







本文来源公众号“陪跑jasper”,仅用于学术分享,侵权删,干货满满。
原文链接:Milvus快速入门(常用demo)
前言:网络中充斥很多Milvus讲解,但我觉得很多概念没有介绍到,导致看起来很费劲,故此写下次快速入门,让你快速入门
1.Milvus简介
Milvus是一款开源的高性能、高可用的向量数据库,专为大规模机器学习和深度学习应用设计,旨在高效管理和检索高维向量数据。以下是Milvus的详细介绍:
一、基本信息
-
名称:Milvus
-
类型:向量数据库
-
开发:由Zilliz开发并维护,后成为LF AI & Data Foundation的托管项目之一
-
创建时间:2019年
-
特点:高性能、高可用、云原生、易拓展
二、主要功能与特性
-
高效存储与索引:
-
专门设计用于存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大量嵌入向量。
-
能够在万亿规模上对向量进行索引,支持针对TB级向量的增删改操作和近实时查询。
-
高性能检索:
-
通过优化的索引算法(如IVF、ANNOY、HNSW等)和分布式架构,实现亚秒级的向量检索速度。
-
支持多种索引类型,可以根据数据特性和查询需求选择最合适的索引策略。
-
高可用与可扩展性:
-
支持集群部署,提供数据容错和自动恢复机制,确保服务的高可用性。
-
采用存储与计算分离的云原生设计,易于在Kubernetes等容器编排平台上部署,支持横向扩展。
-
混合查询能力:
-
在向量相似度检索过程中支持对标量字段进行过滤,实现混合查询,进一步提高召回率和搜索灵活性。
-
易用性:
-
提供丰富的API接口,支持Python、Java、Go等多种编程语言,易于集成到现有系统中。
-
提供了一整套简单直观的API,让用户可以针对不同场景选择不同的索引类型。
三、系统架构与组件
Milvus采用模块化设计,主要由以下几个核心组件构成:
-
Proxy:作为客户端请求的入口,负责负载均衡、路由请求、认证和鉴权。
-
IndexNode:负责构建和维护向量索引。
-
QueryNode:负责向量检索,执行搜索请求。
-
DataCoord:管理数据和索引的分配,以及数据的迁移和平衡。
-
DataNode:实际存储向量数据和索引文件。
-
MetaStore:存储所有元数据,包括集合(Collection)信息、分区(Partition)信息、索引信息等。
四、应用场景
Milvus在多个领域有着广泛的应用,包括但不限于:
-
图像搜索:通过提取图像特征向量,实现相似图片查找,应用于电商、社交网络的图片搜索功能。
-
文本相似度匹配:将文本转化为向量,应用于新闻推荐、问答系统中的相似问题匹配。
-
语音识别:将音频特征转换为向量,用于语音搜索、语音助手的命令识别。
-
推荐系统:结合用户行为、商品特征等向量,优化个性化推荐算法。
五、总结
Milvus作为一款专为AI时代设计的向量数据库,其高效、灵活的特性使其成为处理非结构化数据检索的理想选择。无论是科研项目还是企业级应用,Milvus都能提供强大的支撑。随着AI应用的不断深化,Milvus及其生态系统将持续发展,为开发者带来更多创新的可能性。
2.安装
环境准备
window11 wsl for window
docker,docker-compose
这些配置环境自行处理,网上很多相关介绍
tip:你可能会遇到wsl for window环境配置连接宿主机docker环境的问题,请参考https://learn.microsoft.com/zh-cn/windows/wsl/tutorials/wsl-containers
通过docker安装
wget https://github.com/milvus-io/milvus/releases/download/v2.4.5/milvus-standalone-docker-compose.yml -O docker-compose.yml#安装sudo docker compose up -dCreating milvus-etcd ... doneCreating milvus-minio ... doneCreating milvus-standalone ... done@#关闭sudo docker compose downsudo rm -rf volumes
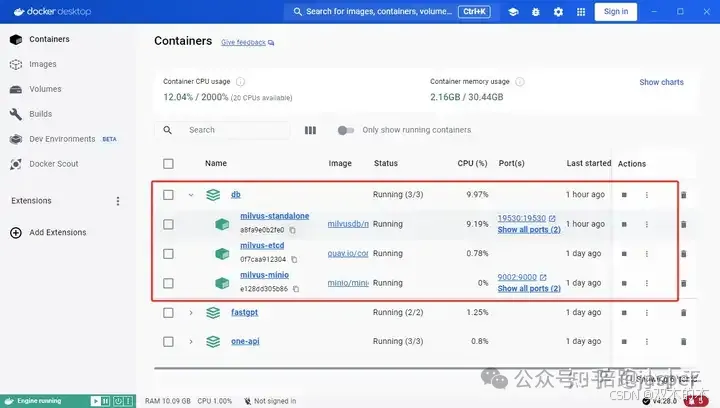
2.脚本demo(重点)
这里是讲解重点,通过解读官方脚本,让你知道一些Milvus实现原理和一些概念
下载官方demo脚本
wget https://raw.githubusercontent.com/milvus-io/pymilvus/v2.2.8/examples/hello_milvus.py
运行脚本
python hello_milvus.py
=== start connecting to Milvus ===
Does collection hello_milvus exist in Milvus: False
=== Create collection `hello_milvus` ===
=== Start inserting entities ===
Number of entities in Milvus: 3000
=== Start Creating index IVF_FLAT ===
=== Start loading ===
=== Start searching based on vector similarity ===
hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911
hit: id: 1262, distance: 0.08883658051490784, entity: {'random': 0.2978858685751561}, random field: 0.2978858685751561
hit: id: 1265, distance: 0.09590047597885132, entity: {'random': 0.3042039939240304}, random field: 0.3042039939240304
