






本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:VisionThink开源 | 从"一刀切"到智能判断,VisionThink用RL优化VLM视觉Token压缩范式

精简阅读版本
本文主要解决了什么问题
-
1. 视觉语言模型(VLMs)中视觉 Token 消耗过高的问题:随着模型性能的提升,视觉 Token 的使用呈指数级增长,导致计算资源浪费。
-
2. 统一压缩视觉 Token 的问题:现有方法通常采用固定剪枝率或阈值压缩 Token,但不同任务对分辨率的需求差异较大,导致性能下降,特别是在OCR等需要细粒度视觉理解的任务中。
-
3. 如何在通用视觉问答(VQA)任务中有效应用强化学习:传统基于规则的强化学习难以处理通用VQA任务的多样性和复杂性。
本文的核心创新是什么
-
1. 提出 VisionThink 范式:该范式通过动态判断是否需要高分辨率图像,在保持性能的同时显著减少视觉 Token 的使用。
-
2. 引入 LLM-as-Judge 策略:利用大语言模型(LLM)作为评判者,评估模型输出的正确性和格式,从而实现强化学习在通用VQA任务中的有效应用。
-
3. 设计动态 Reward 函数与惩罚机制:通过设计包含准确率、格式和控制惩罚的多目标 Reward 函数,引导模型在效率与性能之间取得平衡。
-
4. 多轮 GRPO 算法扩展:将组相对策略优化(GRPO)算法扩展至多轮推理设置,以适应 VisionThink 的动态分辨率请求机制。
-
5. 智能数据筛选机制:通过在训练数据中筛选出需要高分辨率与仅需低分辨率即可回答的问题,构建用于强化学习训练的数据集。
结果相较于以前的方法有哪些提升
-
1. 效率提升显著:
-
• 在 DocVQA 等任务上实现了高达 100% 的推理速度提升;
-
• 在 MME 和 POPE 等基准测试中推理时间比 Baseline 提高约三分之一;
-
• 在大多数非OCR任务中接近使用 1/4 分辨率的 QwenRL 1/4 模型的效率。
-
-
2. 性能优势明显:
-
• 在 OCR 相关任务(如 ChartQA 和 OCRBench)中分别比 FastV 和 SparseVLM 提高了 9.0% 和 8.3%;
-
• 在 MMVet 和 MathVerse 等通用 VQA 基准测试中分别达到 67.1 和 48.0 分,优于基础模型;
-
• 在 MME 上超越所有闭源模型,达到 2400 分。
-
-
3. 模型智能判断能力增强:
-
• VisionThink 能够根据图像内容智能判断是否需要更高分辨率,例如在 OCR 任务中请求高分辨率的比例显著高于其他任务;
-
• 模型在低分辨率下直接回答问题的能力显著提升,减少了不必要的高分辨率调用。
-
局限性与未来工作
-
