






本文来源公众号“戎易大数据”,仅用于学术分享,侵权删,干货满满。
原文链接:数据分析实操篇:电商618销售目标未达成的原因分析
背景
公司目标:公司希望在618期间将产品线销售额同比提升15%。
结果:618活动结束后,未达成该销售目标。
任务:分析未达成销售目标的原因,并提出可执行的改进建议。
数据概览
数据来源:2017-2021年某品牌的618期间订单数据,包括订单日期、商品类别、订单金额等。
数据结构:
BILLDATE: 订单日期
QTY: 商品数量
AMOUNTRETAIL: 零售金额
会员号: 用户标识
ClassI: 一级类别
ClassII: 二级类别
ProductName: 商品名称
订单金额: 实际订单金额
数据预处理
import pandas as pdimport numpy as npfrom datetime import datetimeimport warningsimport matplotlib.pyplot as plt# 去除科学计数法# pd.set_option("display.float_format", lambda x: '%.3f' % x)# 忽略警告warnings.filterwarnings('ignore')# 遇到数据中有中文时,设置中文字体plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 使用黑体plt.rcParams['axes.unicode_minus'] = False # 显示负号# 设置标题标注和字体大小plt.rcParams.update({"font.size": 20}) # 改变标题字体大小# 加载数据data_path = '/home/mw/input/6189643/箱包订单表.xlsx'df = pd.read_excel(data_path)# 查看数据结构print(df.head())print(df.info())
输出:
BILLDATE QTY AMOUNTRETAIL 会员号 订单号 ClassI \0 2019-06-27 14:50:54 1.0 1698.0 14577169286 127912128711475 手袋1 2019-06-27 14:50:54 1.0 1798.0 18670076440 120659496170284 手袋2 2019-06-27 14:50:54 1.0 1198.0 15138684493 129806316702237 手袋3 2019-06-27 14:50:29 1.0 1598.0 13529513483 123895732841134 手袋4 2019-06-27 14:50:54 1.0 1298.0 15256290464 126270762692469 手袋ClassII ProductName 产品号 订单金额0 单肩包 信封包 Rn9Zev5P4a 473.881 双肩包 背包 Z4bYH2456W 532.742 斜挎包 方形包 pLn7774I4L 234.353 斜挎包 方形包 1i1hvhwm9Z 1666.494 斜挎包 贝壳包 bfTj1RbD5L 466.85<class 'pandas.core.frame.DataFrame'>RangeIndex: 857135 entries, 0 to 857134Data columns (total 10 columns):BILLDATE 857135 non-null datetime64[ns]QTY 855399 non-null float64AMOUNTRETAIL 782040 non-null float64会员号 857135 non-null int64订单号 857135 non-null int64ClassI 730153 non-null objectClassII 730153 non-null objectProductName 730153 non-null object产品号 730153 non-null object订单金额 724895 non-null float64dtypes: datetime64[ns](1), float64(3), int64(2), object(4)memory usage: 65.4+ MBNone
df = df[df['ClassI']=='手袋']df = df[df['订单金额']>0] # 选取金额大于0的分析print(df.head())print(df.info())
输出:
BILLDATE QTY AMOUNTRETAIL 会员号 订单号 ClassI \0 2019-06-27 14:50:54 1.0 1698.0 14577169286 127912128711475 手袋1 2019-06-27 14:50:54 1.0 1798.0 18670076440 120659496170284 手袋2 2019-06-27 14:50:54 1.0 1198.0 15138684493 129806316702237 手袋3 2019-06-27 14:50:29 1.0 1598.0 13529513483 123895732841134 手袋4 2019-06-27 14:50:54 1.0 1298.0 15256290464 126270762692469 手袋ClassII ProductName 产品号 订单金额0 单肩包 信封包 Rn9Zev5P4a 473.881 双肩包 背包 Z4bYH2456W 532.742 斜挎包 方形包 pLn7774I4L 234.353 斜挎包 方形包 1i1hvhwm9Z 1666.494 斜挎包 贝壳包 bfTj1RbD5L 466.85<class 'pandas.core.frame.DataFrame'>Int64Index: 451134 entries, 0 to 857133Data columns (total 10 columns):BILLDATE 451134 non-null datetime64[ns]QTY 451100 non-null float64AMOUNTRETAIL 403529 non-null float64会员号 451134 non-null int64订单号 451134 non-null int64ClassI 451134 non-null objectClassII 451134 non-null objectProductName 451134 non-null object产品号 451134 non-null object订单金额 451134 non-null float64dtypes: datetime64[ns](1), float64(3), int64(2), object(4)memory usage: 37.9+ MBNone
