







本文来源公众号“kaggle竞赛宝典”,仅用于学术分享,侵权删,干货满满。
前言
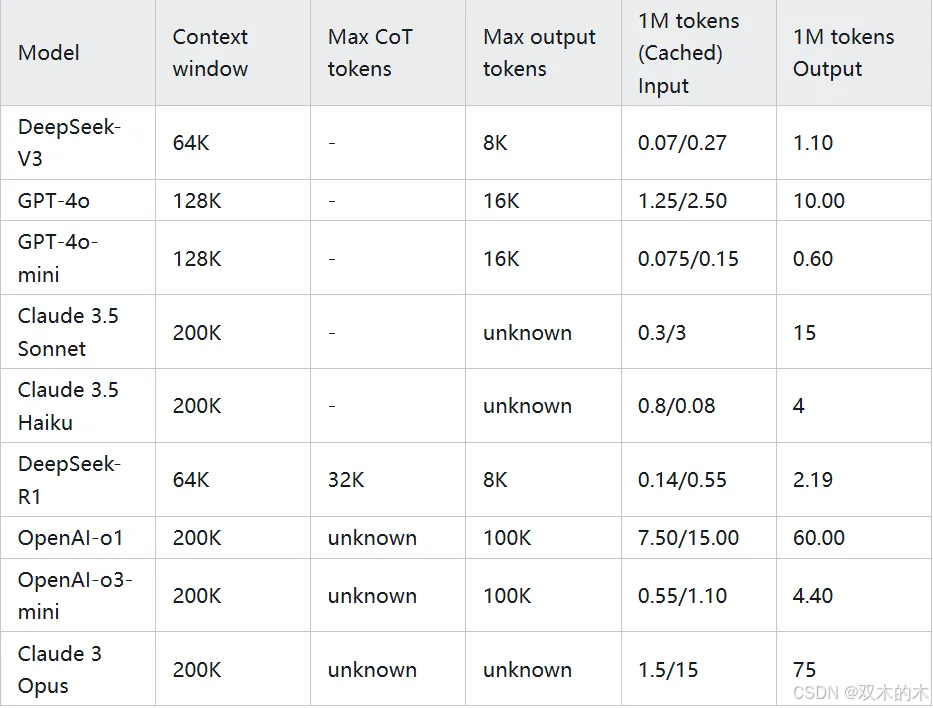
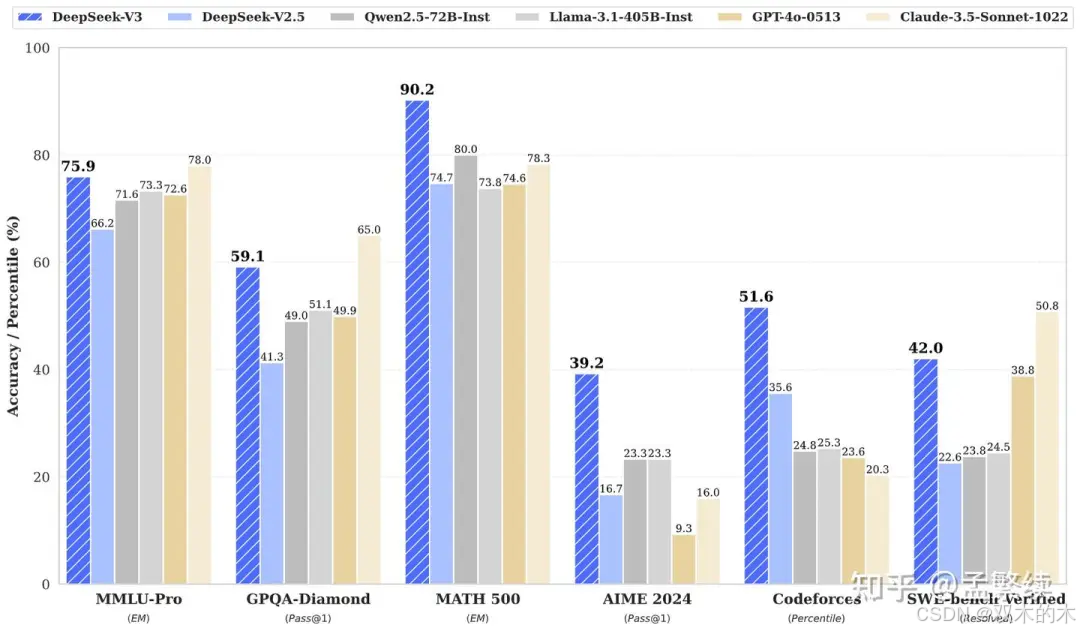
Deepseek使用更低的成本追赶OpenAI的效果
关注Deepseek也有一年多了,当时Mixtral-8x7B模型刚出来,我写了一篇分析其MoE架构的文章。Deepseek不久后推出了他们第一版Deepseek MoE模型,他们的工作人员看到文章加了我的微信;
在做PiSSA[1]的时候,我就将Deepseek MoE视为主流模型进行了实验对比;
在Deepseek V2出来后,MLA架构巧妙地设计吸引了我。启发我做出CLOVER[2]这篇文章。MLA中存在一个absorb操作,能将Key Weight吸收到Query Weight中,Value Weight吸收到Output Weight中,缺点是合并后参数量会变大。CLOVER先合并再分解,不改变模型结构就能得到正交的注意力头,对剪枝和微调都有很大的好处;
随着Deepseek V3/R1彻底爆火,我也来添一把火:
https://huggingface.co/papers/2502.07864
