






本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:DeCLIP突破CLIP局限 | 解耦注意力+双蒸馏机制,开集检测/分割全面超越DINO/SAM

精简阅读版本
本文主要解决了什么问题
-
1. 密集预测任务的局限性:CLIP等视觉语言模型在开集密集预测任务(如目标检测和语义分割)中表现不佳,因其图像Token难以有效聚合来自空间或语义相关区域的信息,导致特征缺乏局部区分性和空间一致性。
-
2. 领域偏移问题:直接将图像级模型(如CLIP)应用于密集预测任务时,由于局部特征表示的局限性,往往会导致性能下降。
-
3. 优化冲突:在统一架构内同时优化局部特征的空间相关性和视觉-语言语义对齐存在困难。
本文的核心创新是什么
-
1. DeCLIP框架:提出了一种解耦自注意力模块的方法,分别获取“内容”和“上下文”特征。“内容”特征通过与图像裁剪表示对齐来增强局部区分性,“上下文”特征在视觉基础模型(如DINO)的指导下学习以保留空间相关性。
-
2. 无监督微调方法:设计了一种简单而有效的无监督微调框架,通过解耦特征增强策略提升CLIP在密集预测任务中的性能。
-
3. 双蒸馏机制:结合自蒸馏和VFM蒸馏技术,分别优化局部判别能力和空间一致性能力,缓解了优化冲突。
结果相较于以前的方法有哪些提升
-
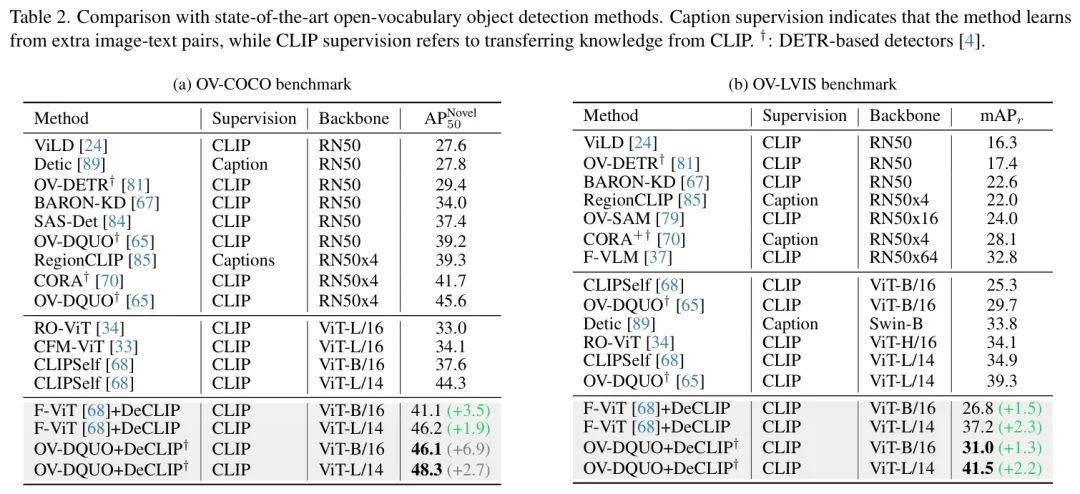
1. 目标检测任务:在OV-COCO和OV-LVIS基准测试中,DeCLIP显著提升了F-ViT和OV-DQUO基线模型的性能,分别提高了3.5/1.9 mAP和6.9/2.7 mAP。
-
2. 语义分割任务:使用DeCLIP作为主干网络的CAT-Seg模型在多个开集语义分割基准数据集上超越了现有SOTA方法,尤其是在ViT-B/16版本下几乎媲美更大规模编码器(如ConvNeXt-L)的效果。
-
3. 区域分类任务:在COCO-Panoptic验证集上,DeCLIP在不同分辨率下的区域识别性能始终优于现有方法,Top-1平均准确率(mAcc)显著提升。