每年618差距分析
# 确保 BILLDATE 为 datetime 格式df['BILLDATE'] = pd.to_datetime(df['BILLDATE'])# 过滤出 618 的订单(每年6月18日)df_618 = df[df['BILLDATE'].dt.month == 6] # 筛选6月份的数据df_618 = df_618[df_618['BILLDATE'].dt.day == 18] # 筛选6月18日的数据# 按年份统计每年618的销售额df_618['year'] = df_618['BILLDATE'].dt.yearsales_by_year = df_618.groupby('year')['订单金额'].sum().reset_index()sales_by_year.columns = ['Year', 'Sales']# 展示数据print(sales_by_year)
输出如下:
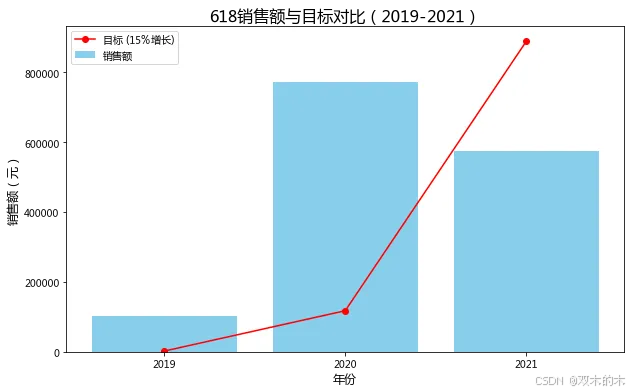
Year Sales0 2017 1222162.431 2018 1731.612 2019 102173.913 2020 772919.464 2021 575882.00
分析:2018年的有效数据似乎非常少,2017年的数据似乎过多,我们自从2019-2021年开始分析
import matplotlib.pyplot as plt# 只保留2019年到2021年的数据sales_by_year['Target'] = sales_by_year['Sales'].shift(1) * 1.15sales_by_year['Target'].fillna(0, inplace=True) # 填充第一个目标为空的值sales_by_year['Gap'] = sales_by_year['Sales'] - sales_by_year['Target']sales_by_year['Achieved'] = sales_by_year['Sales'] >= sales_by_year['Target']sales_by_year_filtered = sales_by_year[sales_by_year['Year'] >= 2019]# 绘制销售额和目标对比图plt.figure(figsize=(10, 6))plt.bar(sales_by_year_filtered['Year'], sales_by_year_filtered['Sales'], color='skyblue', label='销售额')plt.plot(sales_by_year_filtered['Year'], sales_by_year_filtered['Target'], color='red', marker='o', linestyle='-', label='目标 (15% 增长)')# 图表设置plt.title('618销售额与目标对比(2019-2021)', fontsize=16)plt.xlabel('年份', fontsize=12)plt.ylabel('销售额(元)', fontsize=12)plt.legend()plt.xticks(sales_by_year_filtered['Year'])plt.show()
# 将日期字段转化为年份df_618['Year'] = df_618['BILLDATE'].dt.year# 过滤需要的年份 2019-2021 年df_618 = df_618[df_618['Year'].isin([2019, 2020, 2021])]# 计算每年的关键指标annual_data = df_618.groupby('Year').agg({'订单金额': 'sum', # 总销售额'QTY': 'sum', # 总购买数量'会员号': pd.Series.nunique, # 每年唯一的消费人数'订单号': pd.Series.nunique # 每年唯一的订单数}).reset_index()# 重命名列annual_data.rename(columns={'订单金额': 'total_sales', 'QTY': 'total_qty', '会员号': 'consumer_count', '订单号': 'order_count'}, inplace=True)# 计算同比数据 (YoY)annual_data['sales_yoy'] = annual_data['total_sales'].pct_change() * 100 # 订单金额同比annual_data['qty_yoy'] = annual_data['total_qty'].pct_change() * 100 # 购买数量同比annual_data['consumer_yoy'] = annual_data['consumer_count'].pct_change() * 100 # 消费人数同比annual_data['order_yoy'] = annual_data['order_count'].pct_change() * 100 # 订单数同比print(annual_data.to_string(index=False))
输出如下:
Year total_sales total_qty consumer_count order_count sales_yoy qty_yoy consumer_yoy order_yoy2019 102173.91 187.0 134 142 NaN NaN NaN NaN2020 772919.46 1344.0 1246 1296 656.474388 618.716578 829.850746 812.6760562021 575882.00 1081.0 1016 1044 -25.492625 -19.568452 -18.459069 -19.444444
2020年的销售表现非常出色,超出了目标,但2021年则出现了下滑,未能达成目标。
为了了解618销售未达成的具体原因,公司需要进一步深入分析以下几个方面:
用户活跃度:2021年是否有较少的用户参与活动?购买行为是否减少?
促销力度:2021年的促销活动是否足够吸引力?
市场竞争:是否有更多竞争者加入,导致市场份额下降?
产品表现:2021年产品的销售是否集中于某些类别,哪些类别表现不佳?