1. 分辨率提升的灵活性有限:目前仅支持 2 倍分辨率提升和最多 2 轮对话,未来可探索更灵活的分辨率调整机制。
-
2. 多轮调用尚未充分探索:目前仅限于两轮图像调用,未来可研究超过 5 轮的多轮调用机制以应对更复杂的视觉问题。
-
3. 未集成更先进的 Token 压缩技术:目前仅使用图像缩放进行 Token 压缩,未来可结合更先进的视觉 Token 压缩方法进一步提升效率。
-
4. 依赖外部 LLM 作为评判者:虽然 LLM-as-Judge 提升了强化学习效果,但其依赖外部模型,未来可探索更轻量或自适应的评判机制。
深入阅读版本
导读
近年来,视觉语言模型(VLMs)的进展通过增加视觉 Token 的数量提升了性能,而视觉 Token 通常远长于文本 Token 。然而,作者观察到大多数实际场景并不需要如此大量的视觉 Token 。虽然在小部分OCR相关任务中性能显著下降,但模型在大多数其他通用VQA任务中仅使用1/4分辨率时仍能准确执行。因此,作者提出动态处理不同分辨率的独立样本,并提出了新的视觉 Token 压缩范式,即VisionThink。它从下采样图像开始,智能地判断其是否足以解决问题。否则,模型可以输出一个特殊 Token 来请求更高分辨率的图像。与现有通过固定剪枝率或阈值压缩 Token 的Efficient VLM方法相比,VisionThink能够根据具体情况自主决定是否压缩 Token 。因此,它在OCR相关任务上展现出强大的细粒度视觉理解能力,同时在简单任务上节省了大量视觉 Token 。作者采用强化学习,并提出LLM-as-Judge策略,成功将RL应用于通用VQA任务。此外,作者精心设计了 Reward 函数和惩罚机制,以实现稳定合理的图像缩放调用比例。大量实验证明了VisionThink的优势、效率和有效性。
1 引言
近年来,视觉语言模型(VLMs)[31, 30, 33, 9, 3] 通过将视觉 Token 投影并适配到大语言模型(LLM)空间 [61, 1, 93, 4],在通用视觉问答(General VQA)和各种实际场景中取得了显著性能。然而,随着VLM性能的持续提升,视觉 Token 的消耗呈指数级增长。例如,一部智能手机拍摄的 2048x1024 照片在LLaVA 1.5 [33] 中需要576个视觉 Token ,而现在在Qwen2.5-VL [5] 中则需要2,678个视觉 Token 。因此,避免过度使用视觉 Token 势在必行。
视觉 Token 压缩方面已提出大量研究工作[65, 55, 18, 22, 8, 91]。大多数方法使用预设阈值对固定数量的视觉 Token 进行剪枝或合并。然而,冗余程度在不同问题和图像间存在差异,由此引出一个自然的问题:作者是否真的应该在所有场景中应用统一的 Token 压缩率?为回答此问题,作者通过降低图像分辨率来减少视觉 Token 数量,并在多个基准测试中评估了Qwen2.5-VL[5]的性能。