






本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:视觉Transformer革命 | SparseFormer 横扫高分辨检测,跨切片 NMS 驯服巨幅尺度鸿沟

导读
近年来,使用像素级图像和视频捕捉系统以及具有高分辨率宽视角(HRW)的基准测试越来越多。然而,与MS COCO数据集中的近距离拍摄不同,更高的分辨率和更宽的视野带来了独特的挑战,如极端Sparse性和巨大的尺度变化,导致现有的近距离检测器不准确且效率低下。
在本文中,作者提出了一种新颖的模型无关Sparse视觉Transformer,称为SparseFormer,以弥合近距离和HRW拍摄之间的目标检测差距。所提出的SparseFormer选择性地使用注意力 Token 来仔细检查可能包含目标的Sparse分布窗口。通过这种方式,它可以通过融合粗粒度和细粒度特征来共同探索全局和局部注意力,以处理巨大的尺度变化。SparseFormer还受益于一种新颖的跨切片非极大值抑制(C-NMS)算法,以精确地定位噪声窗口中的目标,以及一种简单而有效的多尺度策略来提高准确性。
在两个HRW基准测试PANDA和DOTA-v1.0上进行的广泛实验表明,所提出的SparseFormer在检测精度(高达5.8%)和速度(高达3倍)方面显著优于现有方法。
1 引言
目标检测在过去十年中一直是计算机视觉领域的一项具有挑战性但基础的任务。如MS COCO[28]等近距离场景已经展现出令人印象深刻的性能,并在实际应用中取得了成功。然而,随着成像系统的发展和无人机等新应用需求的出现,检测具有平方公里场景和吉比特级分辨率的超高分辨率宽幅(HRW)图像中的目标引起了越来越多的关注。
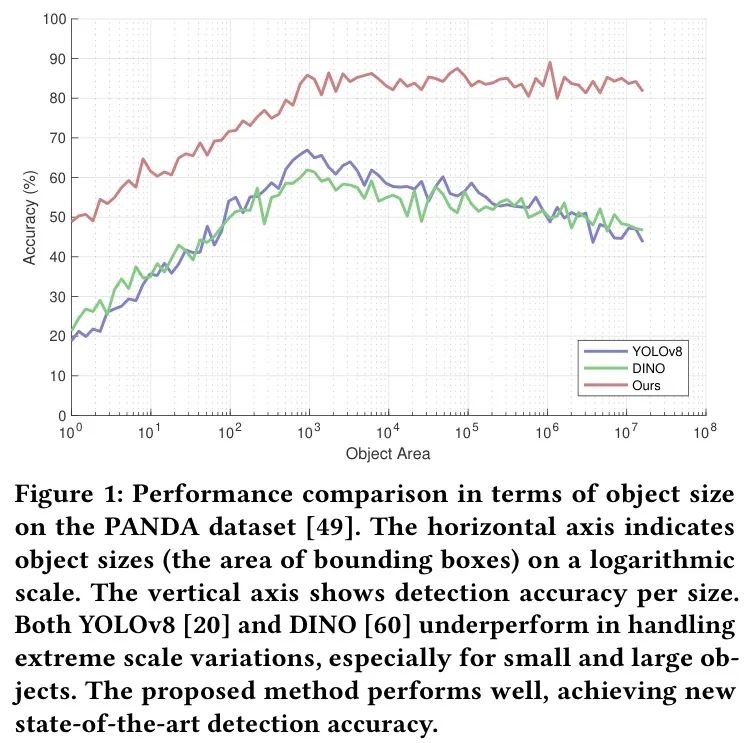
在HRW照片中使用近距离检测器检测物体并不有效,这是因为HRW照片具有一些独特的特性,如PANDA 和DOTA 所发现,与MS COCO等近距离照片相比。最显著的挑战是HRW照片中的信息Sparse,物体通常只占据图像的不到5%。这使得检测器难以从背景噪声中提取关键特征,导致在训练和测试过程中背景中出现误报,物体区域中出现漏检。第二个挑战是HRW照片中物体的尺度变化,变化幅度可达100倍。