局限性总结
-
1. 依赖教师模型选择:DeCLIP的性能在一定程度上依赖于所选VFM(如DINO、SAM、DINOv2)的特性,不同教师模型在区域分类和分割任务上的表现存在差异。
-
2. 计算资源需求:虽然DeCLIP是一种无监督微调方法,但其双蒸馏机制可能增加训练时间和计算成本。
-
3. 适用范围限制:尽管DeCLIP在开集密集预测任务中表现出色,但在特定场景(如极端低分辨率或高噪声环境)下的鲁棒性仍需进一步验证。
深入阅读版本
密集视觉预测任务因其依赖预定义类别而受到限制,这在视觉概念无界的实际场景中限制了其适用性。尽管像CLIP这样的视觉语言模型(VLMs)在开集任务中展现出潜力,但它们直接应用于密集预测时往往由于局部特征表示的局限性导致性能不佳。在本工作中,作者观察到CLIP的图像 Token 难以有效聚合来自空间或语义相关区域的信息,导致特征缺乏局部区分性和空间一致性。
为解决这一问题,作者提出了DeCLIP,这是一个通过解耦自注意力模块以分别获取"内容"和"上下文"特征的新型框架。"内容"特征与图像裁剪表示对齐以提升局部区分性,而"上下文"特征在视觉基础模型(如DINO)的指导下学习保留空间相关性。大量实验表明,DeCLIP在包括目标检测和语义分割在内的多个开集密集预测任务中,显著优于现有方法。
代码: https://github.com/xiaomoguhz/DeCLIP
1. 引言
在深度学习时代,目标检测[44, 55]和图像分割[12, 57]等密集预测任务取得了快速进展并得到广泛应用。然而,传统方法[7, 40, 91]仅能识别一组预定义的固定类别。这种限制阻碍了这些方法在实际场景中的应用,因为视觉概念的范畴几乎是无边界的。因此,开集方法[14, 67, 70, 82]受到越来越多的关注,这类方法旨在通过文本描述检测和分割任何类别的目标。
