









本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:科大讯飞AI大赛:X光安检图像识别挑战赛 赛季6 Baseline
-
赛题名称:X光安检图像识别挑战赛
-
赛题类型:计算机视觉、物体检测
-
赛题任务:安检图像中的指定类别的物品进行检测
https://challenge.xfyun.cn/topic/info?type=Xray-25&ch=dwsf259
赛题背景
随着社会的不断发展,大规模集中的公共场所(如机场、火车站、地铁站等)对于安全保障的需求日益增加。
X光安检技术作为一种重要的非侵入式检测手段,已广泛应用于各类场景。现代安检技术借助人工智能技术,通过对X光安检图像的自动化分析与违禁品识别,可有效提升安检效率与准确性,减轻安检人员的负担,实现智能化安检。
在实际场景中,因待检测物品的多样性、尺度差异、成像角度和重叠遮挡等问题,X光安检图像检测算法的识别率和准确率急需进一步提高。
赛事任务
基于科大讯飞提供的真实X光安检图像集构建检测模型,对X光安检图像中的指定类别的物品进行检测,识别出物体的位置和类别。
赛题数据
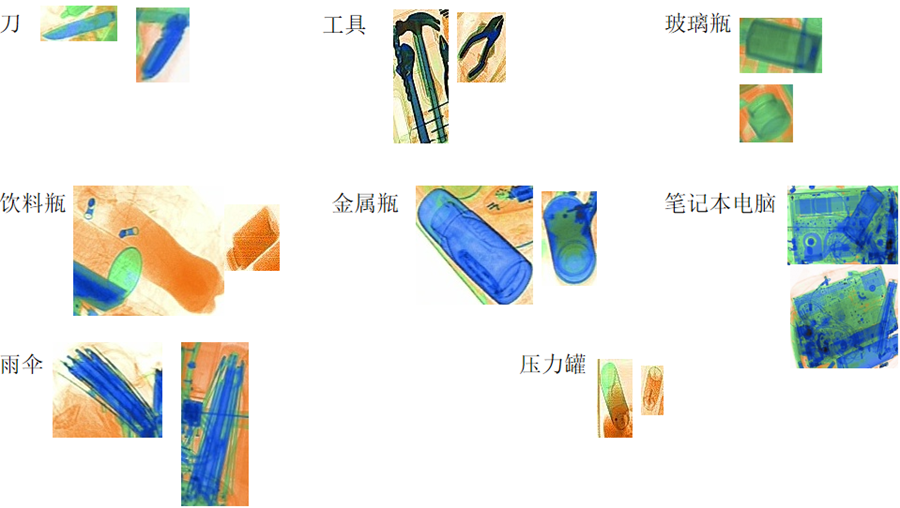
本次比赛标注文件中的类别为8类,包括:刀(knife)、工具(tool)、玻璃瓶(glassbottle)、饮料瓶(drinkbottle)、金属瓶(metalbottle)、笔记本电脑(laptop)、雨伞(umbrella)、压力罐(pressuretank)。待识别物品的X光成像示意图如下图所示。
比赛提供的X光图像及其矩形框标注的文件按照数据来源存放在不同的文件夹中,图像文件采用jpg格式,标注文件采用xml格式,各字段含义参照voc数据集。voc各字段含义对应表为:
├── filename 文件名
├── size 图像尺寸
├── width 图像宽度
├── height 图像高度
└── depth 图像深度,一般为3表示是彩色图像
└── object 图像中的目标,可能有多个
├── name 该目标的标签名称
└── bndbox 该目标的标注框
├── xmin 该目标的左上角宽度方向坐标
├── ymin 该目标的左上角高度方向坐标
├── xmax 该目标的右下角宽度方向坐标
└── ymax 该目标的右下角高度方向坐标
评估指标
评测方式采用计算mAP(IoU = 0.5)的方式。
-
根据预测框和标注框的IoU是否达到阈值0.5判断该预测框是真阳性还是假阳性;
-
根据每个预测框的置信度进行从高到低排序;
-
在不同置信度阈值下计算精确率和召回率,得到若干组PR值;
-
绘制PR曲线并计算AP值。
-
然后计算mAP:把所有类的AP值求平均得到mAP。
选手需要提交json格式文件,详情见示例。其中,坐标值必须为大于0的正数且不能超过图像的宽高。
提交文件需按序排列,首先按图片顺序排列,然后按类别顺序排列,置信度顺序随意。
-
图片顺序,请按照图片编号顺序。
-
类别顺序,请参照下列顺序: {'knife':1, 'tool':2, 'glassbottle':3, 'drinkbottle':4, 'metalbottle':5, 'laptop':6, 'umbrella':7, 'pressuretank':8}
赛题 Baseline
赛题是一个典型的目标检测数据,为此可以优先考虑YOLO模型。
-
转换为YOLO格式
def convert_voc_to_yolo(xml_path, output_dir, class_names):
"""
Convert Pascal VOC XML annotation to YOLO format
Args:
xml_path (str): Path to XML file
output_dir (str): Directory to save YOLO txt files
class_names (list): List of class names in order
"""
# Parse XML
tree = ET.parse(xml_path)
root = tree.getroot()
# Get image dimensions
size = root.find('size')
img_width = int(size.find('width').text)
img_height = int(size.find('height').text)
# Create output file path
image_name = os.path.splitext(os.path.basename(xml_path))[0]
txt_path = os.path.join(output_dir, f"{image_name}.txt")
with open(txt_path, 'w') as f:
for obj in root.iter('object'):
# Get class name
cls_name = obj.find('name').text
if cls_name not in class_names:
continue# skip classes not in our list
cls_id = class_names.index(cls_name)
# Get bounding box coordinates
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
# Convert to YOLO format (center x, center y, width, height) - normalized
x_center = ((xmin + xmax) / 2) / img_width
y_center = ((ymin + ymax) / 2) / img_height
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
# Write to file
f.write(f"{cls_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}\n")
-
生成训练配置
with open('yolo.yaml', 'w', encoding='utf-8') as up:
up.write(f'''
path: {dir_path}/
train: train_yolo/train/
val: train_yolo/val/
names:
0: knife
1: tool
2: glassbottle
3: drinkbottle
4: metalbottle
5: laptop
6: umbrella
7: pressuretank
''')
-
训练模型
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
model = YOLO("yolov8m.pt")
results = model.train(data="./yolo.yaml", epochs=20, device=1, batch=8, imgsz=640)
-
测试集预测
from glob import glob
import os
test_paths = glob('test1/*')
test_paths.sort()
all_result = []
for path in test_paths:
predictions = model(path, save_txt=None) # yolo model
result = [[], [], [], [], [], [], [], []]
for idx in range(len(predictions[0].boxes.cls)):
# Get class name
cls_id = int(predictions[0].boxes.cls[idx].item())
x1, y1, x2, y2 = predictions[0].boxes.xyxy[idx].tolist()
result[cls_id].append([x1, y1, x2, y2, predictions[0].boxes.conf[idx].item()])
all_result.append(result)
with open("submit.json", "w") as up:
json.dump(all_result, up)

THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