依赖于感受野和 Anchor 点固定设置的检测器无法适应这些极端尺度,如图1所示。例如,YOLOv8 在检测小物体方面表现不佳。虽然DINO 有所改进,但它仍然难以适应这种夸张的尺度变化,导致对大物体的检测效果不佳(图2)。此外,典型的两阶段下采样方案 [5, 10, 21, 34] 未能检测到更多的小物体。

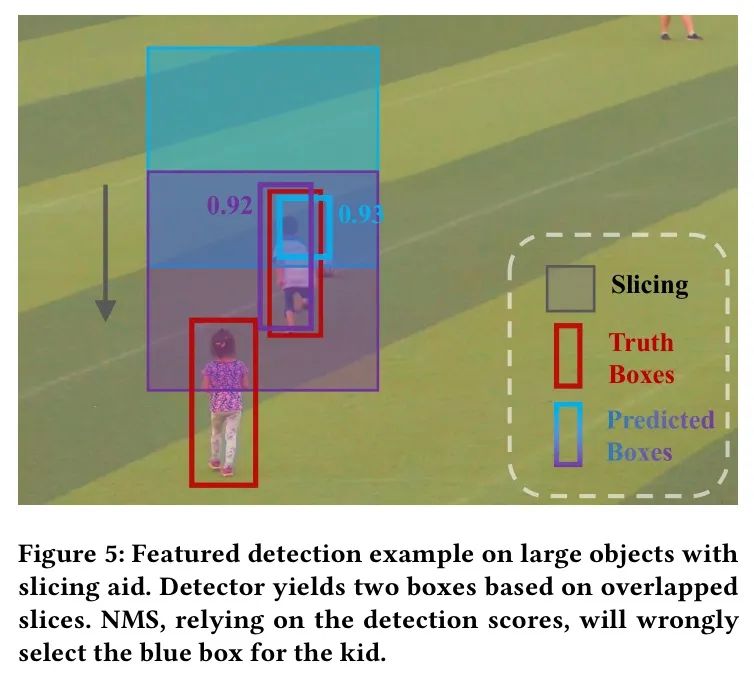
切片策略[1]在使用NMS合并预测框时可能导致框不完整,如图5所示。因此,弥合近距离和HRW镜头中目标检测之间的差距至关重要。
受近期提高目标检测精度的先进技术[33, 36, 42, 45, 46, 53]的启发,作者提出了一种针对HRW镜头的新型检测器,称为SparseFormer。SparseFormer通过选择性使用注意力 Token 来关注图像中物体Sparse分布的区域,从而促进细粒度特征的提取。为实现这一目标,它学习了一个ScoreNet来评估区域的重要性。通过检查所有区域的重要性得分的方差,SparseFormer优先考虑能够捕捉丰富细粒度细节的区域。因此,它可以专注于复杂的图像区域,而不是不那么重要的区域(例如,背景中的平滑内容)。同时,它将每个HRW镜头划分为非重叠窗口以提取粗粒度特征。与原始Vision Transformer[8]的接受场策略有相似精神,作者提出的SparseFormer结合了粗粒度和细粒度特征,比Swin Transformer实现了更高的效率。这极大地有助于处理大规模变化并准确检测大物体和小物体。
作者进一步提出了两种创新技术来提高对大规模变化检测的准确性。首先,作者观察到传统的非极大值抑制(NMS)仅参考置信度分数来合并检测结果,导致 oversized 目标的边界框不完整。
为了解决这个问题,作者提出了一种新颖的跨切片NMS方案(C-NMS),该方案优先考虑置信度高的较大边界框。所提出的C-NMS方案显著提高了 oversized 目标的检测准确性。其次,作者采用多尺度策略来提取粗粒度和细粒度特征。多尺度策略扩大了感受野,提高了对大目标和小目标的检测准确性。
总之,本工作的主要贡献如下:
-
• 作者提出了一种基于Sparse视觉Transformer的新型检测器,用于处理HRW图像中的大规模变化。