基于在图像-文本对上预训练的视觉-语言模型(VLMs)[13, 41, 52, 61]的成功,例如CLIP [52],研究行人开始利用这些模型进行开集密集预测任务。在这些方法中[8, 65, 67-69, 84],迁移学习方法[11, 30, 37, 65, 68, 78]表现出卓越的性能。这些方法利用VLM的图像编码器作为特征提取器,并专门训练轻量级任务特定组件。尽管使用VLM作为特征提取器因其全面的预训练而具有显著优势,但直接将这些图像级模型应用于密集预测往往会导致领域偏移问题[68, 70]。
CLIP在密集感知中的阻碍因素是什么?为了评估视觉语言模型在密集感知中的限制,作者分析了CLIP在不同层级的注意力图(图3(a))。作者的实验表明,CLIP的[CLS] Token 可能会干扰其他图像 Token 之间的相关性,导致在密集预测任务中表现不佳。
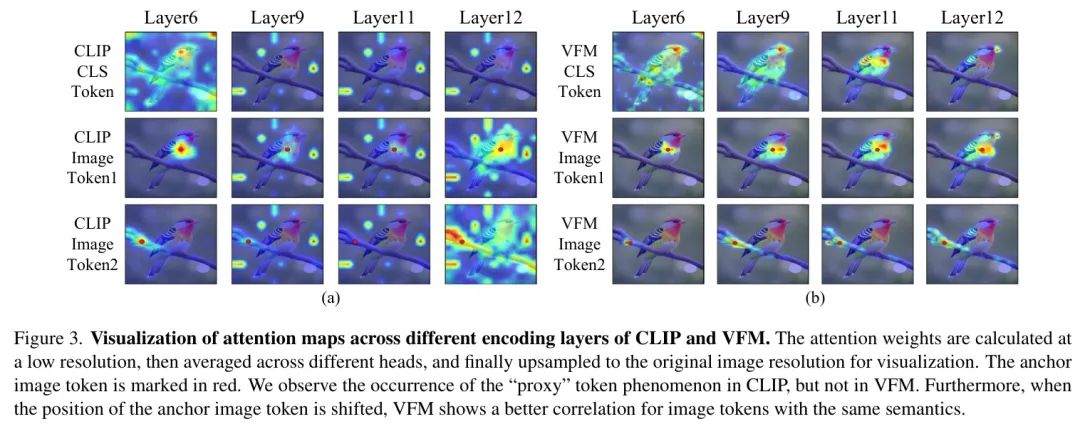
具体而言,作者观察到在更深层次(第9层之后),[CLS] Token 的注意力会从图像中的主要目标转移,并高度关注某些背景 Token ,如图3(a)第一行中的亮点所示。此外,图像 Token (图3(a)的第2行和第3行)表现出与[CLS] Token 类似的行为,无论其位置如何,都高度关注某些背景 Token 。
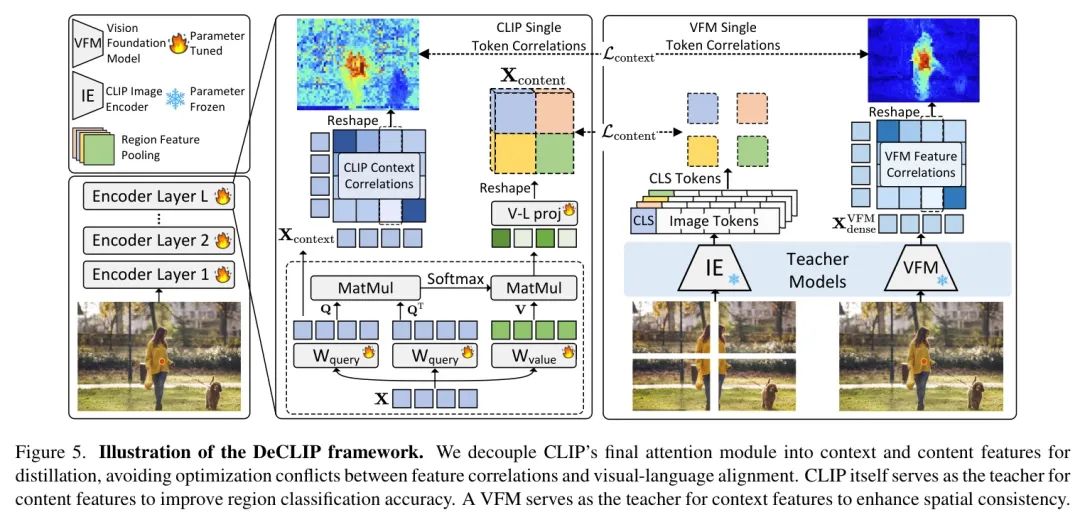
这一观察揭示了CLIP在密集预测任务中表现不佳的原因:其图像 Token 无法从空间或语义相关的区域聚合信息,导致密集特征缺乏局部区分性和空间一致性。如图2(a)所示,直接在COCO数据集上使用CLIP特征在开集区域分类和语义分割任务中表现相对较差。为了解决这个问题,一个直观的方法是通过微调来增强CLIP的局部表示。然而,在统一架构内平衡局部特征空间相关性和视觉-语言语义对齐的优化成为一项新的挑战。因此,能否将CLIP的特征解耦,并在统一架构内应用不同的引导约束以获得多样化的特征?作者的解决方案。为了应对这些挑战,作者提出了DeCLIP,一种旨在增强CLIP局部特征的区分性和空间一致性的通用无监督微调方法。其核心思想是解耦CLIP的自注意力模块,并分别从不同的教师模型中学习。
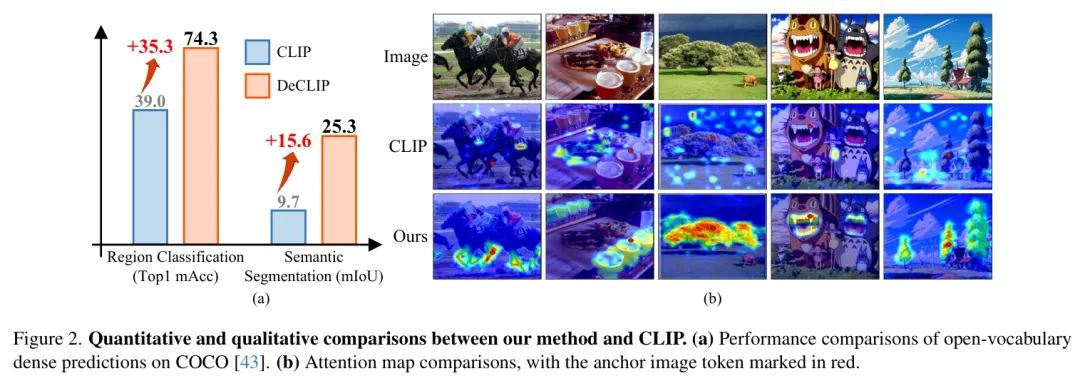