如图1左侧所示,作者发现对于大多数实际场景(如MME和RealWorldQA),即使将图像分辨率降低四倍(显著减少75%的视觉 Token ),对模型性能的影响也极小。然而,如图1右侧所示,对于需要详细理解和OCR相关能力的基准测试(如ChartQA和OCRBench),减少视觉 Token 数量会导致性能显著下降。基于这些观察结果,作者发现大多数实际问题不需要高分辨率图像和长视觉 Token ,而一小部分OCR相关任务却需要这种详细输入。因此,如果作者能够动态区分需要高分辨率处理和不需要处理的样本,将存在显著的效率优化潜力。
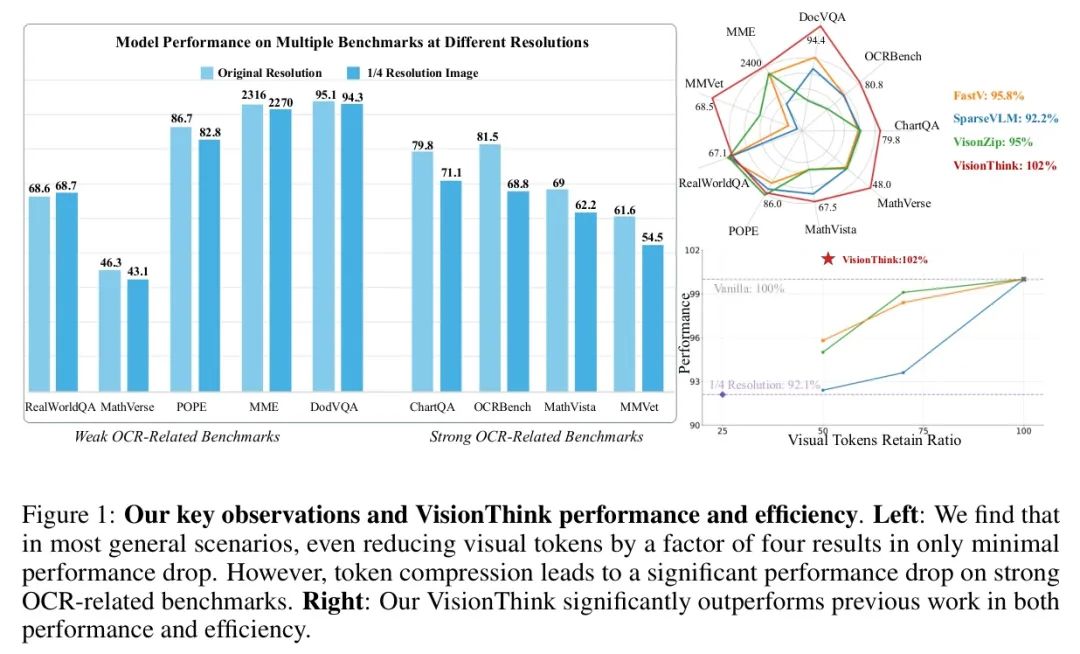
在这篇论文中,
作者提出了VisionThink,一种新的EfficientVLM范式,该范式利用模型的推理能力。与以往处理完整图像并在后期丢弃冗余 Token 的方法不同,VisionThink直接输入压缩的视觉 Token ,并在需要时允许模型请求原始高分辨率图像。这能够在大多数实际场景中实现更高效的推理,同时保持OCR相关任务上的性能。
尽管VisionThink提供了一种智能处理具有不同视觉冗余程度的样本的可行方法,但它仍然面临两个关键挑战:
面向通用视觉问答的有效强化学习。传统的基于规则的强化学习算法,通常用于优化推理过程,在处理通用视觉问答的多样性和复杂性方面存在困难。为解决这一问题,作者提出了LLM-as-Judge方法,实现语义匹配。实验结果表明,该方法在多个通用视觉问答基准测试中性能得到提升,凸显了将基于视觉的强化学习从视觉数学推理扩展到更广泛的视觉问答任务的潜力。
确定何时使用高分辨率是值得的。为了在不影响性能的前提下提高效率,模型必须准确判断何时需要高分辨率输入。作者通过精心设计一个平衡的 Reward 函数来实现这一点,以防止模型陷入总是要求高分辨率图像或总是使用低分辨率图像的困境。借助这一机制,VisionThink在OCR基准测试中保持优异性能,同时在非OCR基准测试中显著提升速度,在DocVQA上实现了高达100%的提升。
总体而言,作者提出了一种简单而有效的流程——VisionThink。它通过根据每个样本的内容动态确定压缩方式,为视觉 Token 压缩引入了一种新方法,从而在样本 Level 实现了效率提升。因此,它与其他先进的空间级方法兼容。作者希望作者的工作能为该领域带来新的启示。
2 初步
2.1 大语言模型与强化学习
近年来提升大语言模型(LLMs)推理能力的研究进展[16, 21]表明,强化学习(RL)是一种有效的训练方法。在本工作中,作者采用组相对策略优化(GRPO)[52]作为训练方法。GRPO通过使用组分数来估计 Baseline ,无需单独的评估者模型。这降低了计算成本,提升了训练稳定性,并带来了更快、更可靠的性能提升。

2.2 计算复杂度
为评估视觉语言模型(VLMs)的计算复杂度,作者分析了其关键组件,包括自注意力机制和 FFN (FFN)。总浮点运算次数(FLOPs)由下式给出:

3 方法论
3.1 概述
作者的目标是开发一个智能高效的视觉语言模型,能够自主判断给定图像中的信息是否足以准确回答问题。如图2所示,该流程首先处理低分辨率图像以降低计算成本。当下采样图像中的信息不足以回答问题时,它会智能地请求原始高分辨率输入。理想情况下,这种策略在保持高性能的同时显著降低计算负载。为实现这一目标,作者必须解决两个关键挑战:
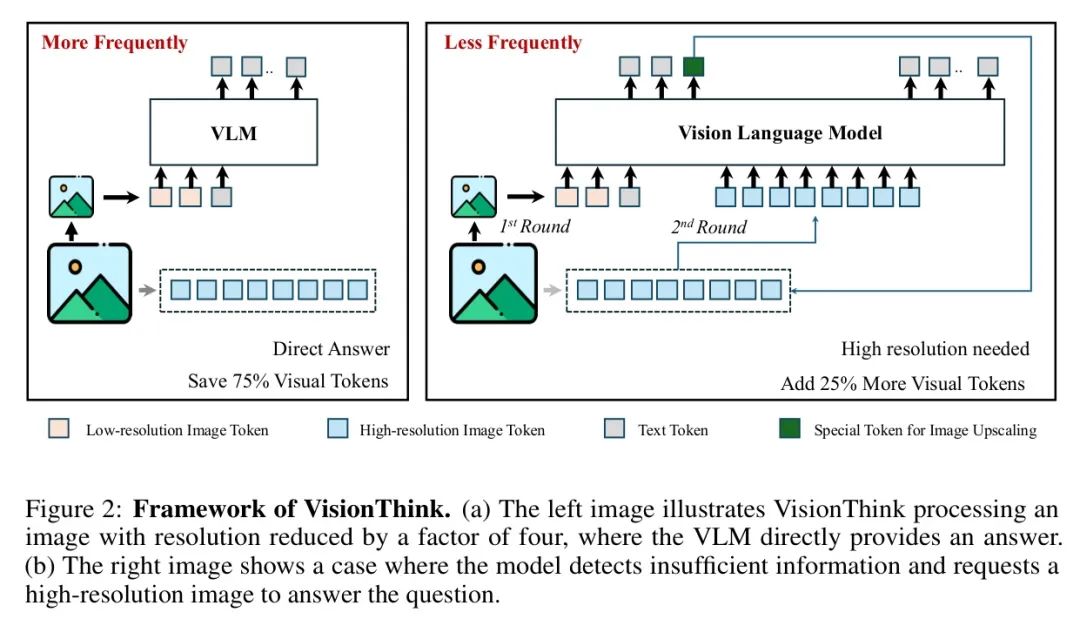
在通用视觉问答任务上的有效强化学习。由于通用视觉问答任务的多样性和复杂性,传统的基于规则的强化学习算法不能直接适用。为此,作者提出了一种将大语言模型作为裁判的策略,其中大语言模型指导并评估强化学习训练过程(第3.2节)。作者进一步扩展了多轮GRPO算法以适应作者的设置(第3.3节)。
使模型能够判断何时需要高分辨率。模型必须学习评估下采样图像是否包含足够的信息来回答问题,从而判断是否需要原始高分辨率图像。这样,模型能够在效率和性能之间取得平衡。为此,作者设计了一个 Reward 函数,以鼓励最优分辨率决策(第3.4节),并收集跨多个分辨率的训练数据以支持有效学习(第3.5节)。
3.2 以大语言模型作为裁判器进行通用视觉问答
挑战。将强化学习应用于通用视觉问答的一个核心挑战在于评估模型响应,尤其是在答案为开放式或依赖于上下文的情况下。大多数现有的多模态强化学习研究仍局限于结构化任务,如视觉数学题,其中可以通过规则或精确匹配轻松定义和验证正确答案。然而,这种方法在通用视觉问答场景中失效,因为有效答案的多样性和模糊性使得基于规则的验证变得不可行。
为解决此问题,作者采用外部大语言模型(LLM)作为评判评估器。利用其广泛的知识和语言理解能力,LLM以与人类一致且灵活的方式评估模型输出的正确性。重要的是,评估完全通过文本进行,通过将模型的答案与真实值进行比较。这种设计避免了视觉内容的偏差以及VLM性能的限制。此外,为了最小化评估者可能出现的误判, Reward 是离散的(0或1),而非连续的。详细的评判 Prompt 显示在附录B.1中。
有效性。LLM-as-Judge具有灵活性,其优势之一是大部分SFT数据可以被使用。为了验证作者提出的LLM-as-Judge的有效性,作者收集了130K个样本,这些样本可以直接用于使用GRPO训练模型,无需任何冷启动过程。结果表明,与基础模型Qwen2.5VL-Instruct相比,效果有显著提升。更多细节请参见附录B.5。
3.3 多轮训练算法
多轮GRPO。在作者的VisionThink框架中,作者首先将问题和下采样图像输入到视觉语言模型(VLM)中。如果信息不足以回答当前问题,模型将自主请求更高分辨率的图像并生成新的响应。这个过程本质上是一个多轮交互。因此,作者将原始的GRPO(公式1)扩展为多轮GRPO,如公式3所示:

模型如何表明需要高分辨率图像?为了确定模型何时需要高分辨率图像,作者修改 Prompt 词,指示模型输出特定的特殊 Token 。值得注意的是,这是一个非平凡的过程,因为作者的训练没有引入任何冷启动阶段,这会导致一般视觉问答(VQA)性能下降(附录C.2)。因此,在训练早期选择一个适当且有效的 Prompt 词至关重要。 Prompt 词必须确保模型在零样本设置下的多轮推理中能够输出所需的特殊 Token 。否则,由于缺乏梯度,GRPO将无法正确优化。作者在附录C.3中进行了比较消融研究,发现Qwen-2.5VL [5]推荐的 Agent Prompt 词最适合VisionThink。 Prompt 词的详细信息在附录B.1中提供。
3.4 Reward 设计
不同的 Reward 函数可以引导模型朝向不同的优化方向和最终性能结果。作者的VisionThink框架中的 Reward 函数由三个组成部分构成:

格式 Reward 。为了保持模型的指令跟随能力,并确保训练后的模型能够更准确地调用图像缩放函数,作者应用了格式 Reward 。具体来说,作者要求推理过程被包含在""标签中,最终答案被包含在""标签中,函数调用需符合附录B中指定的JSON格式。如果这些格式中的任何一项不正确,格式分数为0。只有当所有格式都正确时,模型才能获得0.5的满分格式分数。
惩罚控制。惩罚的设计是 Reward 函数的关键组成部分。如图3(a)所示,由于使用高分辨率图像通常能提升性能,如果没有惩罚,模型倾向于总是请求高分辨率图像。为防止这种情况,作者最初遵循Search-R1 [23],对依赖高分辨率图像的正确答案应用了0.1的惩罚。然而,这种方法导致模型倾向于直接回答,进而导致模型完全依赖直接回答的崩溃现象,如图3中紫色线所示。原因是即使模糊的低分辨率图像有时也能让模型猜出正确答案,而0.1的惩罚无意中强化了这种直接回答的偏好。
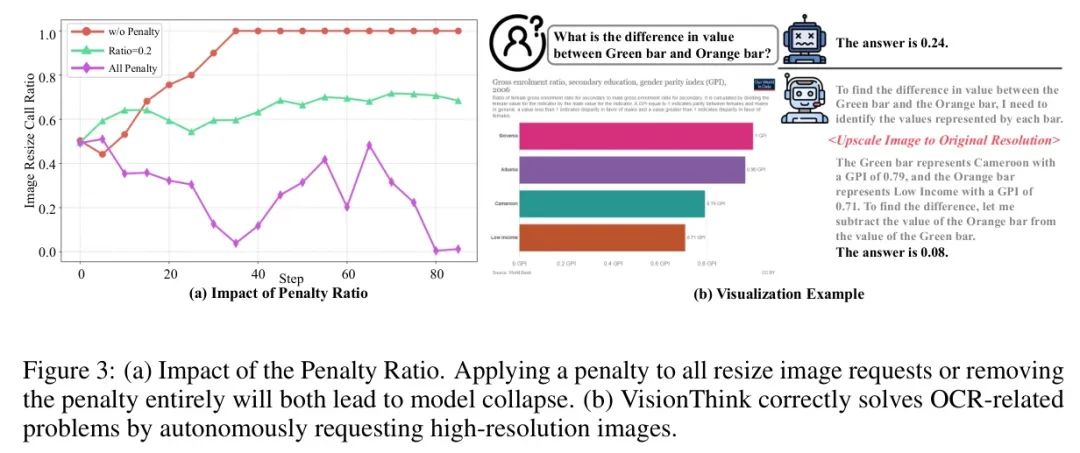
为解决这一问题,作者引入一个阈值来控制“幸运猜测”现象。当使用低分辨率图像正确回答的概率较低时,作者对直接回答施加0.1的惩罚,以鼓励高分辨率请求;相反,当概率较高时,作者对高分辨率请求施加0.1的惩罚。总而言之,惩罚的设计如下:

3.5 数据准备
为使VisionThink能够判断何时需要高分辨率图像,作者收集了相应的VQA样本,包括需要高分辨率图像的情况和仅使用下采样图像即可充分回答的情况。为此,作者使用基础策略模型Qwen2.5VL-Instruct在训练数据集上进行多次滚动执行,并根据准确率对样本进行分类。具体而言,作者将温度设置为1,并对每个样本进行8次滚动执行。如果高分辨率图像和下采样图像在所有8次滚动执行中都给出正确答案,作者将该样本分类为使用低分辨率即可解决。相反,如果使用高分辨率图像得到的正确答案数量比下采样图像多6次或更多,作者将该样本分类为需要高分辨率。通过使用上述方法,作者选择了10K个需要高分辨率图像的样本和10K个不需要的样本来训练VisionThink。
