






本文来源公众号“Datawhale”,仅用于学术分享,侵权删,干货满满。
原文链接:DeepSeek R1 最新全面综述,近两个月的深度思考!
本文是《2025 iFLYTEK 开发者TALK 杭州站《DeepSeek深度技术解析》分享的文字版。由于时间关系,实际分享是本文的简化版。文字内容是近半个月陆陆续续记录的一些阅读笔记和思考,中途接到分享邀请(还好有点积累,不然怕是难顶doge),成稿于分享后。
分享PPT:
https://github.com/datawhalechina/hugging-llm/tree/main/resources
距离2022年底ChatGPT发布开启LLM时代才过去两年多一点时间,刚进入2025年,DeepSeek-R1就将LLM真正推向了深度思考时代。
两年多的高速发展,前所未有的按周迭代,如今想来都一阵恍惚。2023年是LLM最快速发展的一年,被称为LLM元年,新的开发范式出现(感兴趣的读者可以关注HuggingLLM(https://github.com/datawhalechina/hugging-llm)),全民AI浪潮涌现。2024年,基于LLM的应用已经开始成熟,Agent百花齐放,进入元年,各种应用层出不穷,一个人公司成为可能。
当我们以为LLM基本就这样按部就班向”应用“时,R1出现了,它发迹于OpenAI-o1,但超越了o1。关于o1,我的观点和OpenAI前首席研究官Bob的观点一致:它的目标是解决复杂问题,大多数人日常工作中并不会遇到需要o1的需求(可以参考关于AI前沿的思考(https://yam.gift/2024/12/20/NLP/2024-12-20-Think-About-AI-and-Related/))。但是R1提升了LLM的整体能力,让模型真正在推理时进行自我反思和验证,这当然适用于复杂问题,但日常工作很多场景也能受益,AI更加像人。我觉得这是R1对整个行业的贡献,其作用不亚于ChatGPT的发布。
DeepSeek-R1:LLM进入深度思考时代
首先,我们来解读R1的论文,这篇论文本身不复杂,条理很清晰。论文核心内容可以概括为三个部分:R1-Zero、R1和蒸馏。各部分都可以简单概括为一句话。
-
R1-Zero=Pretrain(DeepSeek-V3-Base)+RL(GRPO),证明Pure Rule 的 RL也有效,表现出自我验证、反思、和生成长COT的能力。但有可读性差、语言混合问题。
-
R1=Pretrain+Cold-Start(SFT)+RL(提升推理能力)+生成数据和SFT监督数据微调Base(SFT)+RL(对齐),先提升推理能力,搞出数据,再提升LLM整体能力。
-
蒸馏=R1数据+学生模型SFT。蒸馏>RL,R1数据SFT的小模型能力得到提升,且优于强化学习+小模型。
真是再次证明了”数据决定上限,算法逼近上限“,也重新定义了什么叫”高质量数据“。
R1-Zero:RL的潜力
纯RL,基于规则,没有监督数据。
GRPO
放弃了通常与policy模型大小相同的critic模型,从群体分数来估计基线。具体来说,对每个q,GRPO从旧的policy采样一组输出,然后通过下面的目标函数优化policy。
其中,𝜀 和 𝛽 是超参,Ai是advantage,如下。
