使用,但对于评估事实性、流畅性和用户满意度至关重要,能提供更深入的定性洞察。
-
LLM即评判者(LLM-as-judge):新兴方法,使用强大的LLM(如GPT-4)来对生成结果进行打分。这种方法结合了自动化和人工评估的优点,但存在模型偏见和提示敏感性的风险。
全面的RAG评估报告,通常会结合使用至少一个检索或重叠指标(如 recall@k、EM/F1)、一个基于嵌入的语义指标(如 BERTScore),以及一种人工或LLM评估方法。
自动化生成指标
基于分类的指标
-
准确率(Accuracy):衡量正确响应数占总输出数的比例,直接评估答案的正确性,但忽略了部分匹配。
-
精确匹配(EM - Exact Match):一个更严格的二元指标,要求输出与参考答案逐字符完全一致。适用于需要精确无误的任务,如代码生成或事实检索。
基于重叠的 N-gram 指标
-
F1分数:衡量生成输出和参考答案在token层面的重叠程度,是精确率和召回率的调和平均值。它能为部分正确的匹配提供分数,常用于问答和摘要任务。 F1=2×Precision+RecallPrecision×Recall
-
BLEU (Bilingual Evaluation Understudy):衡量生成文本与参考文本的 n-gram 精确率,并施加简洁惩罚(brevity penalty)来防止过短的回答。
-
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):主要关注n-gram 召回率,ROUGE-L 变体则衡量最长公共子序列(LCS)。常用于评估摘要任务。
-
METEOR (Metric for Evaluation of Translation with Explicit ORdering):在 n-gram 重叠的基础上,加入了词干提取、同义词匹配等功能,与人类判断的相关性通常高于BLEU和ROUGE。
基于嵌入的指标
-
BERTScore:通过比较生成文本和参考文本的上下文 token 嵌入来衡量语义相似性。相比基于 n-gram 重叠的指标,它能更好地捕捉同义词和释义。
概率和专业指标
-
困惑度(Perplexity - PPL):衡量模型对生成序列的不确定性。较低的困惑度表明模型预测下一个词时更有信心,常用于评估语言的流畅性和连贯性。
-
其他专业指标:
-
Self-BLEU:通过计算生成结果与自身其他结果的BLEU分数来量化多样性。
-
支持度(Support):标记生成结果中的每个声明是否完全、部分或不被检索到的证据所支持,以确保事实性。
-
Rare F1 / PKF1:用于评估模型在特定任务(如低频词或知识恢复)上的表现。
-
自动化检索指标
基于集合的指标
-
文档检索准确率(Document Retrieval Accuracy):衡量有多少比例的查询,其所有检索到的文档都是相关的。
-
Precision@k(P@k)和 Recall@k(R@k):
-
Precision@k:在前 k 个检索结果中,相关文档所占的比例,衡量检索器避免无关项的能力。
-
Recall@k:所有相关文档中,有多少比例出现在前 k 个结果中,衡量检索的完整性。
-
-
F1@k:
Precision@k和Recall@k的调和平均数,提供一个平衡的综合分数。 F1@k=2×Precision@k+Recall@kPrecision@k×Recall@k
基于排名的指标
-
平均精度均值(MAP@k - Mean Average Precision):奖励那些将相关文档排在前面的检索结果,对排序质量要求较高。
-
平均倒数排名(MRR@k - Mean Reciprocal Rank):仅关注第一个相关文档的排名位置,特别适用于问答等对第一个结果至关重要的任务。
-
归一化折损累积增益(nDCG@k - Normalized Discounted Cumulative Gain):能处理分级相关性,通过位置对文档增益进行对数折损,再进行归一化。
基于命中的指标
-
Hit@K:一个二元指标,表示前 K 个检索结果中是否至少存在一个相关文档。
-
**Hit Success Ratio (HSR)**:衡量需要外部知识的查询中,检索器提供了支持证据的比例。
其他自动化指标
计算效率
-
延迟(Latency):衡量从文档检索到文本生成的总时间,通常分为检索时间、决策时间和生成时间。
-
响应时间(Response Time):衡量从提交查询到输出第一个token的端到端延迟,这对于实时应用至关重要。
鲁棒性与错误处理
-
幻觉率(Hallucination Rate):追踪生成内容中虚假信息或捏造内容的频率。
-
拒绝率(Rejection Rate):衡量系统在知识库不足时拒绝回答的能力,以避免产生幻觉。
-
成功率(Success Rate):评估系统抵御恶意提示(jailbreak)攻击的能力,反映其安全性。
上下文偏见
-
上下文偏见(Contextual Bias):衡量模型在误导性上下文下,采纳错误假设的倾向。这在检索到有噪音的文档时尤为重要。
图像和代码特定指标
-
CIDEr & SPICE:用于评估图像描述的质量,分别衡量文本共识和语义命题的忠实性。
-
编辑相似度(Edit Similarity - ES):通过计算代码片段的编辑距离来衡量代码相似性。
-
Pass@k:衡量代码生成在 k 次尝试中通过自动化测试的比例。
-
CodeBLEU:在BLEU的基础上,加入了抽象语法树(AST)和数据流的比较,能捕捉代码的语法和语义正确性。
人工评估指标
准确性与正确性
-
正确性与准确性(Correctness & Accuracy):人工评估者判断生成内容是否与专家验证的答案或权威来源相符。
-
相关性(Relevance):评估检索到的上下文或生成文本与用户查询的主题相关性、语法连贯性和信息适当性。
幻觉与接地性
-
