






本文来源公众号“极市平台”,仅用于学术分享,侵权删,干货满满。
原文链接:ICCV 2025|DiT 架构下的全新训练范式!中科大开源DualReal:打开视频定制“身份+运动”新次元
极市导读
中科大团队提出 DualReal,在 DiT 架构中用双域感知适配模块与阶段融合控制器,实现身份与运动的自适应联合训练,仅需短时微调即可在保持高保真身份的同时生成流畅运动,在 CLIP-I 和 DINO-I 两项指标上平均分别提升了 21.7% 和 31.8%。


论文链接:https://arxiv.org/abs/2505.02192
项目主页链接:https://wenc-k.github.io/dualreal-customization/
开源代码链接:https://github.com/wenc-k/DualReal
摘要
传统双模式的视频定制方法通常沿用“孤立定制”范式,即仅对主体身份或运动动态单一维度进行定制,忽视了身份与运动之间的内在约束与协同依赖,导致在生成过程中二者不断冲突并系统性地退化。中科大团队提出了 DualReal,一种通过自适应联合训练协同构建多维依赖的新框架。
双域感知适配模块 动态切换当前训练阶段(身份或运动),利用冻结维度的先验信息指导另一个模式的学习,并通过正则化策略防止知识泄漏;阶段融合控制器基于不同的去噪阶段和DiT网络深度,为各模式分配自适应的粒度控制,避免在不同阶段出现冲突,从而实现身份与运动模式的无损融合。
构建了一个比现有方法更全面的评估基准。实验结果表明,DualReal 在 CLIP‑I 和 DINO‑I 两项指标上平均分别提升了 21.7% 和 31.8%,并在几乎所有运动质量指标上均取得了最佳表现。
动机
传统视频定制化生成多聚焦于“身份驱动”或“运动驱动”单一维度,忽略两者的内在约束与协同依赖,导致对某一模式过拟合时而带来的一致性退化问题,如下图所示:

-
固定身份定制,并逐步增加运动训练步数(红框代表最佳身份一致性)。
-
实验结果:运动先验会不可逆地损害身份一致性;针对不同身份,无法找到统一的运动训练程度来最小化身份退化。
同时,DiT 模型在不同去噪阶段和不同深度的网络层,对身份与运动特征的关注焦点时刻发生变化,如何动态协调身份与运动特征的比例,以实现高质量模式定制:
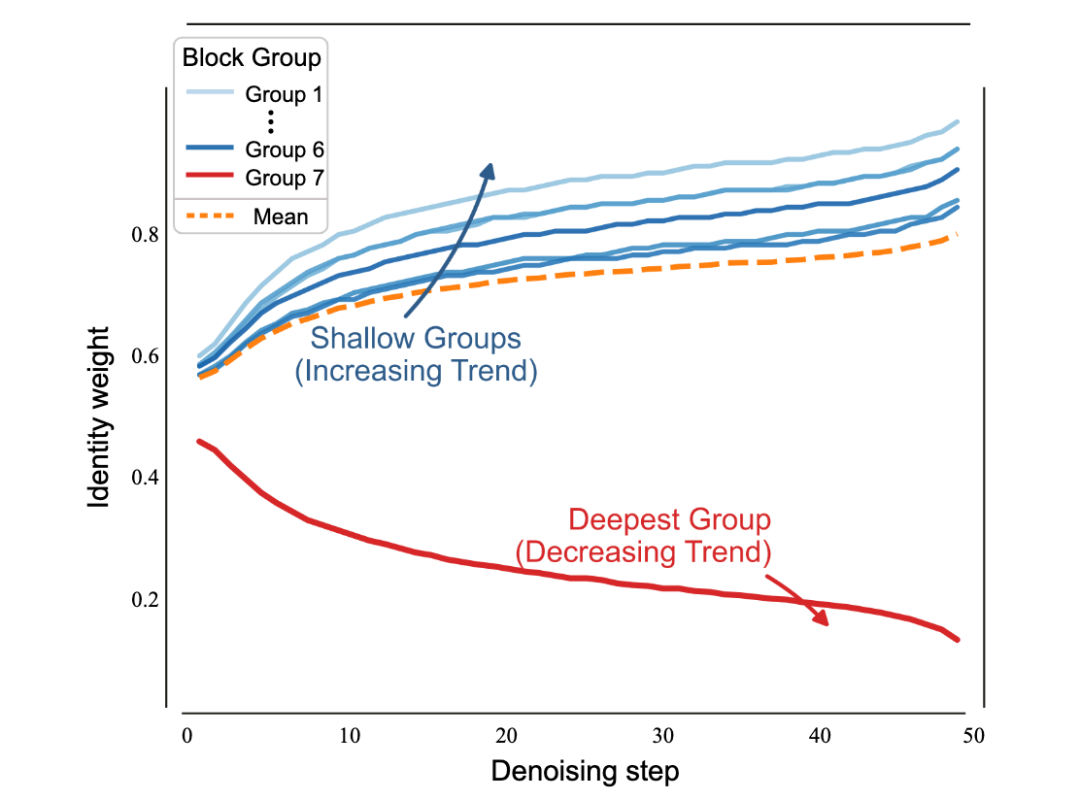
-
随着去噪程度加深,模型越来越重视身份学习(橙色虚线)。
-
在 DiT 最深的网络层组,趋势相反:随着去噪深入,模型更侧重于运动建模(红色实线)。
方法
双域感知适配模块
为了在解决维度冲突的同时实现身份和动作的联合训练,我们创新性地提出了双域感知适配模块。该方法利用一个模式的先验来引导另一个模式的训练,同时通过正则化策略防止信息泄漏,如下图所示:
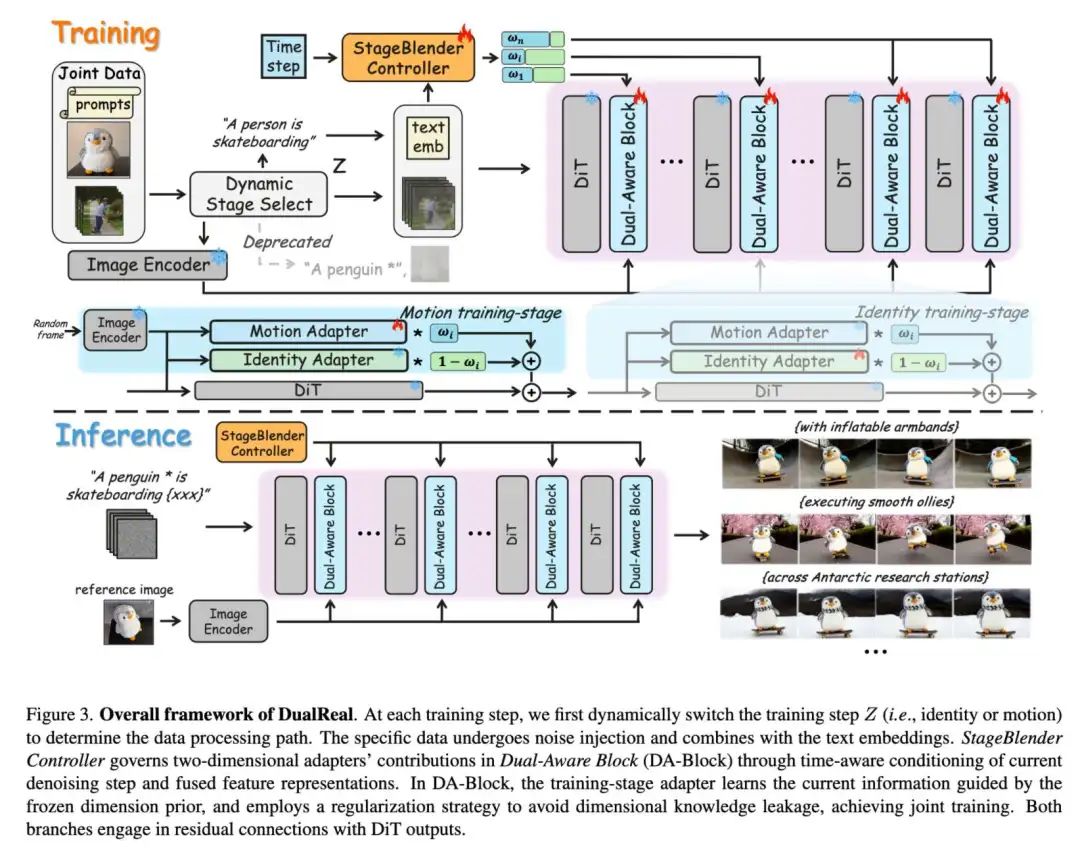
联合身份-运动优化