GRPO相比PPO要简单,但更重要的是它有效。
RM
基于规则,没有ORM或PRM!包括精度奖励和格式奖励(把思考过程放在<think>和</think>之间)两种规则。
这真是振奋人心的发现!我个人对强化学习(以及基于规则)的执念已经很久了(可以追溯到2018年),之前很多次提到过(见后面附录1相关文章),也做过一些尝试,但一直没有取得很好的成果。看到R1论文的第一反应是不可能吧?自己跟着复现后真的是震惊到了,太漂亮了。
数据构造
训练数据基于如下模板构造:
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: prompt. Assistant:
其中的prompt就是相应的问题。这里有意将约束限制在这种结构格式上是为了避免任何特定于内容的偏差,如强制反射性推理或促进特定的问题解决策略,确保能够准确观察到模型在强化学习过程中的自然进展。
上面的模板是Base模型,Instruct模型也是类似的。
结果
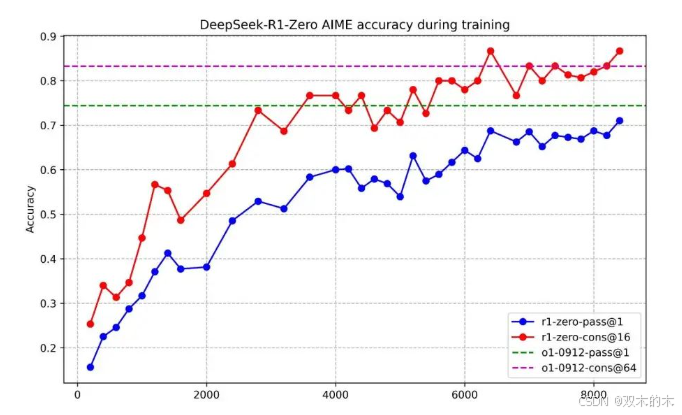
非常漂亮的曲线,非常Nice的表现!而且,实际中还可以通过多数投票进一步提升性能,如红色曲线所示。
Self-evolution
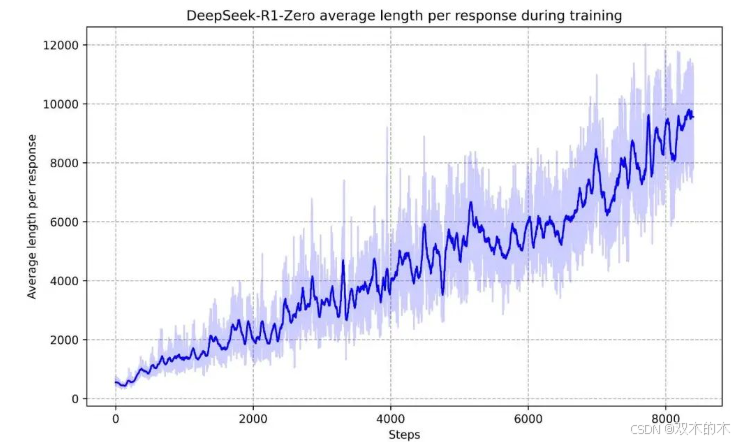
然后是过程中表现出来的自我进化,它最引人注目的方面之一是随着推理时计算的增加,出现了复杂的行为。诸如反思(重新审视和重新评估先前的步骤)和探索解决问题的替代方法等行为。这些行为是自发产生的,是模型与强化学习环境交互的结果,而不是明确编程的、外部调整的结果。
Aha Moment

接下来是很多人津津乐道的Aha Moment,其实就是模型自动学习重新评估、检查或验证,即自我反思和错误修正,有点类似”恍然大悟“。它显示出强化学习的神奇之处:我们并没有明确告诉模型如何解决问题,而是通过提供适当的激励,让它自主发展出高级的解决问题策略。
Aha Moment可以看作是模型在”推理时思考“的表现,其外在表现就是出现类似确认、重新检查、评估、验证等词,并且回复长度增加。如下图所示。
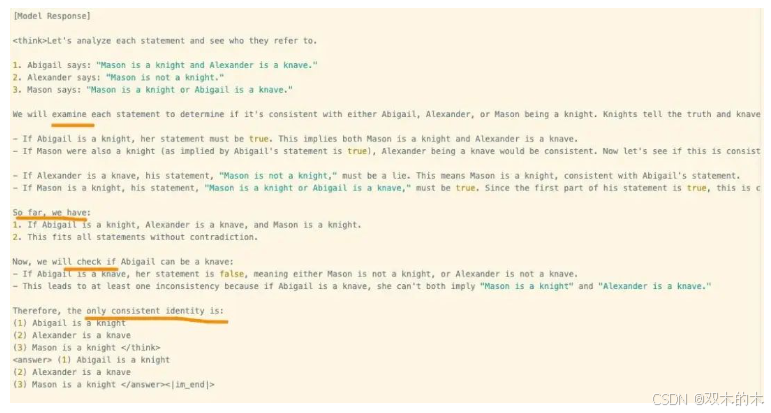
但值得注意的是:
-
Aha Moment并不是只有这种情况才会有。
-
长度增加并不一定意味着结果变好,或模型在思考。
关于这点我们后面会专门介绍另一篇研究的结论,这里不再赘述。
至于为什么R1-Zero可以有这样的效果,我觉得还是因为模型本身就有这样的能力,RL做的只是释放或引导出这种能力。后面我们会介绍通过少量SFT数据也可以做到。
R1-Zero表现出来的问题主要是两个:可读性差和语言混合现象。但我在复现时感觉第一个问题还好,第二个问题确实存在,也比较明显。不过话说回来,只要结果正确,过程人类可不可读,好像问题也不太大吧(doge)。
最后再补充一句,R1-Zero用纯规则强化学习能做出这样的效果,真的很厉害!
R1:LLM再次进化
接下来是R1,它是想改进R1-Zero自然延伸而来。R1-Zero后马上紧跟两个问题:
-
通过加入少量高质量数据作为冷启动,是否可以进一步提高推理性能或加速收敛?
-
如何训练一个用户友好的模型,该模型不仅产生清晰连贯的思维链 (CoT),而且还表现出强大的通用能力?