hit: id: 2999, distance: 0.0, entity: {'random': 0.02316334456872482}, random field: 0.02316334456872482
hit: id: 1580, distance: 0.05628091096878052, entity: {'random': 0.3855988746044062}, random field: 0.3855988746044062
hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368
search latency = 0.4380s
=== Start querying with `random > 0.5` ===
query result:
-{'random': 0.6378742006852851, 'embeddings': [0.20963514, 0.39746657, 0.12019053, 0.6947492, 0.9535575, 0.5454552, 0.82360446, 0.21096309], 'pk': '0'}
search latency = 0.2158s
query pagination(limit=4):
data: ["{'random': 0.6378742006852851, 'pk': '0'}", "{'random': 0.5763523024650556, 'pk': '100'}", "{'random': 0.9425935891639464, 'pk': '1000'}", "{'random': 0.7893211256191387, 'pk': '1001'}"] , extra_info: {'cost': 0}
query pagination(offset=1, limit=3):
data: ["{'random': 0.5763523024650556, 'pk': '100'}", "{'random': 0.9425935891639464, 'pk': '1000'}", "{'random': 0.7893211256191387, 'pk': '1001'}"] , extra_info: {'cost': 0}
=== Start hybrid searching with `random > 0.5` ===
hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911
hit: id: 747, distance: 0.14606499671936035, entity: {'random': 0.5648774800635661}, random field: 0.5648774800635661
hit: id: 2527, distance: 0.1530652642250061, entity: {'random': 0.8928974315571507}, random field: 0.8928974315571507
hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368
hit: id: 2034, distance: 0.20354536175727844, entity: {'random': 0.5526117606328499}, random field: 0.5526117606328499
hit: id: 958, distance: 0.21908017992973328, entity: {'random': 0.6647383716417955}, random field: 0.6647383716417955
search latency = 0.4029s
=== Start deleting with expr `pk in ["0" , "1"]` ===
query before delete by expr=`pk in ["0" , "1"]` -> result:
-{'random': 0.6378742006852851, 'embeddings': [0.20963514, 0.39746657, 0.12019053, 0.6947492, 0.9535575, 0.5454552, 0.82360446, 0.21096309], 'pk': '0'}
-{'random': 0.43925103574669633, 'embeddings': [0.52323616, 0.8035404, 0.77824664, 0.80369574, 0.4914803, 0.8265614, 0.6145269, 0.80234545], 'pk': '1'}
query after delete by expr=`pk in ["0" , "1"]` -> result: data: [] , extra_info: {'cost': 0}
=== Drop collection `hello_milvus` ===导入的包
from pymilvus import (
connections,
utility,
FieldSchema,
CollectionSchema,
DataType,
Collection,
)
from pymilvus import:我们需要用到一个叫做 “pymilvus” 的工具箱(代码库)。
connections, utility,:这里我们要使用工具箱里的两个工具,一个叫做 “connections” ,
它可以帮你连接到球袋(数据库);另一个叫做 “utility”,它具有一些用来操作和管理球的实用功能。
FieldSchema, CollectionSchema,:这两个就像是制作球袋子的模板,
告诉你如何形状和规格,以适应各种各样的魔术球。
DataType,:这个工具告诉抓手如何识别不同种类的球,如何把圆的球和方的球分开。
Collection,:最后,我们用 “Collection” 这个工具来创建一个可以容纳球的特殊袋子1. 连接到Milvus
connections.connect("default", host="localhost", port="19530")