具体而言,DeCLIP将selfattention模块中的特征解耦为"内容"和"上下文"两个分量。"内容"特征负责局部判别性,通过将池化区域特征与其对应的图像裁剪[CLS]表示进行对齐进行微调。与此同时,"上下文"特征负责空间一致性,从视觉基础模型(VFMs)生成的特征相关性中学习。这种解耦蒸馏设计有效缓解了优化冲突,提升了将CLIP应用于下游开集密集预测任务时的泛化能力。如图2所示,DeCLIP在局部判别性和空间一致性方面显著优于CLIP。
总而言之,作者的贡献如下:
-
• 作者分析了CLIP,发现其在开集密集预测中的局限性源于图像 Token 无法从空间或语义相关的区域聚合信息。
-
• 为解决此问题,作者提出了DeCLIP,一个简单而有效的无监督微调框架,通过解耦特征增强策略来提高CLIP局部特征的判别性和空间一致性。
-
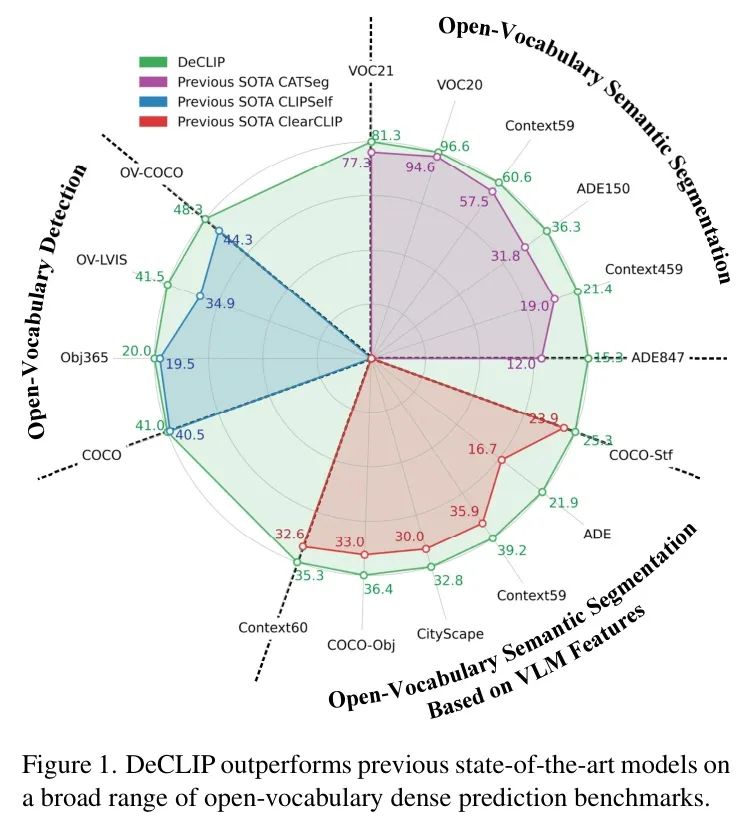
• 大量实验表明DeCLIP可以很好地应用于主流开集密集预测任务,包括目标检测和语义分割。如图1所示,DeCLIP在广泛的基准测试中优于现有最优方法,在所有评估的任务领域均取得了更优的性能指标。
2. 背景与动机
在以下部分,作者在2.1节中简要概述了与本项研究相关的基础概念,并在2.2节中重点介绍了重要发现,这些发现为DeCLIP提供了宝贵的见解。
2.1. 前提
对比语言图像预训练(CLIP)[52] 基于两个编码器,一个用于图像,一个用于文本。CLIP的视觉编码器可以是卷积神经网络(CNN)系列[27, 45]或视觉Transformer(ViT)[19],文本编码器是Transformer[62]。本文聚焦于采用ViT架构的CLIP模型,该模型采用[CLS] Token 来表示图像的整体特征。CLIP通过最大化匹配图像-文本对中[CLS] Token 与文本特征之间的余弦相似度,并最小化不匹配对之间的相似度来学习视觉-语言对齐。


-