冷启动
R1第一步,冷启动。收集少量(Thousands)高质量CoT数据微调模型作为RL的起点(初始Actor)。
-
以长链推理(CoT)作为示例进行少量提示,直接提示模型生成带有反思和验证的详细答案。
-
以可读格式收集 R1-Zero 输出,并通过人工后处理来提炼结果。
冷启动数据相比R1-Zero的优势:
-
可读性:R1-Zero的内容经常不可读,冷启动的数据都是可读格式。
-
潜力:比R1-Zero表现更好。
推理导向的RL
接下来和R1-Zero一样(大规模RL),目的是提升模型推理能力,尤其是推理密集的任务。
-
训练过程中,依然观察到语言混合现象,尤其是Prompt包含多语种时。
-
为了减轻这个问题,引入「语言一致性」奖励,计算方式为推理链中目标语言词的比例。虽然导致性能略微下降,但结果可读。
-
最终奖励为:推理任务的准确性+语言一致性的奖励。
拒绝采样和SFT
上一步收敛后,主要用来收集SFT数据。就是说,前面做的工作都是为了搞数据。与主要关注推理的初始冷启动数据不同,此阶段整合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务方面的能力。
即用生成数据在DeepSeek-V3-Base上进行SFT。这个做法就是一般意义上的SFT,只是这里数据不一样。
-
推理数据:600k。用上一阶段的模型生成推理链数据(每个Prompt输出多个Response,选择正确的)。扩充了数据,过滤掉了结果中混合语言、长释义和代码块的推理链。
-
非推理数据:200k。复用了DeepSeek-V3的一部分SFT数据,对于某些非推理任务,调用DeepSeek-V3生成一个潜在的推理思维链,然后再通过提示来回答问题。对非常简单的query(比如“你好”之类),回复不用CoT。
所有场景RL
对齐阶段,提升有用性和无害性,同时保持推理能力在线。这里对齐时采用了混合方法。
-
推理数据(数学、代码和逻辑推理):遵循 DeepSeek-R1-Zero 中概述的方法(即规则)。
-
非推理数据:采用奖励模型来捕捉复杂和细微场景中的人类偏好。
对于有用性,专注最终总结,确保评估侧重于响应对用户的实用性和相关性,同时尽量减少对基础推理过程的干扰。
对于无害性,评估模型的整个响应,包括推理过程和总结。
经过以上4步,R1就出炉了。可以看到前两步主要是用来搞数据,具体来说就是带思考过程的数据。当然,后面两步也有改进,比如综合了两种数据训练和对齐。
这算不算是重新定义了“高质量数据”和“新的训练范式”呢?不管答案如何,我想,后面所有的LLM可能都会“R1”一下的。
蒸馏:小模型也有大能力
最后是蒸馏,也就是让小模型也拥有推理能力。具体做法是,直接用前面的800k数据微调Qwen和LLaMA,这种蒸馏方法叫黑盒蒸馏。
值得注意的是,这里没有继续RL(即使合并 RL 可以大大提高模型性能),他们将这个留给了社区。然后,就真的出现了(后面会介绍的DeepScaleR),算是补充了这里的后续。
R1相关研究探索
这一部分我们介绍与R1相关的一些比较有意思的研究。
oat-zero
首先来看oat-zero,相关内容如下。
-
There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study
-
sail-sg/oat-zero: A lightweight reproduction of DeepSeek-R1-Zero with indepth analysis of self-reflection behavior.
主要有下面几个结论。
-
在 R1-Zero 类训练中可能没有 Aha 时刻。相反,Aha 时刻(例如自我反思模式)出现在第 0 轮,即基础模型阶段。说明Aha不需要RL也可以有。
-
Base模型的回答中存在表面自我反思(SSR),在这种情况下,自我反思不一定导致正确的最终答案。比如四种行为中的后两种,如下所示。注意啊,这里并不是说Base模型不能自我反思,只是说存在表面自我反思。
-
行为1:自我反思重新检查并确认正确答案。
-
行为2:自我反思纠正最初的错误想法。
-
