






本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:初学者指南 -- 什么是迁移学习?
假设您有一个想要用计算机视觉解决的问题,但可用于建立新模型的图像却很少。您该怎么办?您可以等待收集更多数据,但如果您想捕捉的特征很难找到(例如,野生珍稀动物、产品缺陷),这可能是站不住脚的。
这就是迁移学习的用武之地。在本文中,我们将讨论:
- 什么是迁移学习?
- 迁移学习如何起作用?
- 何时应使用迁移学习
什么是迁移学习?
迁移学习是一种计算机视觉技术,在现有模型的基础上构建新模型。这样做的目的是鼓励新模型从旧模型中学习特征,以便新模型能够更快地以更少的数据进行训练以实现其目的。
“迁移学习”这个名称说明了这项技术的含义:将一个模型获得的知识迁移到可以从该知识中受益的新模型。这类似于你将绘画知识迁移到素描中(色彩理论、审美观),尽管这两项任务不同。
探索迁移学习示例
想象一下在非洲的一次狩猎旅行中收集到的动物图像。数据集由长颈鹿和大象的图像组成。现在假设您想要建立一个模型,该模型可以区分长颈鹿和大象,并将这些图像作为计算特定区域内野生动物数量的模型的一部分的输入。
您可能首先想到的是从头开始构建一个图像识别模型来实现这一点。不幸的是,您只拍了几张照片,因此不太可能达到较高的准确率。
因此,您决定寻找新图像来扩大数据集并标记新图像,然后从头开始训练模型。这是可行的。但是,假设您找到适合您领域的新图像,这将非常耗时。
但是假设你有一个经过训练的模型,例如,数百万张可以区分狗和猫的图像。
我们可以做的是采用这个已经训练过的模型,并利用模型已经学到的知识来教它区分其他种类的动物(在我们的例子中是长颈鹿和大象),而不必从头开始训练模型,这可能不仅需要大量的数据(在这种情况下,我们没有),而且还需要大量的计算复杂性。
利用已经训练过的模型的知识来创建专门用于另一项任务的新模型就是迁移学习。
迁移学习的工作原理
一个可以识别猫和狗的模型怎么可能用来识别长颈鹿和大象呢?好问题。
卷积网络从高级图像中提取特征。CNN 的前几层学习识别一般特征,例如垂直边缘,后续层学习识别水平边缘,然后可能将这些特征组合起来识别角、圆圈等。
这些高级特征与我们需要识别的实体类型无关。计算机视觉模型不只是“学习”猫的确切样子。相反,模型将图像分解成小部分,并学习这些小部分如何组合成与特定概念相关的特征。
实体(在本例中为动物)的识别发生在线性层,该线性层将从卷积层提取的特征作为输入,并学习在最终的类别(长颈鹿或大象)中进行分类。
为了应用迁移学习,我们删除已训练模型的线性层(因为它们是经过训练以识别其他类别的层)并添加新层。我们重新训练新层,使它们专注于识别我们感兴趣的类别。
如何使用迁移学习
要应用迁移学习,首先要选择一个在大型数据集上训练过的模型来解决类似的问题。一种常见的做法是从计算机视觉文献中获取模型,例如 VGG、ResNet 和 MobileNet。
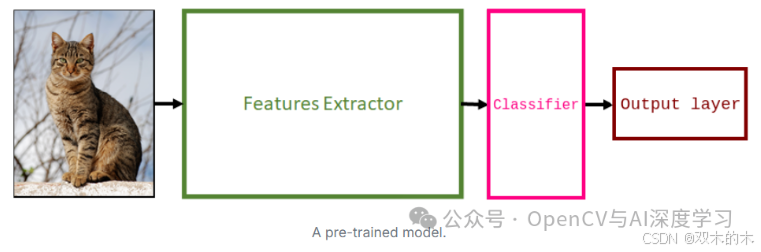
接下来,删除旧的分类器和输出层。