-
• 作者进一步采用跨窗口NMS和多尺度方案来提升对大、小目标的检测效果。
-
• 作者在两个大规模HRWshot基准数据集PANDA和DOTA-v1.0上对方法进行了广泛验证。SparseFormer在性能上大幅超越了现有技术水平。
2 相关工作
近距离拍摄检测模型。大多数常见的目标检测数据集,如PASCAL VOC [9] 和 MS COCO [28],收集了高分辨率且包含近距离拍摄的图像,这对目标检测的发展做出了重大贡献。基于检测Head,文献可以大致分为两类:单阶段检测器和双阶段检测器。双阶段目标检测的主要目标是准确性,它将检测过程描述为“由粗到精”的过程 [3, 12, 13, 18, 39]。另一方面,单阶段检测器在速度方面具有优势,例如YOLO [37]。后续工作尝试进行了改进,如增加 Anchor 点、改进架构和更丰富的训练技术 [11, 29, 38]。总之,当前的检测器在近距离拍摄中表现出极高的速度和准确性。
高分辨率宽视角检测模型。成像系统的引入导致了用于高分辨率宽视角(HRW)检测的新基准PANDA [49] 的开发。这个基准最近受到了广泛关注。以往关于吉像素级检测的研究主要集中在通过 Patch 选择或排列来实现更低延迟 [5, 10, 23, 24, 34]。然而,它们无法解决HRW检测中面临的独特挑战。一些工作在 Patch 上使用Sparse策略 [36]、自注意力头 [33] 和Transformer块 [33] 进行图像分类。PnP-DETR [46] 利用投票和池化采样器从 Backbone 网络中提取图像特征,并将Sparse Token 输入到注意力编码器。这种方法在目标检测、全景分割和图像识别方面显示出有效性。然而,对 Backbone 网络上的Sparse采样尚未得到充分研究。DGE [42] 是视觉Transformer的插件,但它不够灵活,无法扩展到基于ConvNet的模型或使用任意大小的图像作为输入。因此,如何设计一个灵活且模型无关的架构以用于HRW检测的目标检测问题仍然是一个未充分探索的领域。