行为3:自我反思引入错误到原本正确的答案中。
-
行为4:重复的自我反思未能产生有效答案。
-
-
响应长度的增加现象并非自我反思的出现所导致,而是强化学习优化良好设计的基于规则的奖励函数的结果。
-
RL是将原本表面的自我反思转化为有效的自我反思,以最大化预期奖励,从而提高推理能力。
-
长度和自我反思可能不相关。
-
总的来说,可以概括成两句话:Base模型也可能Aha,但不否认RL不能Aha;RL能将Base的表面自我反思转化为有效自我反思,只是并不一定长度就一定增加。我觉得这个结论是Make sense的,Base模型只是具有能力但没有被激活,RL才激活了能力。
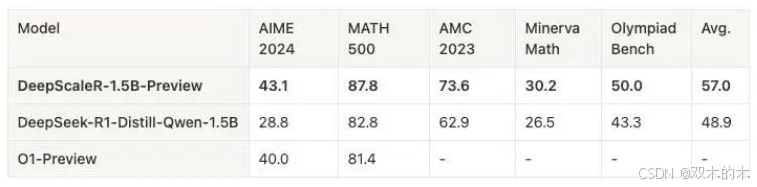
DeepScaleR
接下来是前面「蒸馏」部分提到的DeepScaleR,相关内容如下。
-
DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL
-
agentica-project/deepscaler: Democratizing Reinforcement Learning for LLMs
它的做法是直接从Deepseek-R1-Distilled-Qwen-1.5B强化微调(用高质量40K Math数据)。得到的模型在AIME2024和MATH500上超过了o1-preview。
这里的背景是:复现R1的计算量比较大,⩾32K context,~8000 steps,即使对1.5B模型也需要70,000小时A100。为了解决这个问题,本文使用一个蒸馏模型,并引入迭代式的长度增加方案。计算资源降到3800小时A100。
本文主要证明了通过 RL开发定制的推理模型既可扩展(Scaling)又具有成本效益。
它的数据处理流程如下:
-
使用
gemini-1.5-pro-002从官方Solution中抽取答案。 -
使用
sentence-transformers/all-MiniLM-L6-v2作为Embedding(使用语义相似度)移除重复/相似问题。 -
移除不能用
sympy评估的问题(这类问题需要使用LLM评估,这不但会影响训练速度,还可能引入噪声奖励信号)。
ORM设计:
-
1:如果答案通过基础的
LaTeX/Sympy检查。 -
0:答案或格式不对(比如没有
<think>, </think>)。
交互式的上下文长度增加方案:从短到长。
-
长上下文为模型提供更多思考空间,但会降低训练速度;但短上下文可能会限制模型解决需要较长上下文的更难问题的能力。
-
所以分两步走:8k→16k和24k。第一步在8k上实现更有效的推理和高效的训练;接下来扩展上下文长度,以便模型可以解决更复杂的问题。
为什么要分两步走?因为在训练前评估模型时,发现错误响应的长度是正确响应的3倍。这表明较长的响应通常会导致不正确的结果,直接用长上下文窗口进行训练可能效率低下,因为大多数Token实际上都被浪费了。
我们看看实际的效果,如下所示。
-
先在8k上下文训练,平均训练奖励从 46% 增加到 58%,而平均响应长度从 5,500 下降到 3,500,AIME2024 Pass@1 Acc 33.9%。1000步后,响应长度再次开始增加,响应裁剪率从 4.2% 上升到 6.5%,表明更多的响应在上下文限制处被截断。说明此时模型试图通过“思考更久”(即生成更多Token)来提高训练奖励。
-
在第 1040 步(响应长度开始呈上升趋势)处使用 16K 上下文窗口重新启动训练。额外 500 步后,平均响应长度从 3500 增加到 5500,平均训练奖励稳定到62.5%,Acc达到38%,响应裁剪率到2%。性能开始趋于稳定。
-
在480步重新启动具有 24K 上下文窗口的训练运行。200步后Acc达到43%。
| Step1 | Step2 | Step2-add | |
|---|---|---|---|
| ContextLength | 8k | 16k | 24k |
| ResponseLength | 5500→3500 | 3500→5500 | |
| ClipRatio | 4.2%→6.5% | 2% | |