https://github.com/fxmeng/TransMLA-
• 本文理论证明了,在同等KV Cache开销下,MLA的表达能力始终大于GQA的能力,并通过实验验证这一优势。
-
• 本文提出一种TransMLA的方法,能将目前主流模型如LLaMA-3,Qwen-2.5等模型中的GQA统统等价变换为能力更强的MLA。
-
• 本文将会使用改造后的模型复现R1的能力。此外还会探索MoE,MTP结构,混合精度量化训练,训练推理加速等技术,希望能推动基于GQA模型向MLA模型的过渡,帮助初学者了解Deepseek使用的技术,以及给大模型厂商提供一个低成本迁移模型架构的方案。
TransMLA方法
本节首先提出以下定理:
定理1:当KV Cache大小相同时,MLA的表达能力大于GQA。
证明:通过接下来的1)2)3)节,我们论证了任何GQA都可以等价转换为具有相同KV Cache大小的MLA形式。在第4)节中,存在MLA无法通过GQA表示的情况。从而完成定理1的证明。
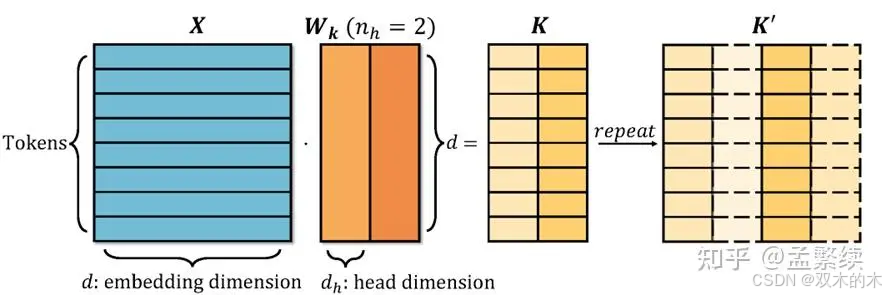
Group Query Attention (GQA)
1)GQA形式,复制Key-Value
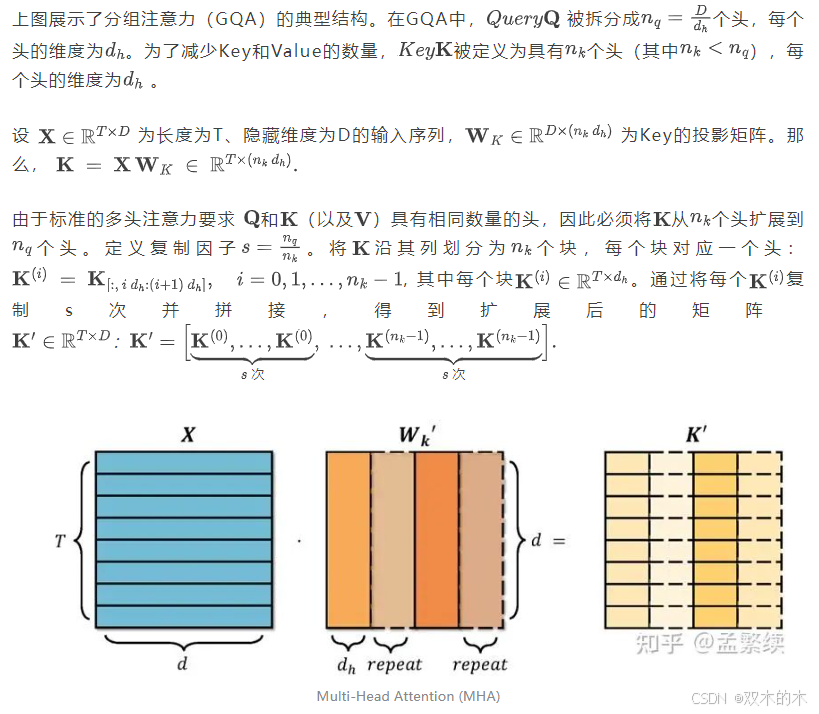
2)MHA形式,将复制操作移到参数侧