Transformer Backbone。Transformer在自然语言处理(NLP)领域取得了成功,其在视觉任务上的潜力也引起了广泛关注。其中一个例子是视觉Transformer(ViT)[8],它使用纯Transformer模型进行图像分类,并显示出有希望的结果。然而,ViT处理高分辨率图像的计算成本不切实际。已经尝试了多种方法来降低ViT模型成本,包括基于窗口的注意力[30]、自注意力中的下采样[47, 50]和低秩投影注意力[52]。其他工作则使用Sparse策略在图像块[36]、自注意力头[33]和Transformer块[33]上进行图像分类。不幸的是,这些方法在检测高分辨率宽视角中的目标时,准确性显著下降。
3 提出方法
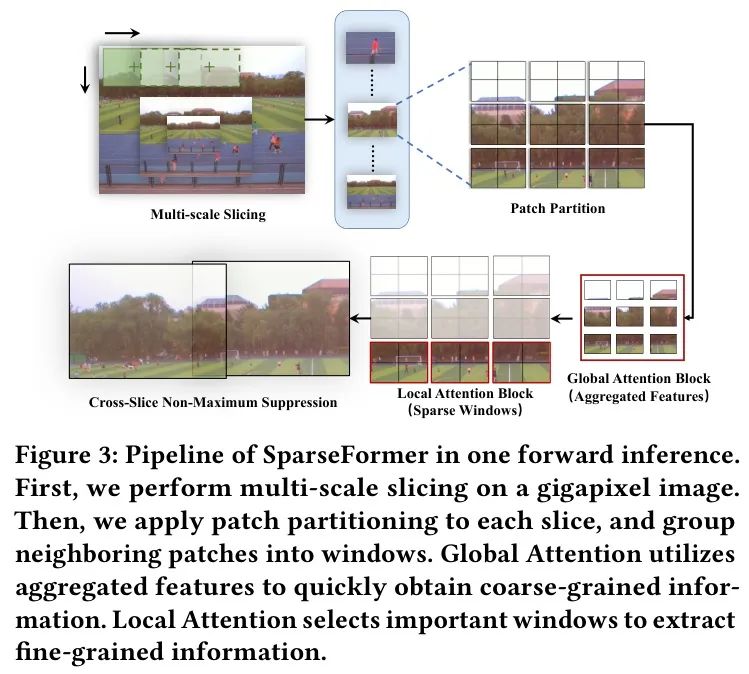
作者通过提出Sparse视觉Transformer来解决HRW检测的独特挑战。该模型能够有效地从Sparse信息中提取有价值特征,同时扩大感受野以处理大规模变化。为了解决交切片区域中不完整的大物体问题,作者对传统的非极大值抑制(NMS)进行了修改。此外,作者引入了基于HRW的增强方法,用于训练和推理阶段,以提高大物体和小物体的检测精度。流程图如图3所示。
3.1 SparseFormer概述
理想的视觉模型应能够利用有限的计算从Sparse数据中提取有意义的信息,就像作者的眼睛倾向于关注有价值区域而不是不重要背景信息一样。为了实现这一点,作者设计了一种名为SparseFormer的新型Sparse视觉Transformer。它能够动态选择关键区域,并启用动态感受野以覆盖各种尺度的目标。SparseFormer的整体框架如图4所示。
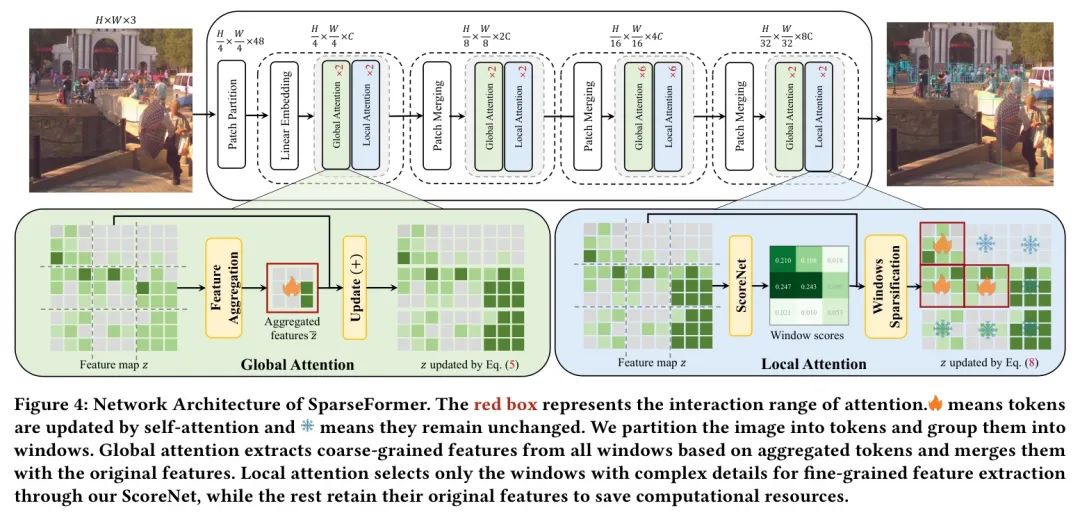
受Swin Transformer的启发,作者将输入图像分割成非重叠的块以生成 Token 。SparseFormer由四个阶段组成,它们协同工作以产生自适应表示。每个阶段都以一个块合并层开始,该层将每个2×2相邻块组的特征连接起来。然后,使用线性层将这些连接的特征投影到其维度的一半。
SparseFormer的每个阶段都围绕设计用于捕捉不同尺度上的长程和短程交互的注意力块展开。为了实现这一点,作者结合了标准自注意力Transformer块和Swin Transformer块的优势。因此,作者开发了两种不同类型的Sparse风格块。一种用于在粗粒度上捕捉长程交互,而另一种则专注于在更精细的尺度上捕捉短程交互。