4 实验
4.1 评估设置
基准测试。作者对VisionThink在多个通用VQA基准上进行了评估,包括ChartQA [43]、OCRBench [37]、MathVista [40]、MMVet [83]、RealWorldQA [68]和MathVerse [88]等。值得注意的是,ChartQA、OCRBench和MathVista等基准与OCR密切相关,要求模型具备高度细节理解能力。这些基准的详细描述在附录B.4中展示。
实现细节。作者基于Qwen2.5-VL-7B-Instruct[5]进行实验。在训练过程中,作者采用veRL[54]框架,并使用总批大小为512,小批大小为32。作者设置策略LLM学习率为,每个 Prompt 采样16个响应,确保训练过程稳定有效。在推理阶段,作者使用vLLM框架并将温度设置为0。更多细节请参见附录B.3。
4.2 强化学习使VLM更有效
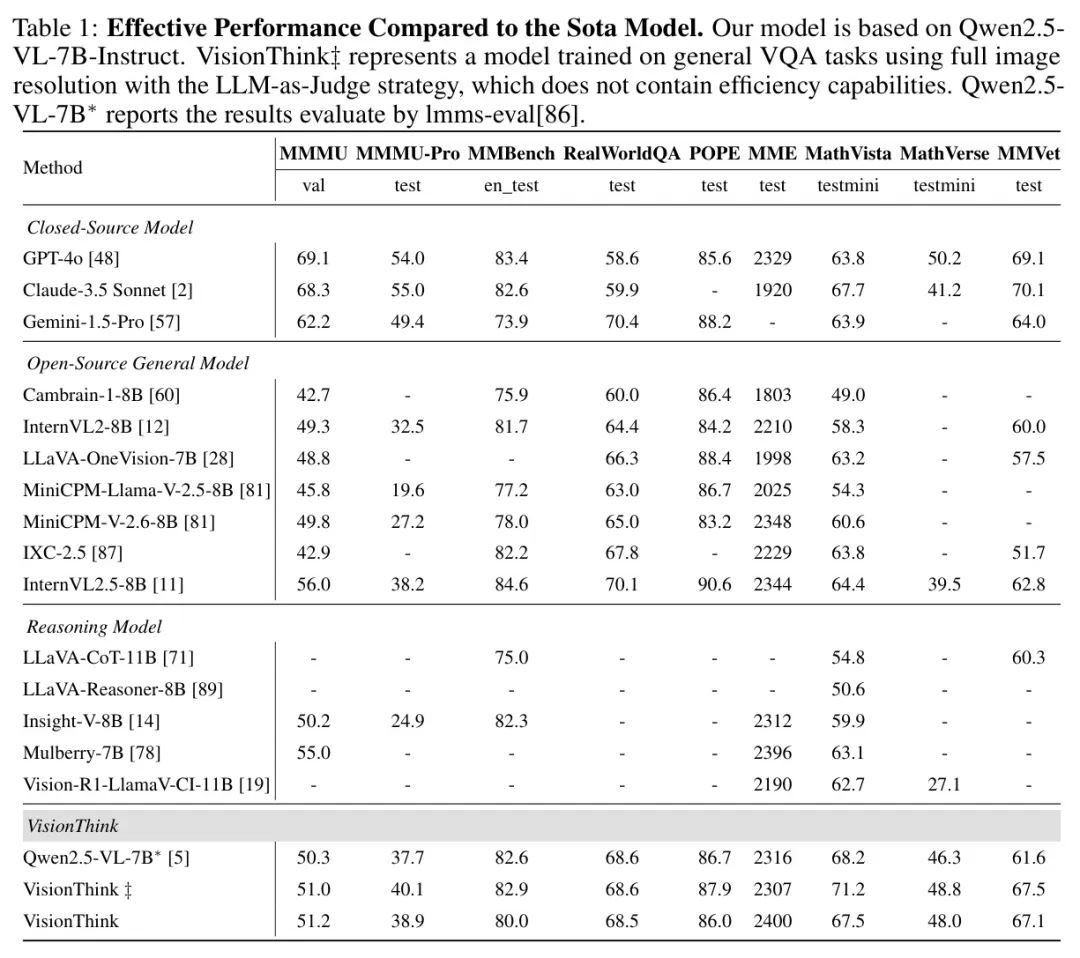
主要结果。为了展示VisionThink的有效性,作者将VisionThink与当前的开源和闭源的最先进(SOTA)方法进行比较。如表6所示,VisionThink 被用于展示LLM-as-Judge策略在通用VQA任务上的有效性。它代表1个仅使用准确性和格式 Reward ,并以完整图像分辨率进行训练的模型,因此不包含效率能力。结果表明,作者的VisionThink在通用VQA任务上实现了相当甚至更优越的性能,同时更加高效。具体而言,MathVerse和MMVet达到了48.0和67.1的分数,分别比基础模型提高了3.7%和8.9%。此外,VisionThink在MathVista和MMBench等多个基准测试上的表现与闭源模型相当,甚至在MME上超越了所有闭源模型,达到了2400分。此外,如图3(b)所示,通过引入LLM-as-Judge进行测试时扩展,VisionThink的答案优于原模型的短直接答案。此外,作者将数据规模扩展到130K,并进一步展示了LLM-as-Judge在通用VQA任务上的有效性。结果见附录B.5。
4.3 强化学习使VLM效率更高
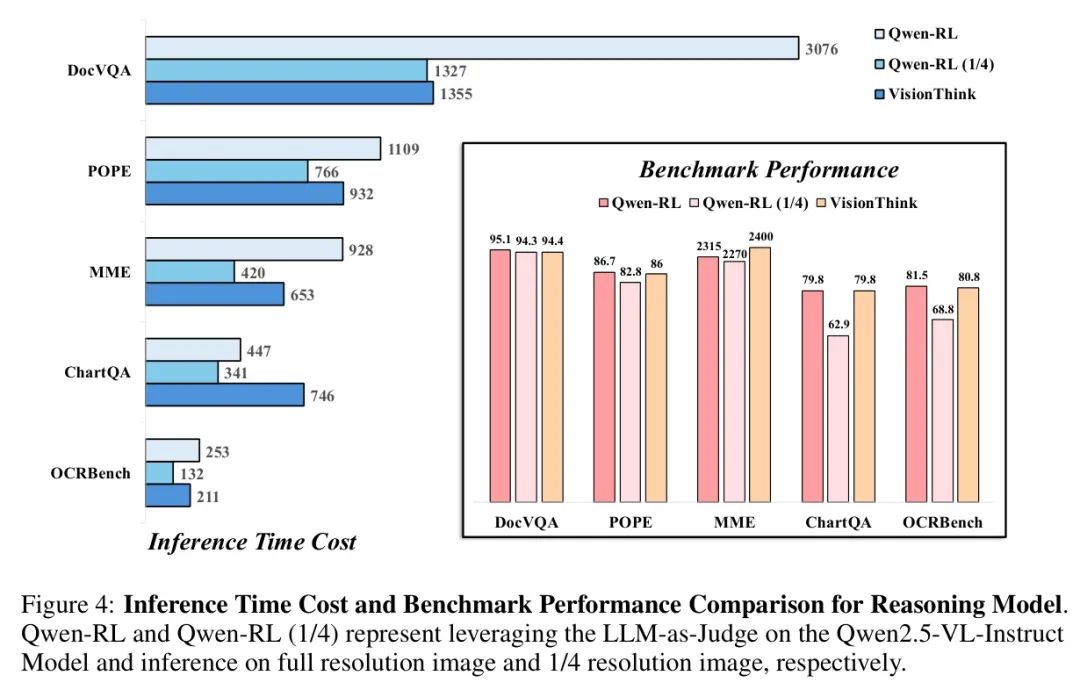
与推理模型的对比。为展示VisionThink的效率,作者首先将作者的VisionThink与QwenRL和QwenRL 1/4进行比较,两者均为基于Qwen2.5-VL-7B Instruct的LLM-as-Judge策略训练的推理模型。QwenRL和QwenRL 1/4分别代表使用全分辨率图像和1/4分辨率图像的推理。如图4所示,作者比较了三个模型的推理时间成本。值得注意的是,报告的推理时间反映了vLLM推理过程中实际消耗的时间,作者认为这最能代表实际应用中的效率。