联合微调。这些方法在训练特定任务组件的同时微调CLIP [14, 30, 31, 39, 42, 72, 77]。例如,CAT-Seg [14] 提出了一种基于ViT CLIP的注意力微调策略,该策略对未见过的类别具有良好的泛化能力。MAFT [30] 利用注意力偏差来微调CLIP进行 Mask 分类。
-
• 预微调。这些方法直接使用成本效益高的技术[49, 68-70, 85]对CLIP进行微调,这与本文DeCLIP更为接近。如图4(a)所示,CLIM[69]采用马赛克增强技术将多张图像拼接成一张图像,使每张子图像都可作为区域文本对比学习的伪区域。CLIPSelf[68]通过最大化其区域表示与相应图像裁剪表示之间的余弦相似度来提高CLIP的区域分类精度,如图4(b)所示。
2.2. 关键观察
尽管第2.1节中微调方法的两种类别取得了令人鼓舞的结果,但它们仍然存在一定的局限性。联合微调方法通常针对特定任务或模型,并且严重依赖于密集预测任务的劳动密集型标注。另一方面,预微调方法具有更广泛的应用性。然而,其区域级微调技术在需要像素级细节的图像分割任务中仍然存在局限性。为了解决这个问题,作者研究了将像素级细节整合到CLIP的预微调中的可行性,使其能够更好地与开集密集预测任务相匹配。在下文中,作者首先分析了CLIP在不同层级的注意力图。
" Agent "token现象。如图3(a)所示,作者发现CLIP的浅层中,CLIP的[CLS]token的注意力权重广泛分布在整个图像上(即第6层)。然而,在深层中,[CLS]token将其注意力从图像中的主要目标移开,转而关注特定的token,如图像背景中的亮点所强调的那样。此外,作者还发现图像token(第2行和第3行)表现出与[CLS]token相似的行为,它们对背景中的某些token表现出高度注意力,无论这些token的位置如何。
这些背景 Token 可以作为[CLS] Token 的" Agent "。这表明这些 Token 从其他图像 Token 中聚合了关键信息,使[CLS] Token 能够通过总结这些内容形成近似"全局视角",从而促进图像分类。然而,这些" Agent " Token 对图像 Token 之间的特征相关性产生负面影响。如图3(a)所示,当作者移动 Anchor 图像 Token 的位置(从鸟到树枝),作者观察到新的图像 Token 仍然高度关注" Agent " Token 。这导致共享相同语义的图像块之间缺乏相关性,这对密集预测任务是有害的。