为了便于这种方法的实现,作者引入了窗口的概念,将每个特征图划分为等间距的窗口。每个窗口内的操作被认为是“局部”的,而涵盖所有窗口的操作则是“全局”的。作者更详细地概述了全局和局部注意力块。作者使用标准的多头自注意力(MSA)[43]和聚合特征的多层感知器(MLP)模块,或仅使用卷积层来构建全局块,具体细节见第3.2节。作者通过在Swin Transformer [30]块前后添加Sparse化和逆Sparse化步骤来构建局部块,如第3.3节所述。与先前的工作[46, 55]不同,作者并没有为全局和局部注意力构建独立的分支。相反,局部注意力被放置在全局注意力之后,以获得更多细节,而不是不同的特征。当一个阶段有多个块时,全局注意力块(G)和局部注意力块(L)的顺序遵循“GGLL”的模式。
3.2 全局注意力机制在聚合特征上的应用
特征聚合。全局注意力旨在通过长距离交互捕捉粗粒度特征。因此,作者通过在每个窗口中Sparse化特征来生成低分辨率信息。如图4所示,作者以全局注意力模块作为每个阶段的开始。该模块的主要功能是聚合每个窗口的特征。

3.3 Sparse窗口上的局部注意力
基于方差评分。请注意,每个窗口的粗粒度特征可以实现高效率。然而,作者仍然需要细粒度特征来提取目标细节,以准确检测目标。因此,作者根据其低信息含量丢弃某些窗口以减少计算。作者的目标是识别需要进一步局部关注的窗口,因为这些窗口 Level 的特征无法代表其内部 Token Level 的特征。

基于平移窗口的注意力。作者利用了首次在Swin Transformer中提出的基于平移窗口的注意力模块。连续的局部块可以表示为:

3.4 跨切片非极大值抑制
在HRW射击处理中,切片策略为每个切片生成候选框,这些候选框随后必须合并成一个互不冲突的框集。然而,使用非极大值抑制(NMS)来选择得分最高的框可能导致在目标位于多个切片的边缘区域时出现不完整的框(更详细的解释和可视化表示,请参阅图5)。为了解决这个问题,作者提出了一种跨切片非极大值抑制方法。
抑制(C-NMS)策略,如图1所示,该策略优先考虑多个切片中面积最大的框,而不仅仅是最高分数的框。C-NMS算法包括两个阶段:局部抑制阶段和跨切片抑制阶段。
3.5 多尺度训练与推理

4 实验