结果表明,在大多数基准测试中,VisionThink的推理时间接近使用1/4图像 Token 的QwenRL 1/4,并且显著优于处理所有图像 Token 的QwenRL模型。具体而言,在DocVQA基准测试中,作者的VisionThink模型的推理速度是QwenRL的两倍多。在MME和POPE等基准测试中,VisionThink在推理时间方面也比 Baseline 提高了约三分之一。值得注意的是,在像ChartQA这样高度依赖OCR的基准测试中,VisionThink消耗的时间比 Baseline QwenRL更多。这是因为VisionThink识别出大多数问题在低分辨率下无法正确回答,因此自主请求高分辨率图像。结果,VisionThink使用的图像 Token 总数超过了 Baseline ,作者认为这是合理的。然而,这类高度依赖OCR的基准测试相对较少,因此VisionThink的整体效率仍然很高。
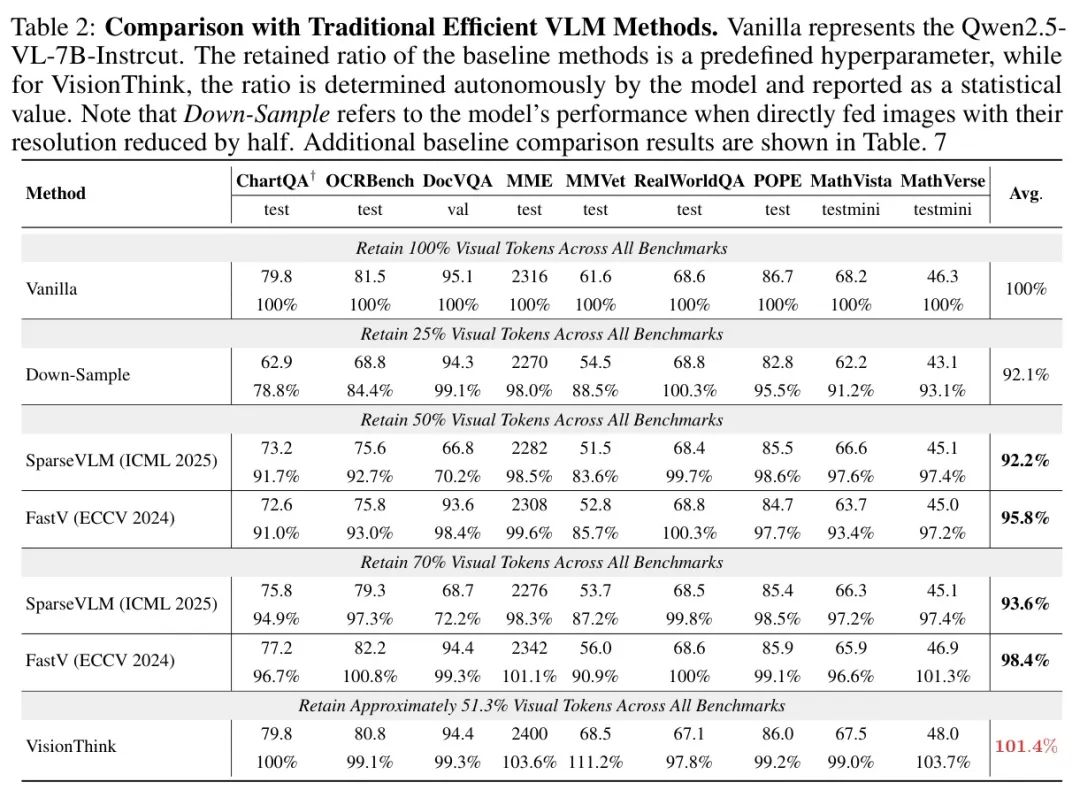
与先前高效视觉语言模型(VLM)的比较。为了进一步展示作者的VisionThink的有效性,作者将其与先前的高效VLM方法FastV和SparseVLM进行比较。值得注意的是,这些方法都需要计算注意力分数来剪枝视觉token,这使得它们难以使用FlashAttention2进行优化,并可能导致内存使用增加。此外,它们与高效推理框架vLLM不直接兼容。因此,为了确保公平比较,作者在尽可能保持视觉token消耗一致的情况下评估模型性能。如表2所示,作者的VisionThink在九个基准测试中平均优于先前方法。此外,先前方法需要预定义剪枝率阈值,而VisionThink可以根据问题和图像内容自主决定是否减少token。因此,在ChartQA和OCR Bench等OCR相关基准测试中,VisionThink分别比FastV和SparseVLM显著提高了9.0%和8.3%。
4.4 强化学习使VLM变得更智能
在本节中,作者展示了在不同基准测试中,作者的VisionThink直接给出答案的样本比例与请求高分辨率图像的样本比例。这说明了模型能够智能地判断下采样图像中的信息是否足够。如图5所示,作者观察到在ChartQA和OCRBench等需要详细视觉理解的基准测试上,VisionThink请求高分辨率图像的比例更高。相比之下,对于MME和DocVQA等基准测试,至少有70%的样本可以直接使用原始分辨率1/4的低分辨率图像进行回答。

这些结果与人类直觉相符:大多数日常问题并不需要高分辨率图像,而只有OCR相关的任务真正依赖于它们。此外,为了更好地展示VisionThink的“智能能力”,作者在附录D中进行了案例研究。
4.5 EfficientVLM方法和VisionThink的关系