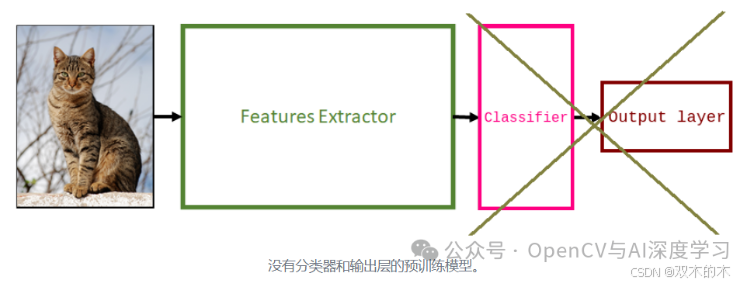
接下来,添加一个新的分类器。这涉及调整架构以解决新任务。通常,此阶段意味着添加一个新的随机初始化线性层(由下面的蓝色块表示)和另一个具有多个单元的线性层,该单元的数量等于数据集中的类数(由粉色块表示)。

接下来,我们需要冻结预训练模型中的特征提取器层。这是一个重要的步骤。如果您不冻结特征提取器层,您的模型将重新初始化它们。如果发生这种情况,您将失去已经进行的所有学习。这与从头开始训练模型没有什么不同。
最后一步是训练新的层。您只需要在新数据集上训练新的分类器即可。
完成上一步后,您将拥有一个可以对数据集进行预测的模型。您也可以选择通过微调来提高其性能。微调包括解冻预训练模型的部分内容,并继续在新数据集上进行训练,以使预训练特征适应新数据。为避免过度拟合,请仅在新数据集较大且学习率较低时运行此步骤。
何时使用迁移学习及其好处
我们来讨论一下在哪些场景下使用迁移学习比较方便,在哪些场景下不方便使用迁移学习 。
当你具有以下情况时,值得使用迁移学习:
-
-
数据量少:数据量太少会导致模型性能不佳。使用预训练模型有助于创建更准确的模型。启动和运行模型所需的时间更少,因为您不需要花时间收集更多数据。
-
时间有限:训练机器学习模型可能需要很长时间。当你没有太多时间时(例如,创建原型来验证某个想法),值得考虑迁移学习是否合适。
-
计算能力有限:训练包含数百万张图像的机器学习模型需要大量计算。有人已经为您完成了这项艰苦的工作,为您提供了一套可用于任务的良好权重。这减少了训练模型所需的计算量(因此也减少了设备量)。
-
而在以下情况下迁移学习并不适用:
-
-
领域不匹配:大多数情况下,如果预训练模型所用的数据与我们用于迁移学习的数据有很大不同,迁移学习就无法发挥作用。两个数据集在预测上必须相似(即基于具有类似产品的数据集训练缺陷分类器,这些产品显示带注释的划痕和凹痕)。
-
您需要使用大型数据集:迁移学习可能不会对需要更大数据集的任务产生预期的效果。随着我们添加更多数据,预训练模型的性能会变差。原因是,随着我们增加微调数据集的大小,我们会向模型添加更多噪音。由于预训练模型在预训练数据集上表现良好,它可能会卡在局部最小点,根本无法适应新的噪音。如果我们有一个大型数据集,我们应该考虑从头开始训练模型,这样我们的模型就可以从数据集中学习关键特征。
-
关于迁移学习的关键要点
迁移学习模型专注于存储解决一个问题时获得的知识,并将其应用于不同但相关的问题。许多预训练模型可以作为训练的起点,而不是从头开始训练神经网络。这些预训练模型提供了更可靠的架构,并节省了时间和资源。
当您的数据量有限、时间不足或计算能力有限时,您可能需要考虑使用迁移学习。
如果您拥有的数据与预训练模型所用的数据不同,或者您拥有的数据集很大,则不应使用迁移学习。在这两种情况下,最好从头开始训练模型。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 2232
2232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