VFMs表现出更好的密集相关性。考虑到阻碍CLIP在密集感知任务中有效性的内在限制,作者观察到,例如DINO系列[5, 51]等VFMs在自监督方式下训练,以及SAM系列[36, 54]等VFMs在大规模分割数据上训练,能够提取具有强空间一致性的特征,如图3(b)所示。
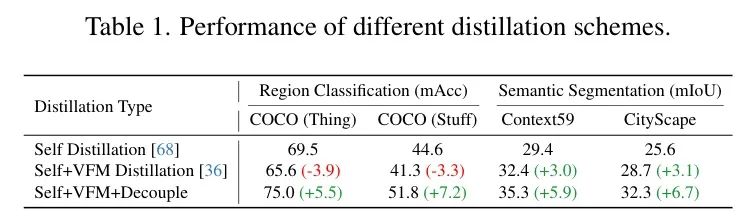
特别是,VFMs的注意力图并未表现出CLIP中观察到的" Agent " Token 现象。此外,当作者改变 Anchor 图像 Token 的位置时,VFM对于具有相同语义的图像 Token 显示出更好的相关性。因此,作者考虑是否可以将VFMs纳入预微调过程,以进一步提高CLIP的特征相关性。然而,这种直接的方法未能取得令人满意的结果。同时进行VFM蒸馏和自蒸馏会导致区域分类性能下降,如表1(第2行)所示。作者假设这一观察结果源于空间特征相关性和视觉语言对齐具有不同的优化焦点,在单个模型内同时优化它们会导致权衡。
3. 方法
通过上述分析,作者发现CLIP在密集预测任务中的表现不佳,因为其图像token无法有效从语义相关的区域聚合信息。对视觉特征映射(VFMs)的注意力图观察启发了作者将它们融入CLIP的预微调过程中。考虑到特征相关性和视觉语言对齐之间的优化冲突,作者针对CLIP应用了一种解耦特征增强策略。
在本节中,作者介绍了DeCLIP,这是一个用于将CLIP模型适配于密集预测任务的无监督微调框架。首先,作者在3.1节中解释了如何将CLIP的自注意力机制解耦为“内容”和“上下文”两个组成部分,然后在3.2节中描述了这些组成部分如何通过知识蒸馏从不同的“教师”模型中学习。
3.1. 解耦注意力


如第2.2节所述,视觉特征映射(VFM)对于具有相同语义的图像 Token 表现出强相关性,因此作者将其作为指导来改进CLIP的局部特征空间一致性。同时,作者采用自蒸馏技术作为指导来增强CLIP区域特征的视觉语言对齐。