| Reward | 46%→58% | 62.5% | |
| AIME Acc | 33.9% | 38% | 43.1% |
总的来说,结论就是:
-
RL 缩放也可以表现在小型模型中。单独的 SFT 和 RL 都不够;相反,通过将高质量的 SFT 蒸馏与RL缩放相结合,可以真正释放 LLM 的推理潜力。AIME 准确率从 28.9% 提高到 43.1%。
-
迭代扩展长度可实现更有效的长度缩放。简单来说,就是先训短的简单的,然后提升难度和长度限制,这样会比直接训练更加高效。
LIMO和s1
这两篇都是用少量高质量数据SFT激活模型推理能力的研究,相关内容如下。
-
LIMO: Less is More for Reasoning
-
GAIR-NLP/LIMO: LIMO: Less is More for Reasoning
-
s1: Simple test-time scaling
-
simplescaling/s1: s1: Simple test-time scaling
LIMO提出了如下假设:如果模型拥有丰富的推理知识并获得了足够的计算空间,那么激活推理能力可能只需要少量鼓励长时间思考的高质量训练样本。
然后它验证了假设,复杂的数学推理能力可以通过极少的高质量数据(817条,1/100的数据量)有效地引出(绝对性能提升40.5%)。而且普遍适用于分布外问题,表明模型获得了真正的推理能力,而不是简单的模式匹配。
这一发现不仅挑战了复杂推理任务需要海量数据要求的假设,还挑战了人们的普遍看法,即监督微调主要导致记忆而不是泛化。
s1类似,1000条高质量数据超过了59k的数据。
LIMO和s1的发现标志着知识基础的革命:从获取知识变为激活知识。
这两个研究都提到了高质量数据,对LIMO来说,数据质量有两个因素决定:
-
问题的质量。包括问题解决方法的多样性、挑战模型能力的适当难度级别以及所涵盖知识领域的广度等因素。
-
答案(推理链、Response)的质量。包括教学价值、逻辑一致性和方法论严谨性等方面。
s1相对粒度粗一些,主要整体考虑质量(无格式问题)、难度和多样性。
问题一般从已有数据集中筛选,答案可以使用官方解决方案,或用模型生成不同方案然后选择最好的。
在逻辑推理上的实验
这一轮的实验主要针对R1-Zero,除了验证上面的一些观点, 还有一些自己的想法。初步结论一并汇总在这里。
R1-Zero的起点不重要
有了前面的铺垫,相信这个结论是比较清晰的,就是说无论Base还是Instruct,无论是正常模型还是Math模型,理论上应该都能实现R1-Zero的效果。既有效果,又有类似的表现,姑且可以算复现了R1-Zero。
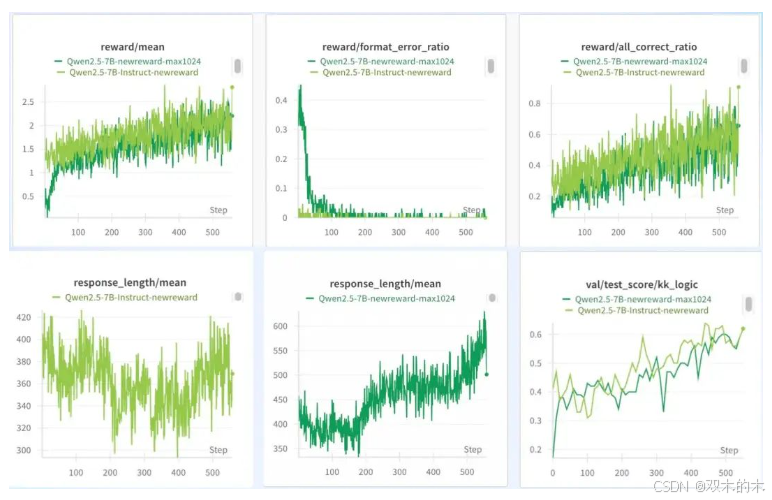
如图所示,绿色的是Qwen2.5-7B-Instruct,棕色的是Qwen2.5-7B,两者在奖励、格式错误率、整体正确率、测试集表现几乎呈现完全一致的走向。不过Instruct版本整体表现稍微好一些。在回复长度方面,二者整体趋势一致,都是先降低后增长,但Base模型长度增加更明显,而Instruct模型下降更久一些。猜测是Instruct模型因为经过了SFT,有了固有的指令跟随能力,因此需要比较久学习到新的要求;同时Instruct的能力又强于Base,因此回复长度也相对更短一些。
另外值得注意的是,Base模型的起点几乎为0,但Instruct模型不是,它一开始就有一定的准确率,如第二行最右边图所示。
模型越新效果越好
虽然用的是在Qwen2.5发布之后的数据集,尽量保证了OOD,但我们确实无法知晓模型是否在预训练时加入过类似数据。原计划选择Qwen1做试验,不过代码改动稍微有点复杂,因此选择Qwen-1.5-7B进行对比。
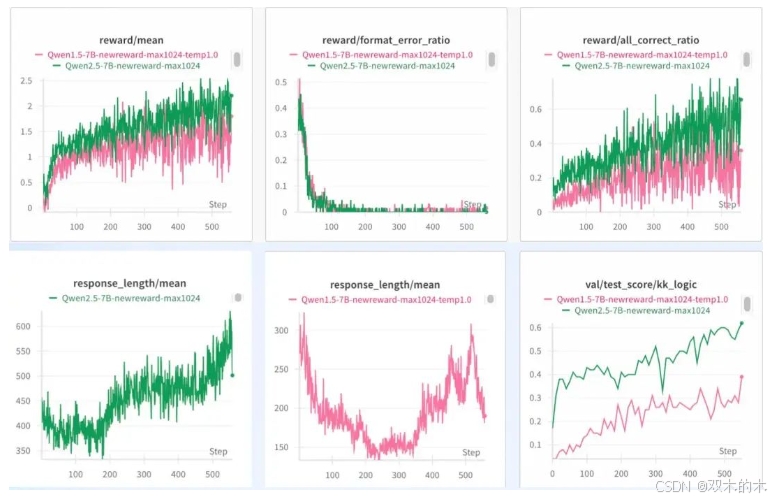
如图所示,Qwen1.5-7B整体要明显逊色于Qwen2.5-7B,虽然它们整体的趋势也是一致的。我们从Qwen2.5的官方介绍也可以看到,其中加了Code和数学数据。
模型越大效果越好