这行代码就是告诉电脑如何(connections)连接到球袋子,袋子在哪里以及如何打开袋子。
default:我们给这个连接起一个名字,叫做 “default”,这样以后我们需要连接的时候就知道用这个名字找到这个袋子。
host="localhost":这里告诉抓手袋子在哪里。"localhost"告诉电脑,这个袋子就在当前电脑而不是在别的电脑上。
port="19530":这里告诉抓手如何打开袋子。“19530”就像是一个密码或钥匙,具有正确的“端口号”才能进入袋子并接触到魔术球。2. 创建集合
# We're going to create a collection with 3 fields.
# +-+------------+------------+------------------+------------------------------+
# | | field name | field type | other attributes | field description |
# +-+------------+------------+------------------+------------------------------+
# |1| "pk" | VarChar | is_primary=True | "primary field" |
# | | | | auto_id=False | |
# +-+------------+------------+------------------+------------------------------+
# |2| "random" | Double | | "a double field" |
# +-+------------+------------+------------------+------------------------------+
# |3|"embeddings"| FloatVector| dim=8 | "float vector with dim 8" |
# +-+------------+------------+------------------+------------------------------+
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=False, max_length=100),
FieldSchema(name="random", dtype=DataType.DOUBLE),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=dim)
]
schema = CollectionSchema(fields, "hello_milvus is the simplest demo to introduce the APIs"
hello_milvus = Collection("hello_milvus", schema, consistency_level="Strong")
fileds中每个FieldSchema就类似table中的字段,而集合collection就类似table,通过Collection("hello_milvus", schema, consistency_level="Strong")
就创建了一个名称hello_milvus的集合
fileds中的有三个字段,分别为
pk(主键,varchar,不是自增长,最大100)
random(double)
embeddings(这里是主要的向量字段向量维度是8)
总结,这个集合存放了标量字段pk,random,还有一个向量字段embedding,后面你会知道我们是在向量字段上做索引,milvus中有队向量的查询也有针对标量的查询(这也是milvus的特点)3. 插入数据
#创建一个随机数生成器
rng = np.random.default_rng(seed=19530)
#生成实体集合
entities = [
#这是一个列表推导式,它生成一个字符串列表,每个字符串都是其索引的字符串表示(从0到num_entities-1)。这里假设num_entities是一个之前已经定义好的整数,表示实体的数量。
[str(i) for i in range(num_entities)],
#使用之前创建的随机数生成器rng生成num_entities个在[0.0, 1.0)范围内的随机浮点数,并将这些数转换为列表。这个字段可能代表某种随机属性或特征
rng.random(num_entities).tolist(), # field random, only supports list
#rng.random被用来生成一个形状为(num_entities, dim)的二维数组,其中num_entities是实体的数量,dim是每个实体特征的维度。这个数组包含了num_entities个实体的dim维特征向量
rng.random((num_entities, dim)), # field embeddings, supports numpy.ndarray and list
]
insert_result = hello_milvus.insert(entities)
#将数据刷入内存
hello_milvus.flush()
你可能对entities(实体集合)生成的内容没有概念,下面有一个生成好的例子供你理解
[
实体ID:
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
随机字段:
[0.6027633766236169, 0.5448831518554688, 0.42365479933823485, 0.6458941133784569, 0.4375872112301515, 0.8917730007874779, 0.963662760780268, 0.3834417152500153, 0.7917250385694923, 0.5288949254489236]
嵌入字段:
[[0.417022 0.72032449 0.00011437]
[0.30233256 0.14675589 0.09233859]