如表1第3行所示,这种解耦优化显著提高了CLIP特征的空间判别性和空间一致性,从而同时提升了区域分类精度和语义分割性能。
3.2. DeCLIP

内容特征蒸馏。如图5所示,DeCLIP中的第一个教师模型本身就是自身,这被称为自蒸馏[9, 49, 50, 68]。作者采用图像块处理方法,将学生模型特征图的区域表示与教师模型相应的图像裁剪表示(即[CLS] Token )进行对齐。


4. 实验
4.1. 数据集与评估
作者在多个开集密集预测基准上进行了广泛的评估,涵盖目标检测、语义分割以及基于视觉语言模型特征的分割。由于篇幅限制,数据集的详细描述、评估指标和实现细节将在附录中提供。
4.2. 基准测试结果
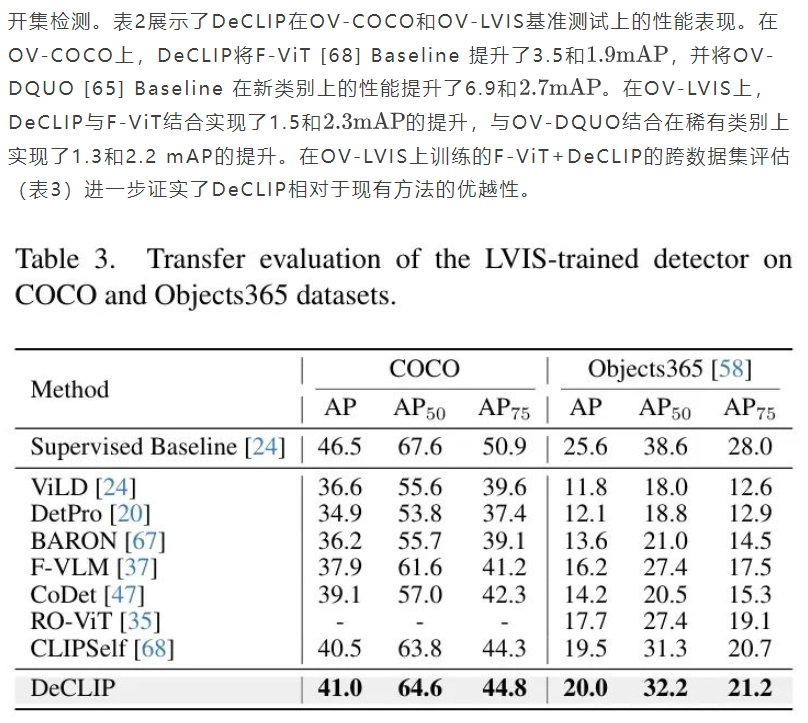
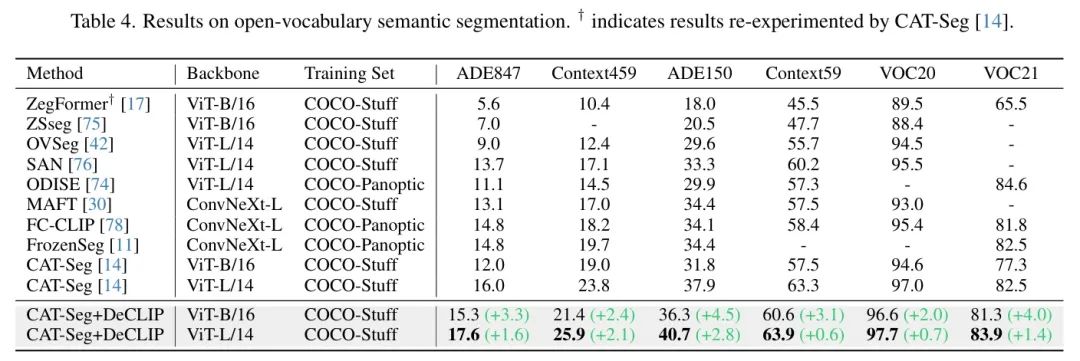
开集语义分割。表4展示了使用DeCLIP作为主干网络的CAT-Seg[14]模型在多个开集语义分割基准数据集上的性能表现。结果表明DeCLIP显著提升了所有数据集上的分割性能。值得注意的是,即使使用ViT-B/16版本的DeCLIP,CAT-Seg也几乎超越了所有现有采用更大规模编码器(如ConvNeXt-L)的SOTA方法。当采用ViT-L/14版本的DeCLIP时,该模型在开集语义分割任务中取得了新的SOTA结果。
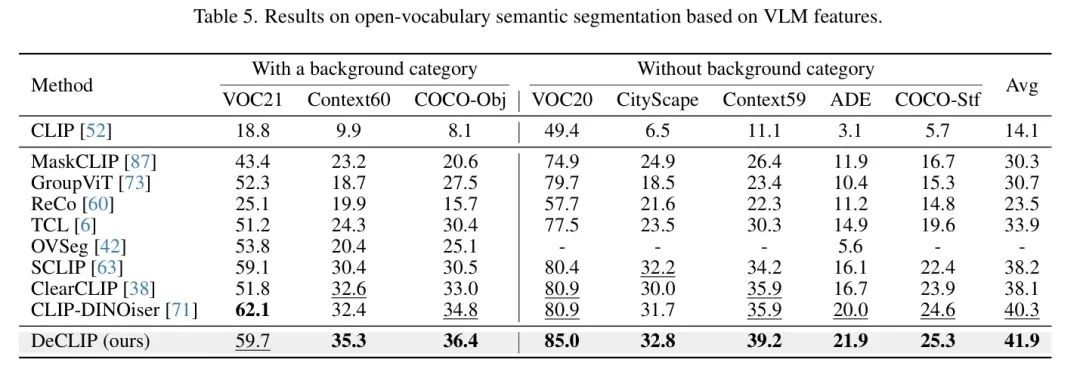
基于VLM特征的开集语义分割。遵循现有方法[38, 59, 63],在本实验中,作者将特征图中的每个像素分配与其具有最高余弦相似度的类别。低分辨率预测结果被上采样至原始分辨率以获得最终分割图。如表5所示,DeCLIP在八个基准测试的平均mIoU方面优于所有现有方法,突显了DeCLIP在提高VLM特征的判别性和空间一致性方面的有效性。
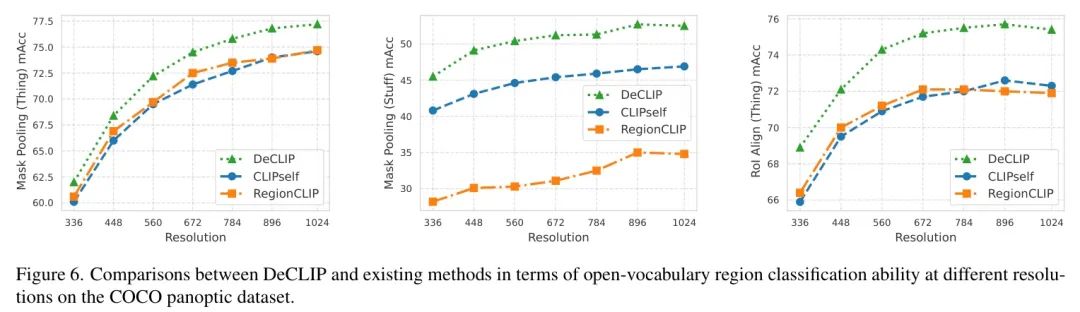