这可能是句废话,但我们还想知道好多少,以及具体表现到底差在哪里。很遗憾,1.5B的Base模型并没有复现出来,虽然奖励、格式错误、整体准确率、测试集准确率都和前面表现一致,但回复长度是一路下降,直到收敛,没有观察到上升的情况。不过过程中依然还是表现出了Aha现象。最终还是选择了Math版本的1.5B模型,即Qwen2.5-Math-1.5B成功完成验证。
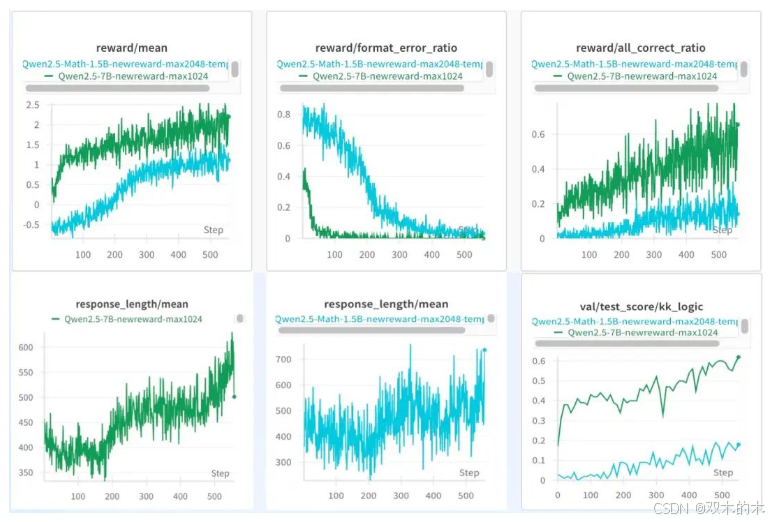
可以看到这个性能差别真是有点大,即便是Math模型,和7B之间的差距依然巨大。另外,尝试了3B模型,也能观察到效果,但回复长度上升幅度不大。
交互式长度增加有效
这里主要是验证多阶段(按难度等级)RL,类似DeepScaleR的做法。两步的趋势依然相近,但回复长度第二阶段明显更长,指标也有一定提升。
Reward非常关键
Reward是模型学习的方向,它的设计影响收敛速度和最终效果,应该针对不同任务进行相应设置。
以上结论更详细的说明之后将在技术报告中呈现。此外,由于我个人仅对强化这部分感兴趣,所以也就只做了这部分的一点验证,其他如LIMO、s1、R1、蒸馏等感兴趣的读者可以一试。
如果有读者和我一样,对强化学习、LLM和NLP结合感兴趣,可以关注我去年底创建的仓库:hscspring/rl-llm-nlp: Reinforcement Learning in LLM and NLP(https://github.com/hscspring/rl-llm-nlp),这里只收集强化学习和LLM、NLP相结合的内容。
R1:新范式、新纪元
如果你一路读到这里,相信对R1以及他所带来的影响有所感触。确实,创新比较多,几乎影响到LLM的每一个阶段。我们从预训练(Pretrain)、后训练(PostTrain)和推理(Inference)三个角度展开。
预训练
这块做的不多,只能简单聊聊自己的看法。DeepSeek-V3以相对比较低的成本震惊了一把业界,预训练看起来好像也并没有那么“高不可攀”。这当然和他们的技术创新有关,但还不可忽视的是行业整体的发展,尤其是高质量数据集的不断发布。后来者都是站在前人肩膀上的,从这个角度看,成本下降几乎是一件必然的事。成本下降是不是意味着会有更多的预训练模型呢?答案是一定的,但不一定是更多的LLM,而更可能是各类专用M,可以简称为LSM。直观上看就是Token不一样,比如AlphaFold。而且这一类的预训练模型可能并不用那么大。
R1的核心其实是“搞数据”,重新定义了“高质量数据”,这些数据是否可以用在预训练上?答案不言而喻。数据质量提高了,预训练上限能提升吗?可能需要实验验证一下。
那训练流程呢?原来是收集已有数据为主,之后是不是得考虑如何生成更好或者更合适的数据?这是不是会变成一个动态迭代过程?我觉得这可能成为一种新的训练范式,姑且把它放在预训练这里。
后训练
至于后训练显然内容更多。首先就是R1在Base基础上做的冷启动和RL,通过前面介绍,我们知道这两步的主要目的是激发出模型的推理能力,用来生成后面的SFT数据。冷启动其实就是用少量高质量数据SFT,它和基于规则的Pure RL结合,可以达到更好的效果。
类似的,用这些生成的数据重新SFT小模型(即论文中提到的蒸馏),其后也可以接RL(即R1-Zero),而且RL还可以分阶段来逐步进化到更大难度和更长回复(思考)。
除此之外,后面两步的SFT和对齐,虽然步骤和已有的后训练一样,但过程也大不一样。最大的区别是,R1在每个阶段都需同时考虑推理类数据和通用数据,这里有几个方面是比较值得进一步探索的。第一,推理数据和通用数据的比例是3:1,如果这个比例发生变化会怎么样?第二,对一些简单问题(比如打招呼),R1没有使用CoT(长链推理)回复,如何鉴定这里的“简单”?能否针对不同的上下文(用于区分用户的背景知识)给出不同的回复?第三,在对齐阶段R1同时使用了针对推理问题的纯规则Reward和针对人类偏好的RM,这是比较直观的方法。能否找到更好的RM?能否将其他一些规则也一并融入,然后训练出各种风格的LLM,就像人一样,成为他们天生的“性格”?我觉得这几个点都蛮有意思的。
上面提到这三点,算不算是新的训练范式?答案可能见仁见智,但我想R1的创新和贡献应该毋庸置疑吧,说他不亚于ChatGPT的发布也不算过分吧。