人货场角度分析
人(用户分析)
要解决销售额未达成的问题,需要通过分析DAU(每天活跃用户数)、DPU(每天支付用户数)和Install(每个用户首次购买时间)的数据。这些数据将帮助了解销售额的构成,深入分析用户的行为特征。
# 计算每天活跃用户数(DAU)# DAU是每天至少来访1次的用户。通过订单数据的BILLDATE字段,可以统计每天有多少用户进行了购买。df_618['BILLDATE'] = pd.to_datetime(df_618['BILLDATE'])df_618['date'] = df_618['BILLDATE'].dt.date# 统计每一天有多少独立的用户dau = df_618.groupby('date')['会员号'].nunique().reset_index(name='DAU')print(dau)
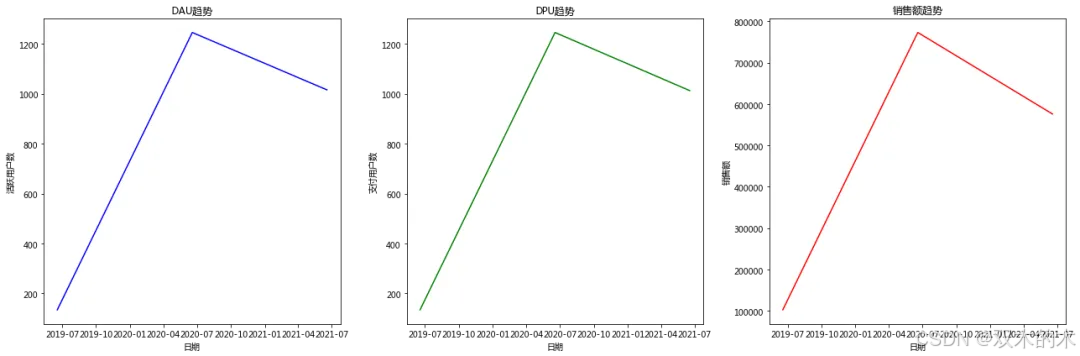
date DAU0 2019-06-18 1341 2020-06-18 12462 2021-06-18 1016
# DPU是指每天至少消费1元的用户数。可以通过过滤订单金额大于1元的记录来计算每天的DPU。# 计算每天支付用户数(DPU),即订单金额大于1的用户dpu = df_618[df_618['订单金额'] > 1].groupby('date')['会员号'].nunique().reset_index(name='DPU')print(dpu)
输出:
date DPU0 2019-06-18 1341 2020-06-18 12462 2021-06-18 1013
# 计算每个用户的首次购买时间install = df_618.groupby('会员号')['BILLDATE'].min().reset_index(name='首次购买时间')# print(install)
# 计算每天的销售额daily_sales = df_618.groupby('date')['订单金额'].sum().reset_index(name='销售额')# 将DAU、DPU、销售额等数据合并到一起summary = dau.merge(dpu, on='date').merge(daily_sales, on='date')print(summary.head())
输出如下:
date DAU DPU 销售额0 2019-06-18 134 134 102173.911 2020-06-18 1246 1246 772919.462 2021-06-18 1016 1013 575882.00
# 可视化DAU、DPU和销售额的趋势plt.figure(figsize=(18, 6)) # 宽18,高6# DAU趋势plt.subplot(1, 3, 1)plt.plot(summary['date'], summary['DAU'], label='DAU', color='blue')plt.title('DAU趋势')plt.xlabel('日期')plt.ylabel('活跃用户数')# DPU趋势plt.subplot(1, 3, 2)plt.plot(summary['date'], summary['DPU'], label='DPU', color='green')plt.title('DPU趋势')plt.xlabel('日期')plt.ylabel('支付用户数')# 销售额趋势plt.subplot(1, 3, 3)plt.plot(summary['date'], summary['销售额'], label='销售额', color='red')plt.title('销售额趋势')plt.xlabel('日期')plt.ylabel('销售额')plt.tight_layout()plt.show()
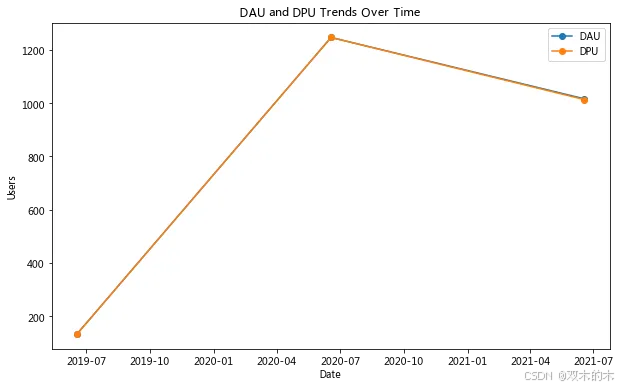
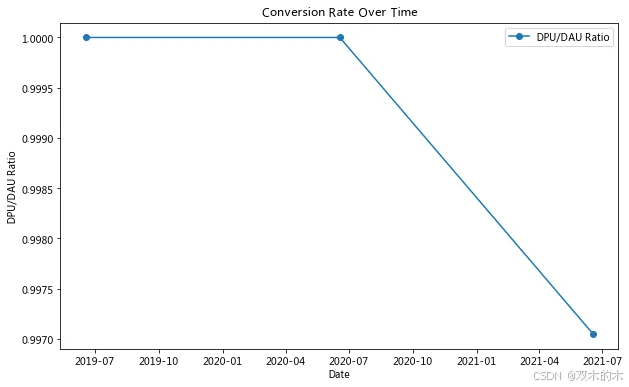
# 计算 DPU/DAU 比率summary['DPU_DAU_ratio'] = summary['DPU'] / summary['DAU']# 绘制 DAU 和 DPU 趋势图plt.figure(figsize=(10, 6))plt.plot(summary['date'], summary['DAU'], label='DAU', marker='o')plt.plot(summary['date'], summary['DPU'], label='DPU', marker='o')plt.xlabel('Date')plt.ylabel('Users')plt.title('DAU and DPU Trends Over