[0.18626021 0.34556073 0.39676747]
[0.53881673 0.41919451 0.9852778 ]
[0.83261985 0.26726124 0.77815675]
[0.87001215 0.97861834 0.79515622]
[0.46147936 0.78052918 0.11827443]
[0.65167377 0.64589411 0.44488315]
[0.4236548 0.64589411 0.43758721]
[0.891773 0.96366276 0.38344172]]
]4. 创建索引
index = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
hello_milvus.create_index("embeddings", index)
创建索引的作用
在向量数据库中,索引是用于加速向量查询的关键技术。对于"embeddings"这样的字段,它通常包含高维向量数据(如深度学习模型的输出)。由于高维空间中的向量距离计算通常非常耗时,特别是在数据集很大的情况下,直接计算每个查询向量与数据库中所有向量的距离是不可行的。因此,通过创建索引,Milvus能够显著减少需要计算距离的向量数量,从而加快查询速度。
创建索引的原理
对于"index_type": "IVF_FLAT"这种索引类型,它基于一种称为**Inverted File System (IVF)**的索引结构。IVF是一种多级的索引结构,它首先将向量空间划分为多个子空间(cells),这个过程通常是通过某种聚类算法(如K-means)实现的。每个子空间包含一组向量,并且有一个与之关联的“量化中心”(centroid),该中心代表了子空间内向量的某种“平均”或“中心”位置。
查询时,Milvus首先计算查询向量与所有量化中心的距离,找出最近的几个量化中心(即子空间)。然后,它只在这些子空间内搜索与查询向量相近的向量,而不是在整个数据集中搜索。这种方法大大减少了需要计算距离的向量的数量,从而提高了查询效率。
参数作用和意思
"index_type": "IVF_FLAT": 指定索引类型为IVF_FLAT。这里的FLAT意味着在每个子空间内部,向量是直接存储的,没有进一步的索引或压缩。这意味着查询性能依赖于子空间的大小和数量的平衡。
"metric_type": "L2": 指定距离度量为L2距离(欧几里得距离)。L2距离是计算两个向量之间相似度的一种常用方法,它通过计算两个向量差的平方和的平方根来得到。
"params": {"nlist": 128}: 这是一个参数字典,其中"nlist": 128指定了要划分的子空间(cells)的数量。这个参数对索引的性能有很大影响:nlist值较小时,每个子空间可能包含更多的向量,查询时需要检查更多的子空间以找到相关的向量,但每个子空间内部的搜索会更快;nlist值较大时,子空间数量增加,但每个子空间内的向量数量减少,查询时需要检查的子空间数量减少,但每个子空间内部的搜索可能会更慢(因为子空间内的向量数量仍然很多)。因此,选择合适的nlist值对于优化查询性能至关重要。
如何起作用
当这段脚本执行时,Milvus会根据提供的索引类型和参数在"embeddings"字段上创建索引。创建索引后,当执行向量查询时,Milvus会利用这个索引来加速查询过程,通过减少需要计算距离的向量的数量来提高查询效率。
子空间概念
在Milvus等向量数据库中,子空间(cells或buckets)是一个核心概念,它对于加速向量查询过程至关重要。以下是关于子空间概念的详细展开:
一、子空间的定义与作用
定义:
子空间是向量空间中的一个分区或集合,它包含了一组在某种度量标准下相似的向量。在Milvus中,子空间是通过聚类算法(如K-means)将向量空间划分为多个较小的区域来实现的。
作用:
减少搜索范围:通过将向量空间划分为多个子空间,查询时只需在包含查询向量最可能相似向量的几个子空间内进行搜索,从而显著减少了需要计算距离的向量数量。
提高查询效率:由于搜索范围被限制在少数几个子空间内,查询速度得以大幅提升。特别是在处理大规模向量数据集时,这种效果尤为明显。
二、子空间的创建与管理
创建:
在Milvus中,子空间的创建是索引构建过程的一部分。当用户为某个向量字段(如"embeddings")指定索引类型(如IVF_FLAT)和参数(如nlist,即子空间数量)时,Milvus会自动执行聚类算法来划分向量空间,并创建相应的子空间。
管理:
用户可以通过Milvus提供的API来管理和优化子空间。例如,可以根据数据分布和查询需求调整子空间的数量(nlist),或者重新构建索引以优化子空间的划分。
三、子空间与索引类型的关系
在Milvus中,不同的索引类型对子空间的处理方式有所不同。以IVF系列索引为例:
IVF_FLAT:在每个子空间内部,向量是直接存储的,没有进一步的索引或压缩。查询时,会在包含查询向量最相似向量的几个子空间内进行全量搜索。
IVF_SQ8、IVF_PQ等:这些索引类型在子空间内部采用了量化或压缩策略来进一步减少存储空间和加速查询。例如,PQ(Product Quantization)通过将向量划分为多个子向量,并对每个子向量进行量化来减少存储需求。查询时,会先计算查询向量与子空间量化中心的距离,然后在距离较近的子空间内部进行量化向量的搜索。
四、子空间与查询性能的关系
子空间的数量和划分方式直接影响查询性能。一般来说,子空间数量越多,每个子空间内的向量数量就越少,查询时需要检查的子空间数量也就越多。但是,由于每个子空间内部的搜索速度更快(因为向量数量少),所以总体查询时间可能会减少。然而,当子空间数量过多时,查询时间的减少可能不再明显,甚至可能因为管理大量子空间而增加额外的开销。
因此,在实际应用中,需要根据数据集的大小、分布和查询需求来选择合适的子空间数量(即nlist值),以达到最佳的查询性能。
五、总结
子空间是Milvus等向量数据库中用于加速向量查询的关键概念。通过将向量空间划分为多个子空间,并利用索引技术来管理这些子空间,Milvus能够显著减少查询时需要计算距离的向量数量,从而提高查询效率。在实际应用中,需要根据具体情况来选择合适的索引类型和子空间数量,以优化查询性能。5. 对实体进行搜索、查询和混合搜索