推理
R1的主要创新点其实体现在刚刚说的后训练阶段,推理中的某些特点是R1或o1这类模型的自然表现。关于o1,我在《关于AI前沿的思考》这篇文章中有提到:
我一直认为o1仅适用于有限的场景,因为它的目标是解决复杂的问题。事实上,Bob(OpenAI前首席研究官)也是这样认为的,他说除了程序员,大多数人日常工作中并不会遇到需要o1的需求。
但我没有想到推理方向(可能也和自己没有真正用过o1有关)。Bob提到GPT-4o有几秒钟的思考时间,o1是30秒到几分钟,甚至延伸到几小时或几天。这种被他称作“扩展”的变化,其实是把“学习”后置,我们可以把这个过程看成是模型自己补充上下文的过程。这又和奥特曼在此前一次访谈(诞生于HuggingLLM的蝴蝶书《ChatGPT原理与应用开发》第一章最后也提到了这次访谈)中说提示词会消亡的看法一致。o1的价值就在其扩展性,它开始会更多地“思考”,而不是“记忆”。它和强化学习的结合应该会是一个不被很多人重视(或看到),但很有可能带来下一次革命的组合。
这篇文章是我在24年12月发布的,结果最后一句话的“预测”在当时其实已经被实现了(只是R1还没有发布)……不得不感慨,世间真奇妙。上面的引用里也提到了“扩展”,其实这就是所谓的推理时Scaling,即把更多的计算放在推理阶段。不熟悉的读者需要注意,这里说的推理(Inference)是模型训练完后“使用”它,而前面提到的推理(Reasoning)数据是类似数学、代码、逻辑这一类的推理数据。
关于推理时Scaling(ITS),比较早(不确认是不是最早)的典型代表研究应该是DeepMind的 Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters,它主要回答这么一个问题:如果允许 LLM 使用固定但并非微不足道的推理时间计算量,那么它在具有挑战性的提示下性能可以提高多少?这里有两个关键前提:比较大的推理时计算量和有挑战性的问题。文章主要探讨了一些当时的Scaling方法的效果,比如Best-of-N(就是字面意思,Batch采样N个输出,然后根据一个验证者或奖励模型(RM)选择得分最高的)、TTS(Test Time Search)方法Random Sampling、Tree Search(比如MCTS)。主要结论(蛮有意思)是:推理时计算和预训练计算并非可以一对一“互换”。
-
对于简单和中等难度的问题(在模型能力范围内),或在推理需求较小的情况下,测试时计算可以轻松弥补预训练的不足。
-
然而,对于具有挑战性的问题(超出模型能力范围),或在推理需求较高的情况下,预训练可能在提升性能方面更加有效。
这个结论说明:模型本身的能力至关重要。推理时只能弥补不足,但不能消除不足。此时的奖励模型(RM)还是模型而不是规则,主要包括目标奖励模型(ORM,针对结果进行奖励)和过程奖励模型为主(PRM,针对过程进行奖励)。关于PRM的应用,R1发布前不久有两篇不错的研究值得一读:即微软发布的rStar-Math和PRIME-RL发布的Prime。
ITS应用的典型成功代表是OpenAI的o1: Learning to reason with LLMs | OpenAI,如其所述:
类似于人类在回答困难问题之前可能会思考很长时间,o1 在尝试解决问题时使用思维链。通过强化学习,o1 学会磨练其思维链并改进它使用的策略。它学会识别和纠正错误。它学会了将棘手的步骤分解为更简单的步骤。它学会了在当前方法不起作用时尝试不同的方法。此过程显著提高了模型的推理能力。
我们现在看到的R1就和这个描述非常相似,很多开源复现(包括我自己的实验)也确实观察到了这种现象。o1的重要表现是“思考很长时间”,即生成的长度比较长。根据实际使用情况,它的“很长时间”有时候是真的“很长”,这也算一种Scaling方法,前面提到的s1论文中的Budget Forcing算是一类Scaling,即Sequential Scaling。和前面提到的Best-of-N、树搜索等Parallel Scaling对应。