主要区别。传统高效视觉语言模型方法以冗余图像为输入,并在推理过程中尝试去除冗余。然而,该过程通常依赖于固定阈值,这可能在标准视觉问答任务上取得可接受性能,但在OCR相关或细节敏感场景中表现不佳,限制了其实际应用。相比之下,VisionThink输入压缩的视觉 Token ,并使模型能够自主判断是否需要更高分辨率的图像。理想情况下,这种方法避免了任何性能下降。
集成潜力。作者提出的VisionThink本质上为图像阅读引入了一种新范式,该范式可以与现有的Efficient VLMs集成。在本文中,为了对VisionThink进行直接的验证,作者选择使用图像缩放来实现token压缩。作者相信采用更先进的token压缩技术可以进一步提高模型的直接回答准确率,从而提升其整体效率。更多讨论详见附录C。
5 相关工作
视觉语言模型推理。随着大语言模型推理能力的提升[17],许多研究致力于提升视觉语言模型的推理能力[90, 46, 41]。一种常见的方法是使用思维链(Chain-of-Thought, CoT) Prompt 来构建监督微调(SFT)数据集。然而,生成的思维链往往缺乏自然的人类认知过程,限制了其有效性和泛化能力。此外,受DeepSeek-R1[17]的启发,一些研究尝试将这种推理范式迁移到视觉任务[79, 59, 20, 77]。然而,当前大多数方法仍局限于视觉数学任务,未能泛化到通用的视觉问答(VQA)任务。相比之下,VisionThink通过利用大语言模型作为裁判(LLM-as-Judge)的策略,成功地将有效的强化学习应用于通用VQA。由于篇幅限制,关于高效视觉语言模型和基于大语言模型的推理的相关工作在附录A中给出。
6 结论
6.1 摘要
在这项工作中,作者介绍了VisionThink,一种用于通用视觉问答(General VQA)的新型范式,旨在提升效率和性能。通过首先处理下采样图像,并在需要时使用强化学习选择性地将其上采样到更高分辨率,VisionThink优化了计算资源,同时保持了准确性。借助“将大语言模型作为裁判”的策略和定制的 Reward 函数,VisionThink在多种视觉问答基准测试中超越了现有的最先进模型,特别是在需要细粒度细节的任务(如OCR)中表现尤为突出。作者相信VisionThink展示了强化学习在视觉语言模型中的潜力,并鼓励开发更有效率和更高效的AI系统。
6.2 局限性与未来工作
在本工作中,作者专注于2倍分辨率提升和最多两次对话的设置,并取得了令人满意的结果。然而,这一方法尚未扩展到灵活分辨率提升的设置。此外,结合更多视觉工具(如裁剪)将进一步提升效率和性能。再者,多轮(例如,超过5轮)图像工具调用在解决复杂视觉问题方面将获得更多收益。
参考
[1]. VisionThink: Smart and Efficient. Vision Language Model via Reinforcement Learning.
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