正则化策略

阶段融合控制器
为了解决不同处理阶段的维度竞争问题,我们提出了阶段融合控制器。
该控制器通过对缩放系数进行时间感知,使双域感知适配模块能够根据下图所示的机制自适应地分配特定模式的权重,以此实现粒度解耦。
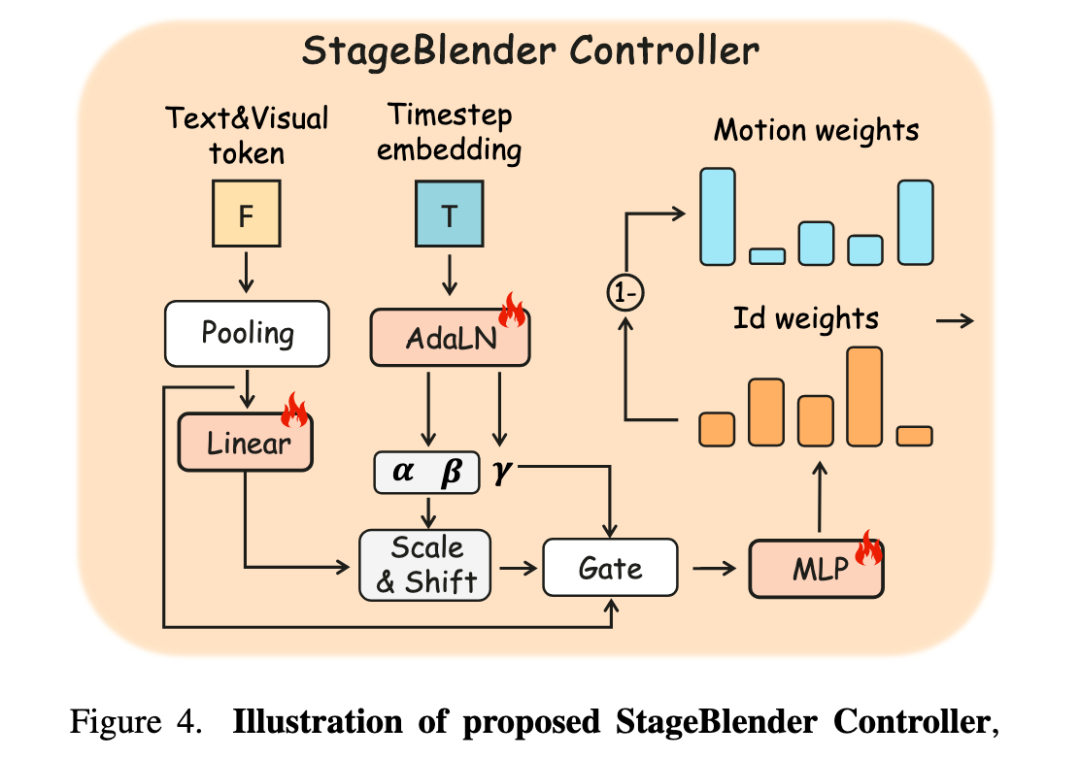
具体来说,阶段融合控制器根据去噪时间步和融合的文本-视觉特征,动态生成多组针对不同DiT深度层的缩放权重。