开集区域分类。作者在COCO-Panoptic验证集上评估了DeCLIP、RegionCLIP [85] 和 CLIPSelf [68] 在不同分辨率下的区域分类性能。利用RoI Align [28] 和 Mask Pooling,作者基于标注的边界框和 Mask 从特征图中提取局部特征,并根据最大余弦相似度分配类别。如图6所示,Top-1平均准确率(mAcc)结果表明,DeCLIP在所有分辨率下的区域识别方面始终优于现有方法。
4.3. 消融研究
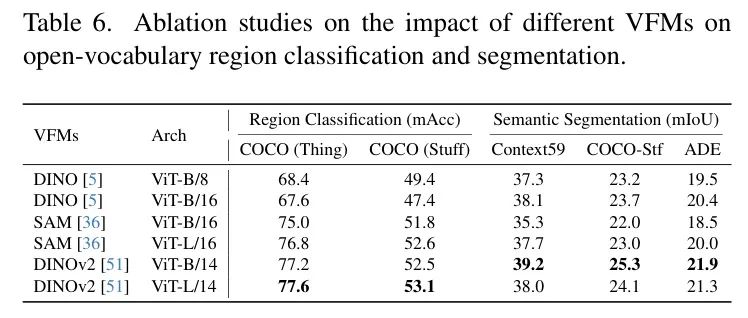
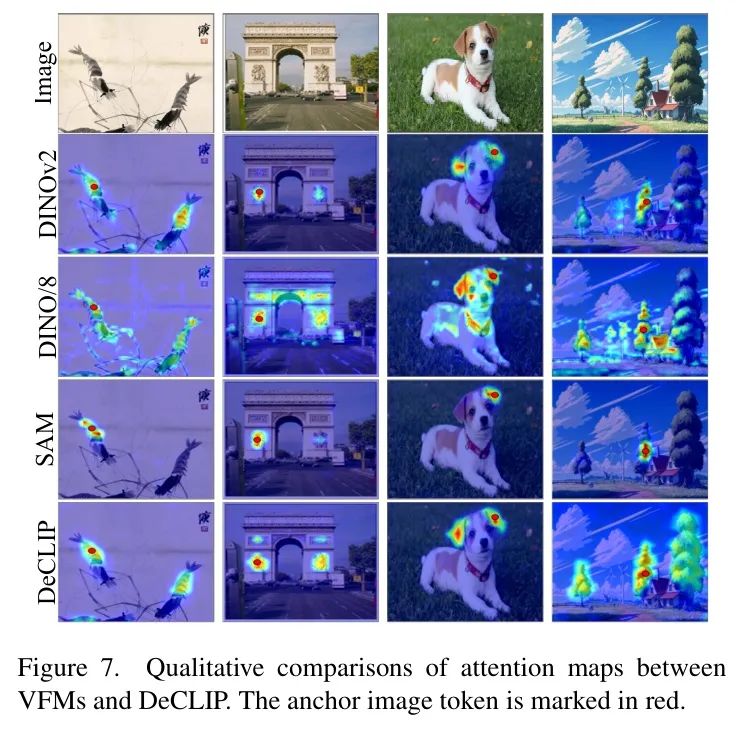
VFMs的影响。作者分析了不同VFM配置对DeCLIP性能的影响。如表6所示,从DINO [5]蒸馏的DeCLIP在分割方面表现中等,但在区域分类方面落后于SAM [36, 54]和DINOv2 [51]。从SAM蒸馏的DeCLIP在区域分类方面表现出色,但与DINO相比,其分割性能较低。DINOv2在区域分类和分割方面均取得了平衡。
定性结果。图7展示了DINO、SAM、DINOv2和DeCLIP之间的注意力图视觉比较。实验结果表明,DeCLIP能够有效地聚焦于与 Anchor 图像 Token 在空间或语义上相关联的区域。此外,该实验揭示了为何从DINOv2蒸馏的DeCLIP效果最佳:SAM缺乏语义关联能力,而DINO则无差别地关注图像中的所有主要目标。
5. 结论
本文从注意力图的角度分析了CLIP在密集预测任务中的局限性。作者观察到CLIP的[CLS] Token 对图像 Token 的注意力图产生负面影响。
为解决这一问题,作者提出了DeCLIP,一种解耦特征增强策略。在开集密集预测基准上的大量实验结果表明,DeCLIP优于现有最优方法,在所有评估的任务领域均取得了优异性能。
参考
[1]. DeCLIP: Decoupled Learning for Open-Vocabulary Dense Perception
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