3)MLA形式,低秩分解参数矩阵

4)存在MLA无法被GQA表示的情况

基于上述分析,我们证明了定理1。通过将GQA转化为等效的MLA表示,我们可以增强模型的表达能力。接下来的章节将展示实验结果,以验证这一结论。
实验效果
我们以Qwen2.5为例,展示如何将一个基于GQA的模型转换为MLA模型,并对比转换前后的模型在下游任务中的训练效果。

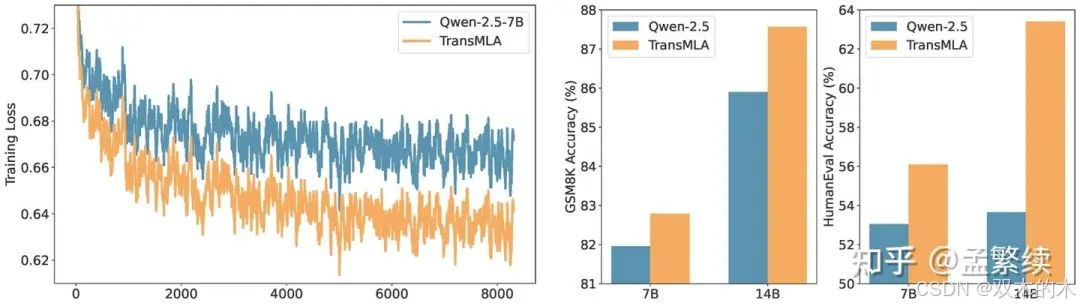
训练loss以及在测试集上的准确率
从图中可以看出,经过转换的MLA模型在训练过程中表现出更低的Loss值,表明其对训练数据的拟合能力更强。在7B和14B模型的设置下,TransMLA模型在数学和代码任务上的准确率显著高于原始的基于GQA的模型。这表明,TransMLA不仅提升了模型的表达能力,还在特定任务上带来了显著的性能改进。
这种性能提升不仅仅归功于增大了Key-Value中的可训练参数,正交化分解方式的使用也在其中发挥了至关重要的作用。为了进一步验证这一点,我们进行了对比实验。在这个实验中,我们没有采用正交化分解方式,而是通过Identity Map初始化升维模块来实现TransMLA。
训练后得到的模型在GSM8K数据集上的准确率为82.11%,比基于GQA的模型(81.96%)高出仅0.15%。这一结果表明,仅仅增加可训练的参数并不能解释TransMLA性能的显著提升,正交化分解方式在提升模型效果方面发挥了关键作用。目前,更多的实验正在进行中,希望深入探究这一现象背后的原因,进一步验证正交化分解对模型性能的贡献。
后记
本文证明了GQA模型都能转化为MLA形式,给了大模型厂商一个放弃GQA,拥抱MLA的理由,以及快速过渡的方法。
然而收到原始模型结构的限制,TransMLA的结构并不是最优的,如没有对Query进行压缩,没有使用Decoupled RoPE,以及Key和Value使用了独立的latent Vectors。
若要从头训练模型,仍然建议在Deepseek V3的结构上进行创新。TransMLA能够提升目前R1蒸馏Qwen,蒸馏LLaMA项目的效果。
未来我们将会进行这一工作,并开源训练代码和模型。
引用链接
[1] PiSSA: https://arxiv.org/abs/2404.02948
[2] CLOVER: https://arxiv.org/abs/2411.17426
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