4.1 效果评估
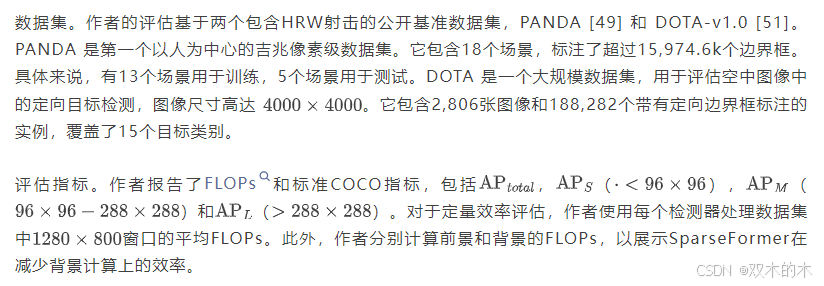
实现细节。作者使用MMDe.tection [4]实现检测器。为确保公平比较,作者在四个不同的 Backbone 网络上评估这两个检测器,包括Swin、DEG以及作者自己的专有设计,所有配置均使用相同数量的超参数(例如,深度、嵌入维度、多头数量)。所有模型均从头开始训练36个epoch,与[17]中的观察结果一致。
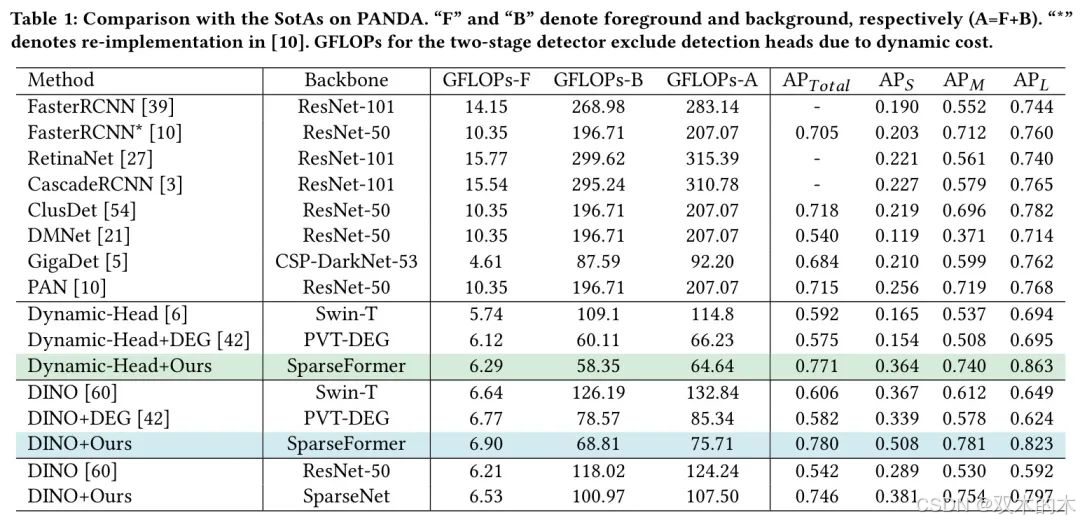
PANDA上的结果。作者将SparseFormer与不同保持率k与当前最先进的方法在首个吉比特级数据集PANDA上进行比较,该数据集不仅具有宽视场(FoV)的挑战,还具有超高分辨率。结果如表1所示。


4.2 消融研究
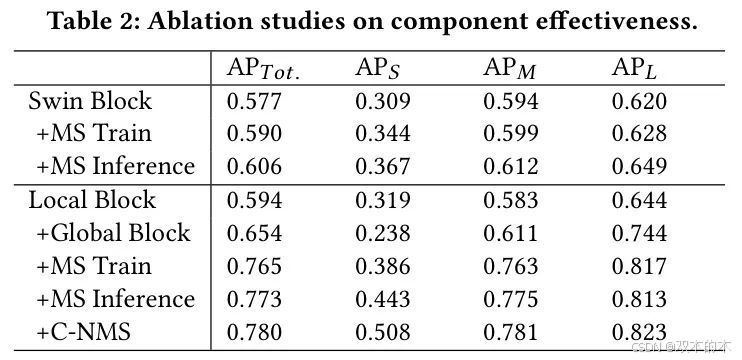
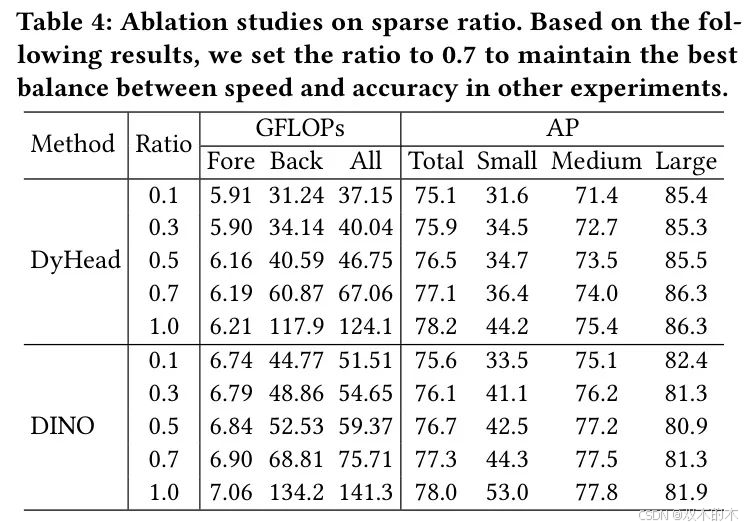
组件有效性。作者研究了全局块、C-NMS、多尺度训练(MS Train)和多尺度推理(MS Inference)的有效性。在PANDA数据集上,以k=0.7进行评估。如表2所示,所有组件都能显著提升性能,同时增加的额外成本也表明,作者的策略对于高分辨率宽视角(HRW)图像中的目标检测是有益的。


4.3 边缘设备比较
HRW图像通常由边缘设备如无人机捕获。无人机检测器通常无法在大型计算设备上运行,而是运行在低功耗的边缘设备上。由于在边缘设备上通常难以量化FLOPs,作者使用NVIDIA AGX Orin(最大功率60W)来评估每个检测器在PANDA的千兆像素级图像上的平均推理时间,结果如表6所示。
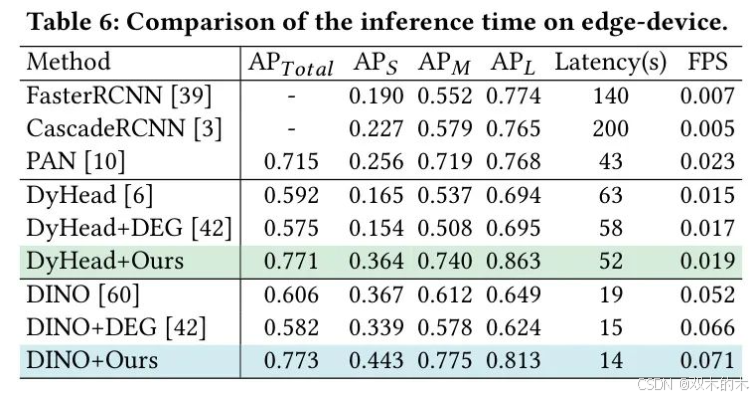
值得注意的是,与先前方法相比,SparseFormer可以大幅减少推理时间。SparseFormer比PAN快3倍,AP提高了5.8%。由于 Head 结构的复杂性,作者可以看到dynamichead的推理速度并不理想。相反,DINO比先前工作显示了有希望的FPS,速度提升更为明显。与竞争方法DEG相比,SparseFormer在更快的速度下实现了更好的性能。
4.4 针对模型的无关性研究