我们不知道o1是怎么做的,社区都猜测是MCTS,至少用了MCTS,但具体不得而知。但是R1我们是知道的,也是第一个将纯规则的RL成功应用于LLM。更为重要的是,他思考的还很快(相较o1)。更更为重要的是,他还将任务从复杂任务延展到所有任务。这一点是最牛逼的地方。o1针对复杂任务,很慢,所以看起来使用场景比较狭窄;R1针对所有任务,很快,直接将LLM提升到了另一个维度。而且,R1开源了。
总的来说,R1给LLM在推理方面带来了极大的变革,这是他在后训练上创新体现出来的结果,这种边推理边思考边优化的方式使得LLM离“人”更近了一步。R1之前,LLM有人的能力,但用的时候还是个模型;R1之后,LLM不但有人的能力,用起来也更像人。
其他影响
最后简单谈谈对从业者和行业的影响。我在《ChatGPT原理与应用开发》、《ChatGPT 开发指南:Hugging LLM Hugging Future | Yam》、《ChatGPT 影响冲击:职业、行业与产业 | Yam》等等文章以及很多分享中多次提到过相关内容。对于整个开发范式,确实影响不大,甚至会进一步深化,毕竟LLM能力进一步得到了提升。对于NLP算法这个职位也依然是类似观点,但稍微有点不一样了,主要是R1这波给的太多了,给算法指明了新的路径。其实现在的所谓LLM工程师基本来自两波:一大波之前的NLP算法工程师,LLM新技术出现后跟进的;一大波转行或新加入的。不过真正搞算法底层研发的职位注定会越来越少,大部分人还是得老老实实搞应用,包括我本人。但是搞应用的门槛慢慢降下来了,没办法,太火了,人太多了,相关的研究、工具如雨后春笋,虽然质量参差不齐,但行业整体确实欣欣向荣,大浪淘沙,自然而然会有优质内容慢慢浮现。对算法工程师,尤其是LLM相关的算法工程师来说,只懂算法怕是难以应付以后得局面;退一步说,算法工程师你不也得先是个工程师么。LLM以前,只懂一点算法,能跑个模型还可以吃到红利,LLM之后这样的红利怕是会逐步消失殆尽。既是坏事,也是好事,看你怎么理解了。
总结
本文比较详细地介绍了DeepSeek R1及其相关的技术,我们深刻感受到了RL的力量和魅力,更深刻感受到了R1的创新和强大。也难怪ai.com会把链接指向DeepSeek,人家不光有详细的技术报告,还把模型都开源出去了。真的很了不起。
说起来,本文还有个背景,最近偶尔在网上看到有一些行外人士说R1是蒸馏的ChatGPT,还煞有介事的做了LLM的科普视频。看完之后发现视频做的不错,但其中很多观点其实是错误的。令人意外的是,评论区大部分人都是无脑追捧,居然说是全网最好的科普。当然也不乏部分行业人士评论作者的偏颇之处,不过压根没人理会。无论是尬吹还是尬黑,我个人都比较反感。所以本文既是一篇R1相关的技术总结文章,也姑且可以算是一篇(稍有难度的)科普文章。我相信即便有读者无法读懂全部内容,但至少一部分内容还是可以看明白的,我想这就够了。当然,个人能力所限,文章也可能有不准确、不完善的地方,也欢迎读者指正。
最后,我写的很爽,希望你也能读的爽。我们就用分享时最后的个人观点来结束本文:R1发迹于OpenAI-o1,但超越了o1。他提升了LLM的整体能力,让模型真正在推理时进行自我反思和验证,这当然适用于复杂问题,但很多日常普通场景也能受益,AI更加像人。这是R1对整个行业的贡献,其作用不亚于ChatGPT的发布。
附录
附录1
笔者曾提到强化学习的相关文章,有些内容可能很幼稚甚至不对,还望读者海涵。
-
2024关于AI前沿的思考 | Yam -
2024LLM Tiny Pretrain:H2O-Danube and Stable LM | Yam -
2023关于大语言模型的思考 | Yam -
2023ChatGPT 基础科普:知其一点所以然 | Yam 或《ChatGPT原理与应用开发》第一章 -
2020NLP 表征的历史与未来 | Yam -
2020RoBERTa 论文+代码笔记 | Yam -
2020Bart 论文+代码笔记 | Yam -
2018西蒙《人工科学》读书笔记 | Yam -
2018NLP 与 AI | Yam
博客仓库:https://yam.gift/,以上文章均可在里面找到。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