Time')plt.legend()plt.show()# 绘制付费转化率趋势图plt.figure(figsize=(10, 6))plt.plot(summary['date'], summary['DPU_DAU_ratio'], label='DPU/DAU Ratio', marker='o')plt.xlabel('Date')plt.ylabel('DPU/DAU Ratio')plt.title('Conversion Rate Over Time')plt.legend()plt.show()
# 计算ARPUsummary['ARPU'] = summary['销售额'] / summary['DPU']# 绘制销售额和用户增长的关系plt.figure(figsize=(10, 6))plt.plot(summary['date'], summary['销售额'], label='Sales', marker='o', color='blue')plt.plot(summary['date'], summary['DPU'], label='DPU', marker='o', color='green')plt.xlabel('Date')plt.ylabel('Sales and DPU')plt.title('Sales and DPU Trends Over Time')plt.legend()plt.show()# 绘制ARPU 的变化趋势plt.figure(figsize=(10, 6))plt.plot(summary['date'], summary['ARPU'], label='ARPU', marker='o', color='orange')plt.xlabel('Date')plt.ylabel('ARPU')plt.title('ARPU (Average Revenue Per User) Over Time')plt.legend()plt.show()
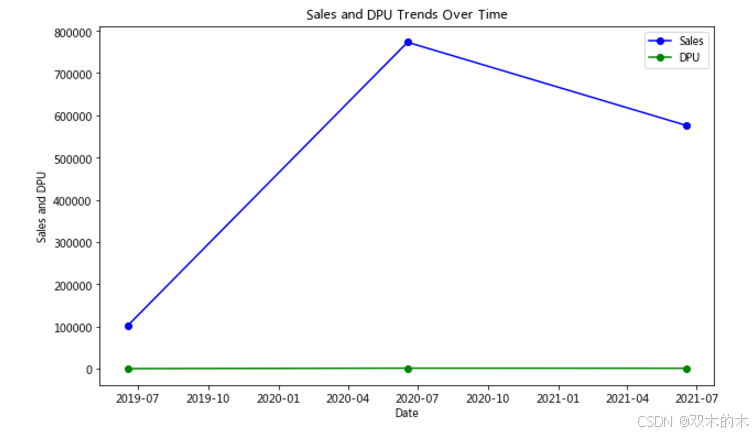
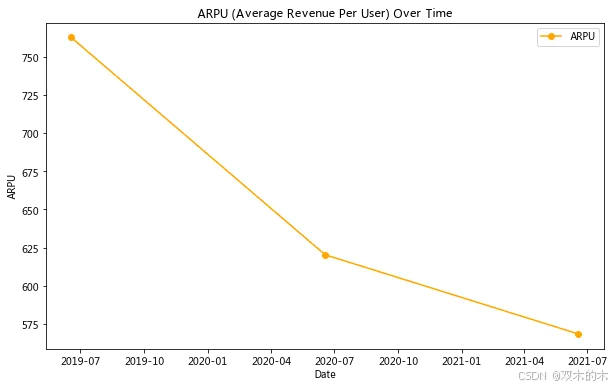
2021年618的表现不如2020年,可能的原因包括:
促销力度不够:2021年可能没有提供足够吸引力的折扣和活动,导致用户和销售额减少。
用户流失或兴趣下降:活动的吸引力不如前一年,可能导致了用户的流失或部分用户的消费热情下降。
市场竞争增加:2021年可能有其他电商平台的强力竞争,使得部分用户转向其他平台消费。
# import matplotlib.font_manager# fonts = [f.name for f in matplotlib.font_manager.fontManager.ttflist]# print("Available Fonts:", fonts)
# 提取年份并创建新的列df['日期']= df['BILLDATE'].dt.datedf['年份'] = df['BILLDATE'].dt.yeardf['日期']= df['日期'].astype('datetime64')# 查看结果print(df[['BILLDATE', '年份']].head())# 计算第 n 次消费df['第n次消费'] = df.groupby(by='会员号')['日期'].rank(ascending=True, method='dense')# 标记新老客df.loc[(~df['年份'].isnull()) & (df['第n次消费'] == 1), '新老客'] = '新客'df.loc[(~df['年份'].isnull()) & (df['第n次消费'] > 1), '新老客'] = '老客'# 查看结果print(df[['会员号', '日期', '第n次消费', '新老客']].head())# 618已购的老客vip_618 = df[(df['年份']==2021.0)&(df['新老客']=='老客')][['会员号']].drop_duplicates()# 筛选出未在 618 活动中消费的老客户vip_no_618 = (df[(df['BILLDATE'] < '2021-06-12') & (df['第n次消费'] > 1) & (~df['会员号'].isin(vip_618['会员号']))][['会员号']].drop_duplicates().sample(n=len(vip_618)))# 筛选老订单old_orders = df[(df['BILLDATE'] < '2021-06-12') & (df['会员号'].isin(vip_618['会员号'].append(vip_no_618['会员号'])))]# 计算累计消费金额和最近消费日期rfm = old_orders.groupby(by='会员号').agg({'订单金额': 'sum', 'BILLDATE': 'max'}).rename(columns={'订单金额': '累计消费金额', 'BILLDATE': '最近消费日期'})# 计算消费频次f = old_orders.groupby(by='会员号').agg({'BILLDATE': pd.Series.nunique}).rename(columns={'BILLDATE': '消费频次'})# 合并累计消费金额、最近消费日期和消费频次rfm = pd.concat([rfm, f], axis=1)# 计算最近消费间隔rfm['最近消费间隔'] = (datetime(2021, 6, 1) - rfm['最近消费日期']).dt.days# 设置“消费”列,根据会员号是否在指定列表中进行标记rfm.loc[rfm.index.isin(vip_618['会员号']), '消费'] = 1rfm.loc[rfm.index.isin(vip_no_618['会员号']), '消费'] = 0# 重置索引rfm = rfm.reset_index()# 确保“消费”列为整数类型rfm['消费'] = rfm['消费'].astype(int)# 检查 RFM 数据的类型print(rfm.dtypes)print(rfm.head())
输出:
BILLDATE 年份0 2019-06-27 14:50:54 20191 2019-06-27 14:50:54 20192 2019-06-27 14:50:54 20193 2019-06-27 14:50:29 20194 2019-06-27 14:50:54 2019会员号 日期 第n次消费 新老客0 14577169286 2019-06-27 1.0 新客1 18670076440 2019-06-27 1.0 新客2 15138684493 2019-06-27 1.0 新客3 13529513483 2019-06-27 1.0 新客4 15256290464 2019-06-27 1.0 新客会员号 int64累计消费金额 float64最近消费日期 datetime64[ns]消费频次 int64最近消费间隔 int64消费 int64dtype: object会员号 累计消费金额 最近消费日期 消费频次 最近消费间隔 消费0 13010069876 843.42 2020-11-03 21:02:44 2 209 01 13010389927 629.95 2021-05-10 16:37:06 1 21 12 13010766215 1917.51 2018-07-02 03:58:23 2 1064 03 13011771547 4052.62 2019-09-10 13:25:07 4 629 04 13011814453 269.53 2021-06-08 00:45:21 1 -8 1
# 对 RFM 进行评分(假设 R、F、M 各分为 5 级)rfm['R_Score'] = pd.qcut(rfm['最近消费间隔'], 5, labels=[5, 4, 3, 2, 1]).astype(int)rfm['F_Score'] = pd.qcut(rfm['消费频次'], 2, labels=[1, 5], duplicates='drop').astype(int)rfm['M_Score'] = pd.qcut(rfm['累计消费金额'], 5, labels=[1, 2, 3, 4, 5], duplicates='drop').astype(int)# 计算 RFM 总分rfm['RFM_Score'] = rfm['R_Score'] + rfm['F_Score'] + rfm['M_Score']# RFM 分类规则(示例分类规则,可根据实际情况调整)def classify_rfm(row):if row['R_Score'] >= 4 and row['F_Score'] >= 4 and row['M_Score'] >= 4:return '重要价值客户'elif row['R_Score'] >= 4 and row['F_Score'] >= 4:return '重要发展客户'elif row['R_Score'] >= 3 and row['F_Score'] >= 3:return '重要保持客户'elif row['R_Score'] == 1:return '重要挽留客户'else:return '一般客户'rfm['客户分类'] = rfm.apply(classify_rfm, axis=1)# print(rfm[['会员号', '累计消费金额', '最近消费日期', '消费频次', '最近消费间隔', '消费', 'R_Score', 'F_Score', 'M_Score', 'RFM_Score', '客户分类']])
开始绘图。