幻觉与接地性(Hallucination & Groundedness):人工标注者将幻觉分为外部幻觉(完全捏造)、内部幻觉(对输入信息错误合成)或误导性引用,以量化模型捏造事实的倾向。
事实正确性与一致性
-
事实正确性与一致性(Factual Correctness & Consistency):人工判断长篇回答是否保持内部一致性,避免矛盾,这能捕捉自动化指标难以发现的细微语义错误。
全面性与质量
-
全面性(Comprehensiveness):评估生成文本是否涵盖了查询的所有方面。
-
质量(Quality):使用李克特量表(如1-5分制)对相关性、连贯性和无错性等进行综合打分。
用户中心指标
-
用户满意度(User Satisfaction):通过调查问卷衡量用户对系统的感知有用性和清晰度。
-
系统可用性(System Usability - SUS):标准化的问卷来评估准确性、清晰度和易用性。
标注协议和可靠性:大多数研究使用多名人工标注者,并采用李克特量表、二元判断或比较性判断。为了确保一致性,需要定义清晰的标注指南,并衡量标注者间一致性(interannotator agreement),如Cohen's κ值。
检索增强生成(RAG)技术的关键挑战
尽管 RAG 技术取得了显著进展,但在实际应用中仍面临一系列顽固的挑战,这些挑战限制了其性能、可扩展性和适应性。
1. 计算和资源权衡(Computational and Resource Trade-offs)
-
延迟和内存:动态查询重写、迭代式检索和扩展上下文等创新方法虽然提高了相关性,但每次额外的操作都会增加延迟和内存占用。
-
推理瓶颈:RAG管道中,通常先进行CPU密集型的向量搜索,再进行GPU密集型的解码,导致一个处理器空闲而另一个工作。尽管像PipeRAG这样的调度器试图通过重叠计算来隐藏延迟,但仍需要精细的配置,并且对语料库大小敏感。
-
索引权衡:近似最近邻(ANN)索引可以减少检索延迟,但会牺牲召回率;而穷举搜索则正好相反。这要求系统需要自适应调度策略,以平衡ANN深度、推测解码和设备利用率。
2. 噪音、异构性和多模态对齐(Noise, Heterogeneity, and Multimodal Alignment)
-
数据输入噪音:RAG管道的输入通常是嘈杂和异构的。例如,视觉-语言转换器会压缩复杂的场景,损失空间线索;代码-属性图会随着项目增大而急剧膨胀,导致激进的剪枝可能删除关键信息。
-
混合检索噪音:稠密向量、稀疏关键词和规则过滤器使用不兼容的评分标准。简单归一化可能导致过度或不足召回,而跨编码器虽然能解决问题,但会增加2-5倍的延迟。
-
多模态对齐挑战:像CLIP这样的多模态编码器会产生“语义泄露”,即不相关的视觉区域影响文本相似性,这在医疗等领域风险极高。
-
知识图谱检索:虽然在多跳推理方面表现出色,但依赖于嘈杂的实体链接和启发式剪枝,过度剪枝会删除长尾节点,不足剪枝则会耗尽内存。
3. 领域漂移、数据集对齐和泛化(Domain Shift, Dataset Alignment, and Generalisation)
-
跨领域性能下降:在一个领域(如PubMed)表现出色的RAG模型,在没有昂贵再训练的情况下,在另一个领域(如法律)会表现不佳。
-
语料库的新鲜度:陈旧或错误的信息会直接传播到回答中,在金融和医疗等领域是高风险责任。索引刷新可以缓解漂移,但需要耗时耗力的验证。
-
评估集的偏见:大多数评估集严重依赖英文维基百科,这掩盖了专业领域的失败模式,并可能因训练-测试重叠而夸大分数。
-
超参数的脆弱性:分块大小、k值、缓存策略等看似平常的超参数,其不一致的设置可能会导致准确率和延迟曲线发生两位数的剧烈波动,影响可复现性。
模块化管道和错误级联(Modular Pipelines and Error Cascades)
-
脆性链:将检索、重排和生成分离虽然能减少幻觉,但创建了脆弱的链条。第一阶段的错误排名可能会不可逆转地影响生成器。
-
记忆和错误滚雪球:记忆增强型管道虽然能减少重复,但会引入陈旧和错误累积的问题。缓存中的错误信息可能会在后续轮次中被反复检索。
5. LLM局限和安全风险(Large-Language-Model Constraints and Safety Risks)
-
商业LLM的限制:商业LLM API有按token收费、使用上限和持续网络连接等限制。开源模型虽然没有这些限制,但需要昂贵的本地硬件。
-
固定上下文窗口:固定的上下文窗口会截断多文档证据,导致有损分块,削弱检索深度。长上下文变体虽然有帮助,但无法完全恢复跨文档推理。
-
偏见、毒性和幻觉:预训练语料库中的偏见和毒性内容依然存在。检索可以减弱幻觉,但无法完全消除,尤其在医疗领域,事实性错误会造成实际伤害。
-
提示设计的脆弱性:微小的语法编辑就可能改变回答的连贯性和事实性,而恶意提示可以绕过安全防护或引出被破坏的证据。
6. RAG中的安全威胁(Security Threats in Retrieval-Augmented Generation)
-
语料库投毒(Corpus Poisoning):攻击者只需篡改极少量(<0.1%)的语料库内容,就能创建一个后门(back-door)。当一个秘密触发词出现时,这个后门就会被激活,导致RAG系统生成恶意内容。
-
数据泄露和隐私攻击(Data-Exfiltration and Privacy Attacks):通过在提示中注入恶意指令,可以诱使模型从私有数据存储中逐字复制内容,从而泄露敏感数据。
-
越狱和策略规避(Jailbreak and Policy-Evasion):通过注入对抗性内容,检索器会忠实地返回这些内容,从而绕过通常的防护机制。GPT-4等通常对越狱有抵抗力的模型,在这种情况下也会生成被禁止的输出。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