实验
实验设置
-
评估数据集:
-
对于身份定制,我们严格从先前工作和互联网平台(包括宠物、毛绒玩具等)中选择了50个主体,每个主体包含3–10张图像。
-
对于动作定制,我们从公共数据集中收集了21个具有挑战性动态模式的动作序列。
-
此外,每个案例提供了50个不同的提示词(包含不同的修饰或环境),以评估方法的可编辑性和场景多样性。
-
-
基线方法:在现有方法中,DreamVideo能够同时定制身份和动作。为了公平比较,我们在相同的DiT骨干上实现了两种方法:(1)CogVideoX-5B:按照DreamBooth范式先对身份数据、再对动作数据进行全参数顺序微调;(2)LoRA微调:分别训练两个LoRA模块用于身份和动作,然后在推理时融合其参数。此外,MotionBooth的身份模块在训练过程中引入了无关的随机视频以保留模型的动作能力,因此我们也将其与我们的方法进行比较。
-
评估指标:使用了三个维度的七项指标。
-
文本-视频一致性:通过CLIP-T分数衡量,计算为文本提示与所有生成帧之间的CLIP余弦相似度。
-
身份保真度:使用DINO-I和CLIP-I分数量化,分别通过DINO ViT-S/16和增强的CLIP嵌入评估生成帧与参考身份图像之间的特征相似度。
-
时间动作质量:使用四项指标评估,包括T-Cons用于时间一致性,Motion Smoothness(MS)用于整体流畅度,Temporal Flickering(TF)用于相邻帧之间的高频不一致性(通过平均绝对差衡量),以及Dynamic Degree(DD)利用RAFT光流估计来量化动作强度(我们计算方法相对于基准的偏差,来确定动作强度的一致性)。MS、TF和DD均来自综合视频基准VBench。
-
主要结果
-
定性结果:下图中的定性实验表明,虽然MotionBooth保持了身份保真度,但它无法有效建模动作模式;DreamVideo在推理过程中因模式冲突而导致身份不一致;CogVideoX-5B和LoRA由于其解耦的训练方法,也难以保持身份。相比之下,DualReal 实现了高身份一致性和连贯的动作,展示了联合训练在平衡模式冲突方面的优势。

-
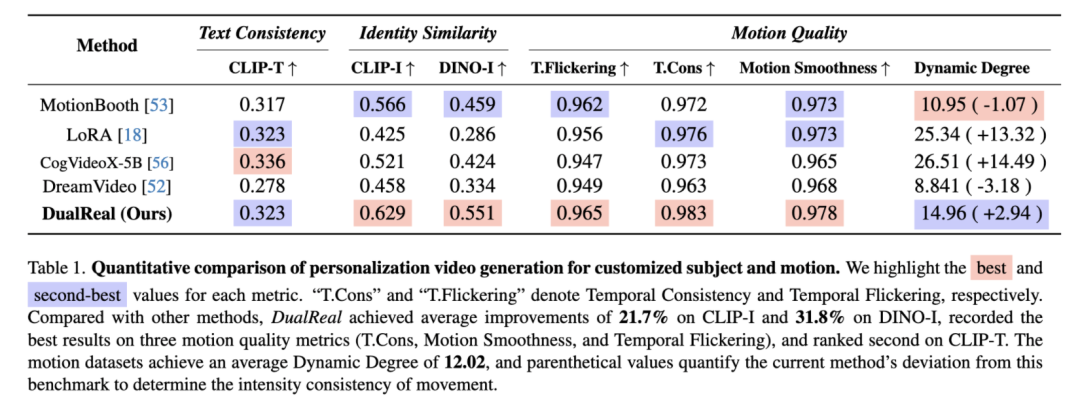
定量结果:如下表所示,DualReal 在CLIP-I和DINO-I指标上平均提高了21.7%和31.8%,在三项动作质量指标(T-Cons、Motion Smoothness和Temporal Flickering)上取得了最佳结果,并在CLIP-T上排名第二;我们评估了所有动作数据,计算其平均DD为12.02。我们的指标与之略有偏差,证明动作幅度没有失真。总体而言,我们的方法在保持文本一致性的同时,显著增强了动作连贯性和身份保真度,进一步验证了我们的自适应联合训练方法。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