import matplotlib.pyplot as plt# 统计不同客户类型的数量customer_type_counts = rfm['客户分类'].value_counts()# 绘制饼图plt.figure(figsize=(8, 6))customer_type_counts.plot(kind='pie', autopct='%1.1f%%', startangle=90, colors=['#ff9999','#66b3ff','#99ff99','#ffcc99'])plt.title('客户类型分布')plt.ylabel('')plt.show()
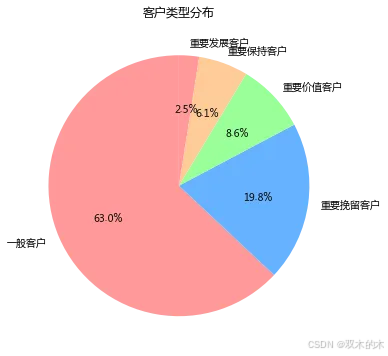
一般客户和重要挽留客户占比较大。
货(商品分析)
# 商品分类销量和销售额统计class_sales = df.groupby(['ClassI', 'ClassII']).agg({'QTY': 'sum','AMOUNTRETAIL': 'sum'}).reset_index()# 显示结果print(class_sales)
输出:
ClassI ClassII QTY AMOUNTRETAIL0 手袋 单肩包 96600.0 1.255087e+081 手袋 双肩包 57608.0 8.221095e+072 手袋 手拿包 804.0 2.987113e+053 手袋 手提包 43367.0 6.257863e+074 手袋 斜挎包 252337.0 2.870787e+085 手袋 腰包 5046.0 5.065502e+06
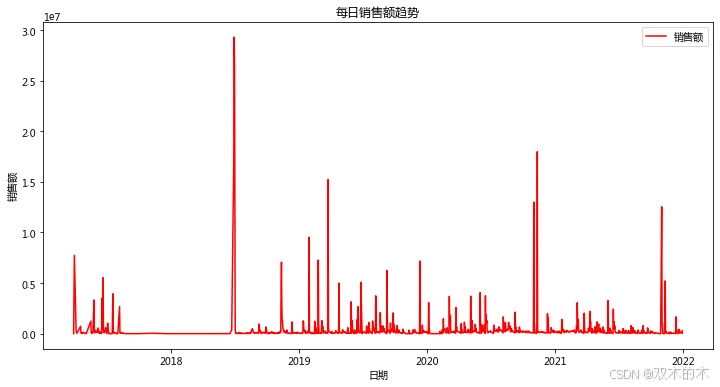
# 将BILLDATE转换为日期df['date'] = df['BILLDATE'].dt.date# 按日期统计销量和销售额sales_trend = df.groupby('date').agg({'QTY': 'sum','AMOUNTRETAIL': 'sum'}).reset_index()# 绘制销售趋势图plt.figure(figsize=(12, 6))plt.plot(sales_trend['date'], sales_trend['AMOUNTRETAIL'], label='销售额', color='red')plt.xlabel('日期')plt.ylabel('销售额')plt.title('每日销售额趋势')plt.legend()plt.show()
# 找出销量最高的前10个产品top_products = df.groupby('ProductName').agg({'QTY': 'sum','AMOUNTRETAIL': 'sum'}).reset_index().sort_values(by='QTY', ascending=False).head(10)print(top_products)
输出如下:
ProductName QTY AMOUNTRETAIL7 方形包 155481.0 1.880299e+088 桶包 68153.0 8.192661e+0713 背包 57575.0 8.210963e+070 信封包 39331.0 4.367825e+0711 波士顿包 27291.0 3.289634e+0717 购物袋 25864.0 3.114452e+0719 饺子包 15829.0 1.619862e+0716 贝壳包 15307.0 1.707305e+071 公事包 10398.0 1.797838e+072 剑桥包 7391.0 6.979334e+06
结论:
方形包销量最高,销售额也最大,显示出很高的市场需求。这可能是因为它的款式或功能符合大部分消费者的需求。
桶包和背包也有很高的销量和销售额,这些产品可能是主力产品,在消费者群体中接受度较高。
购物袋、饺子包、贝壳包等产品的销量相对较低,但销售额相对较高,说明这些产品单价较高。
# 价格区间分组df['价格区间'] = pd.cut(df['订单金额'], bins=[0, 500, 1000, 1500, 2000, np.inf], labels=['0-500', '500-1000', '1000-1500', '1500-2000', '2000以上'])price_sensitivity = df.groupby('价格区间').agg({'QTY': 'sum','AMOUNTRETAIL': 'sum'}).reset_index()print(price_sensitivity)
输出:
价格区间 QTY AMOUNTRETAIL0 0-500 212729.0 2.332865e+081 500-1000 191541.0 2.550952e+082 1000-1500 41221.0 5.966882e+073 1500-2000 7849.0 1.074455e+074 2000以上 2422.0 3.946177e+06
0-500元和500-1000元的产品是销售的主力,这两个价格区间的销量和销售额最高。这可能表明顾客更倾向于购买价格较低的商品,这类商品符合大众消费的需求。
场(渠道分析)
# 按月汇总销售数据df['YearMonth'] = df['BILLDATE'].dt.to_period('M')monthly_sales = df.groupby('YearMonth')['订单金额'].sum().reset_index()plt.figure(figsize=(12, 6))plt.plot(monthly_sales['YearMonth'].astype(str), monthly_sales['订单金额'], color='b', marker='o')plt.xlabel('年月')plt.ylabel('月度销售额')plt.title('月度销售趋势分析')plt.xticks(rotation=45)plt.show()
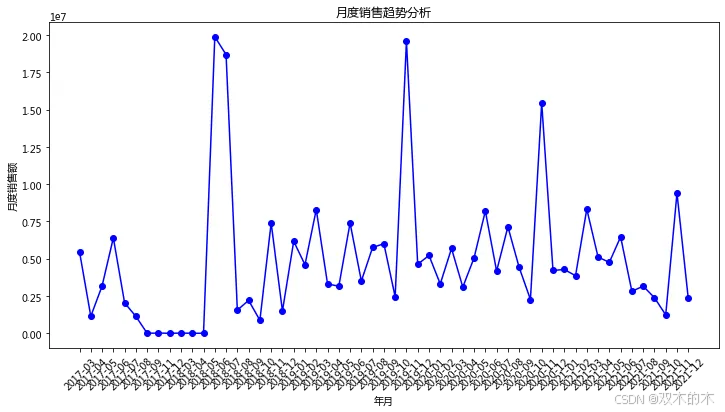
# 计算每位客户的累计消费金额和订单数量customer_sales = df.groupby('会员号').agg({'订单金额': 'sum','订单号': 'nunique'}).rename(columns={'订单金额': '累计消费金额', '订单号': '订单数量'})# print(customer_sales)
# 产品偏好分析product_sales = df.groupby(['ClassI', 'ClassII'])['订单金额'].sum().reset_index()top_products = product_sales.sort_values(by='订单金额', ascending=False).head(5)plt.figure(figsize=(12, 6))plt.barh(top_products['ClassI'] + ' ' + top_products['ClassII'], top_products['订单金额'], color='skyblue')plt.xlabel('销售额')plt.ylabel('产品分类')plt.title('前5热销产品分类分析')plt.gca().invert_yaxis()plt.show()
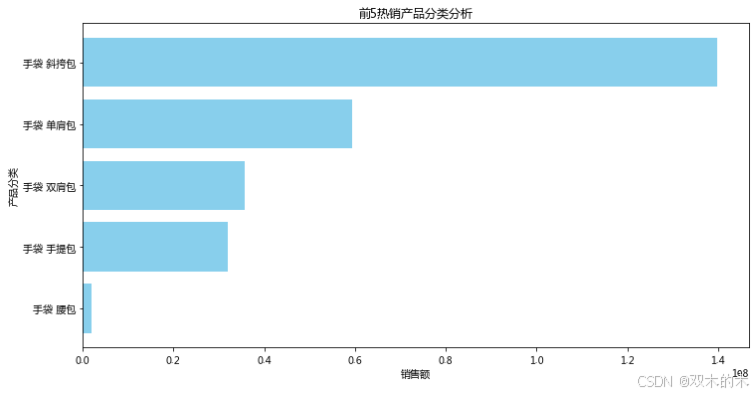
斜挎包销售更好。
# 计算每个订单的订单金额和数量order_analysis = df.groupby('订单号').agg({'订单金额': 'sum','QTY': 'sum'}).rename(columns={'订单金额': '订单总金额', 'QTY': '总购买量'})
plt.figure(figsize=(12, 6))# 绘制月度销售趋势图plt.plot(monthly_sales['YearMonth'].astype(str), monthly_sales['订单金额'], color='b', marker='o')plt.xlabel('年月', fontsize=12)plt.ylabel('月度销售额', fontsize=12)plt.title('月度销售趋势图', fontsize=14)plt.xticks(rotation=45) # 横坐标倾斜45度,便于阅读plt.tight_layout() # 自动调整子图参数,填充图像区域plt.show()
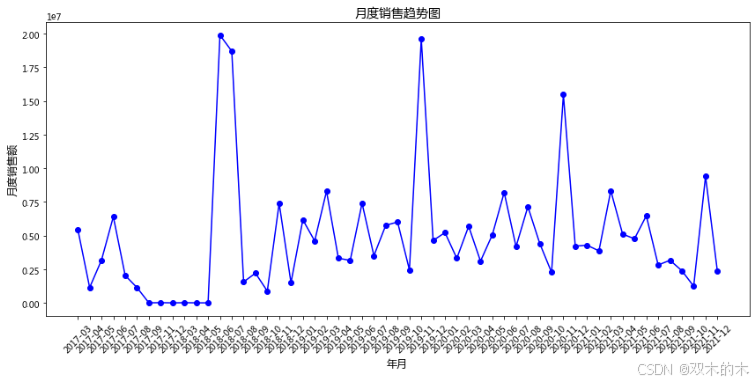
# 促销力度分析df['Discount'] = (df['AMOUNTRETAIL'] - df['订单金额']) / df['AMOUNTRETAIL']avg_discount = df.groupby('YearMonth')['Discount'].mean()plt.figure(figsize=(10, 6))plt.plot(avg_discount.index.astype(str), avg_discount.values, marker='o', color='purple', label='平均折扣率')plt.title('月度平均折扣率趋势')plt.xlabel('月份')plt.ylabel('平均折扣率')plt.xticks(rotation=45) # 横坐标倾斜45度,便于阅读plt.legend()plt.show()
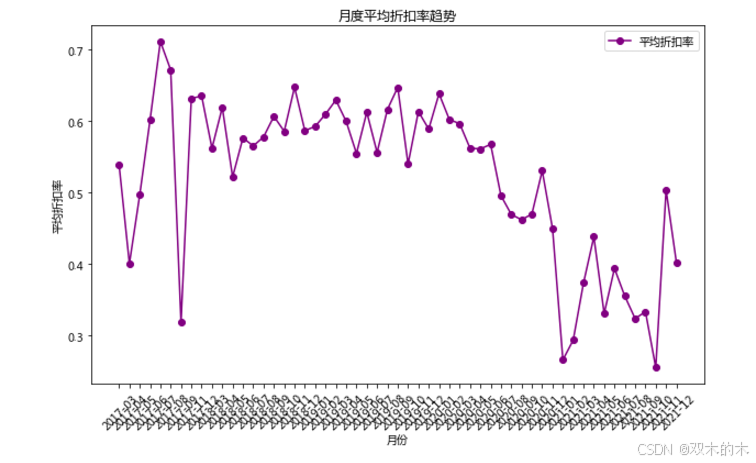