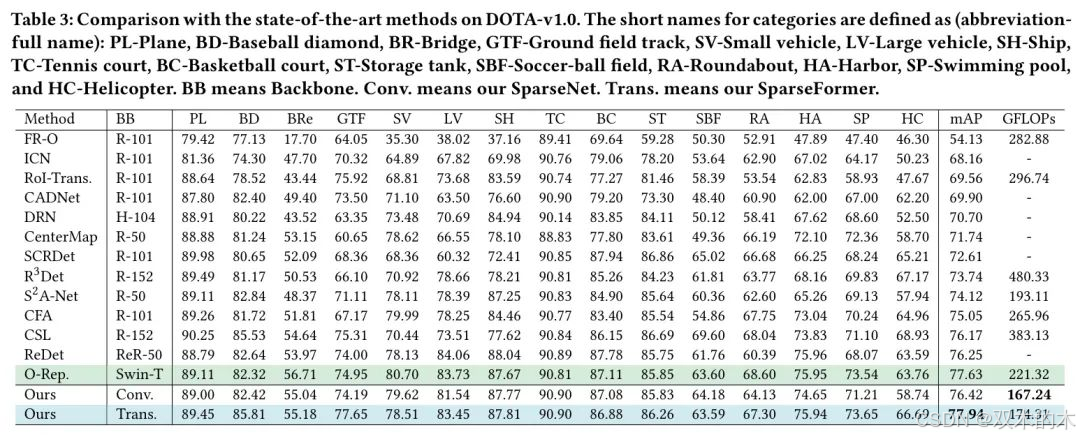
值得注意的是,作者的策略是模型无关的,能够与ConvNet或Transformer架构无缝集成。这种灵活性导致了SparseNet和SparseFormer的诞生。在先前提到的SparseFormer的基础上,作者进行了创新,将每个自注意力模块替换为卷积层。如表1和表3所示,SparseNet的表现不仅与著名的ResNet相当,而且更具竞争力。
特别值得一提的是,SparseNet将GFLOPs减少了高达56%,同时与CSL相比提高了准确率,在DOTA数据集上实现了最低的GFLOPs,这突显了它在复杂计算任务中的高效性和有效性。
4.5 Sparse窗口的可视化
为了更好地理解窗口Sparse化的工作原理,作者在图7中可视化了每个阶段的选定窗口。红色区域代表得分较高的区域,而蓝色区域代表得分较低的区域。SparseFormer将对得分较高的区域进行细粒度特征提取。这一插图突出了在背景区域和低熵前景上减少计算的优势。此外,结果验证了方法的有效性。PANDA和DOTA数据集关注不同的目标目标,它们共同的特点是包含大规模的背景区域,这使得Sparse化方法特别相关。作者相信,这种方法不仅将有助于HRW镜头中的目标检测,还将有助于各种其他视觉任务。

5 结论
作者引入了SparseFormer,这是一种基于Sparse视觉Transformer的检测器,专为HRW镜头设计。它利用选择性 Token 利用来提取细粒度特征,并聚合窗口内的特征以提取粗粒度特征。细粒度和粗粒度的结合有效地利用了HRW镜头的Sparse性,便于处理极端尺度变化。作者的Crossslice NMS方案和多尺度策略有助于检测超大和超小物体。
在PANDA和DOTA-v1.0基准上的实验表明,与现有方法相比,SparseFormer在HRW镜头目标检测方面取得了显著的改进,推动了该领域的最先进性能。
参考
[1]. SparseFormer: Detecting Objects in HRW Shots via Sparse Vision Transformer
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