618的折扣力度越来越小。
# 按产品名称和年份统计每年618期间的销量和销售额product_analysis = df_618.groupby(['year', 'ProductName']).agg({'QTY': 'sum', 'AMOUNTRETAIL': 'sum'}).reset_index()# print("各年618期间不同产品销量和销售额数据:")# print(product_analysis)import seaborn as snsplt.figure(figsize=(12, 8))sns.barplot(x='year', y='QTY', hue='ProductName', data=product_analysis)plt.title('各年618期间不同产品销量对比')plt.xlabel('年份')plt.ylabel('销量')plt.xticks(rotation=45)plt.legend(title='产品名称')plt.show()# 销售额对比plt.figure(figsize=(12, 8))sns.barplot(x='year', y='AMOUNTRETAIL', hue='ProductName', data=product_analysis)plt.title('各年618期间不同产品销售额对比')plt.xlabel('年份')plt.ylabel('销售额')plt.xticks(rotation=45)plt.legend(title='产品名称')plt.show()
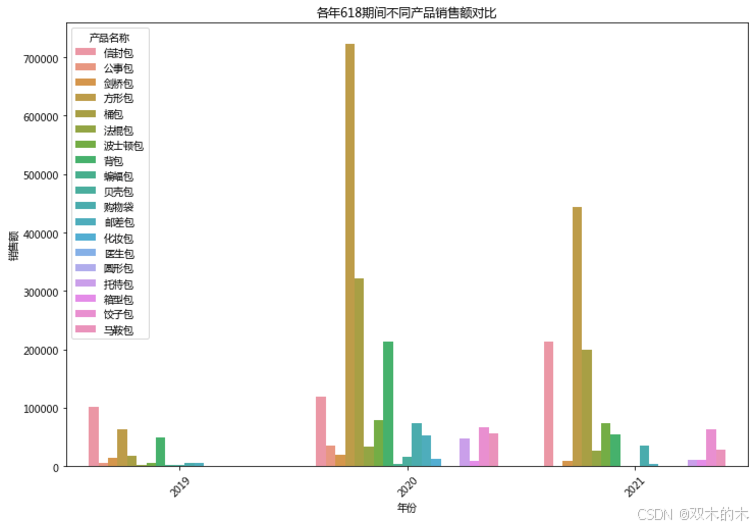
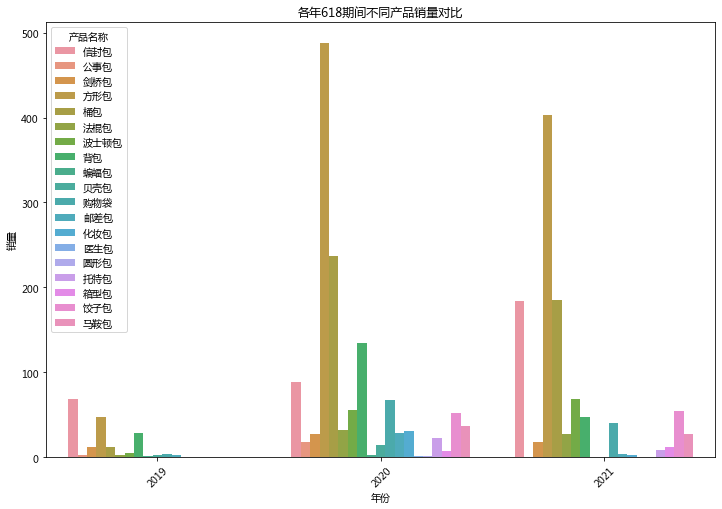
结论:
从2019年到2021年,可以看到一些新产品(如化妆包、圆形包、医生包等)在销量和销售额上表现较好,特别是2020年。产品种类的多样化可能吸引了更多消费者。
方形包和桶包在销量和销售额上显著增长,尤其是在2020年。这可能反映出消费者的购买偏好发生了变化,或是由于促销活动或市场趋势的推动。
背包在2020年销量和销售额较高,但在2021年有所下降,表明市场对背包的需求减少,可能是由于产品同质化或消费趋势的变化。
# 添加价格区间字段df_618['price_range'] = pd.cut(df_618['AMOUNTRETAIL'], bins=[0, 500, 1000, 1500, 2000, float('inf')], labels=['0-500', '500-1000', '1000-1500', '1500-2000', '2000以上'])# 按年份和价格区间统计销量和销售额price_analysis = df_618.groupby(['year', 'price_range']).agg({'QTY': 'sum', 'AMOUNTRETAIL': 'sum'}).reset_index()# print("各年618期间不同价格区间的销量和销售额数据:")# print(price_analysis)# 绘制价格区间对比图plt.figure(figsize=(12, 8))sns.barplot(x='year', y='QTY', hue='price_range', data=price_analysis)plt.title('各年618期间不同价格区间的销量对比')plt.xlabel('年份')plt.ylabel('销量')plt.xticks(rotation=45)plt.legend(title='价格区间')plt.show()
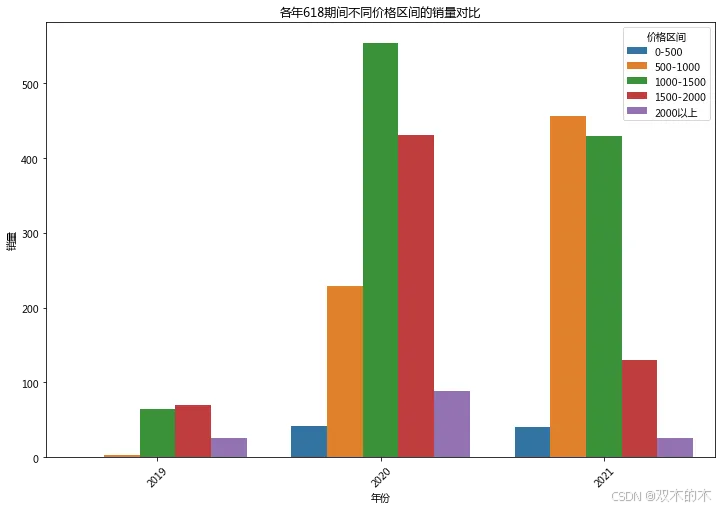
结论:2020年和2021年,许多消费者选择了更高价格区间的产品,可能是由于促销活动的影响,或者市场上出现了更多具有吸引力的中高端产品。
给出建议
结论:
618销售下降,原因:
人:用户购买力度不够,一般客户占比太高,日活跃用户和付费用户数都有所下降。
货:商品结构发生了一些改变。
场:618商品的折扣力度少了。
业务建议:
随着时间推移,消费者的购买偏好逐渐向中高价区间产品倾斜,并且整体的市场需求有所增长。
可以考虑加强对热销产品(如方形包、桶包等)的推广,并且关注新兴市场需求(如化妆包、圆形包等)。
在促销力度、用户活跃提升和吸引新用户方面做出调整,以达到更好的营销效果。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