# Before conducting a search or a query, you need to load the data in `hello_milvus` into memory.
print(fmt.format("Start loading"))
hello_milvus.load()
# -----------------------------------------------------------------------------
# search based on vector similarity
print(fmt.format("Start searching based on vector similarity"))
#倒数第一个子项目(emedding字段对应的集合),内的倒数第二个到最后的元素,按照上面我提供的例子就是
#[0.4236548 0.64589411 0.43758721]
#[0.891773 0.96366276 0.38344172]
vectors_to_search = entities[-1][-2:]
search_params = {
"metric_type": "L2",
"params": {"nprobe": 10},
}
search_params是一个字典,包含了搜索操作所需的参数。
"metric_type": "L2" 指定了使用L2距离(欧几里得距离)作为向量相似度的度量标准。
"params": {"nprobe": 10} 是针对IVF(Inverted File System)索引类型的特定参数。nprobe指定了在搜索过程中要检查的量化中心(或子空间)的数量。增加nprobe的值可以提高搜索的召回率(即找到更多相似向量的可能性),但也会增加搜索时间。
执行搜索
#向量搜索
result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, output_fields=["random"])
#标量搜索
result = hello_milvus.query(expr="random > 0.5", output_fields=["random", "embeddings"])
# pagination
r1 = hello_milvus.query(expr="random > 0.5", limit=4, output_fields=["random"])
r2 = hello_milvus.query(expr="random > 0.5", offset=1, limit=3, output_fields=["random"])
#标量向量组合搜索
result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, expr="random > 0.5", output_fields=["random"])
start_time = time.time() 用于记录搜索操作开始的时间,以便后续可能进行性能分析。
hello_milvus.search(...) 是调用Milvus客户端(假设hello_milvus是已经初始化并连接到Milvus数据库的客户端实例)的search方法执行搜索操作。
vectors_to_search 是要搜索的向量列表。
"embeddings" 指定了在数据库中要搜索的字段名(在这个例子中,我们假设所有实体的嵌入向量都存储在这个字段中)。
search_params 是之前定义的搜索参数。
limit=3 指定了对于每个查询向量,只返回最相似的3个结果。
output_fields=["random"] 指定了返回结果中应包含的字段。然而,这里似乎有一个误解:通常,在向量搜索中,我们关注的是相似向量的ID和距离(或其他相似度分数),而不是像"random"这样的字段。如果"random"字段实际上包含了与搜索相关的有用信息(比如每个向量的某种随机属性),那么包含它是合理的;否则,这可能是一个错误,应该替换为像"_id"(如果Milvus使用这样的字段来存储向量ID)或自定义的、包含有用信息的字段名。
6. 通过主键删除实体
# You can delete entities by their PK values using boolean expressions.
ids = insert_result.primary_keys
expr = f'pk in ["{ids[0]}" , "{ids[1]}"]'
print(fmt.format(f"Start deleting with expr `{expr}`"))
result = hello_milvus.query(expr=expr, output_fields=["random", "embeddings"])
print(f"query before delete by expr=`{expr}` -> result: \n-{result[0]}\n-{result[1]}\n")
hello_milvus.delete(expr)
result = hello_milvus.query(expr=expr, output_fields=["random", "embeddings"])
print(f"query after delete by expr=`{expr}` -> result: {result}\n")7. 删除集合
# Finally, drop the hello_milvus collection
print(fmt.format("Drop collection `hello_milvus`"))
utility.drop_collection("hello_milvus")至此demo脚本解释结束
3.attu 可视化详解
docker run -p 8000:3000 -e MILVUS_URL={your machine IP}:19530 zilliz/attu:v2.2.6启动docker后,在浏览器中访问“http://{your machine IP}:8000”,点击“Connect”进入Attu服务。我们还支持TLS连接,用户名和密码
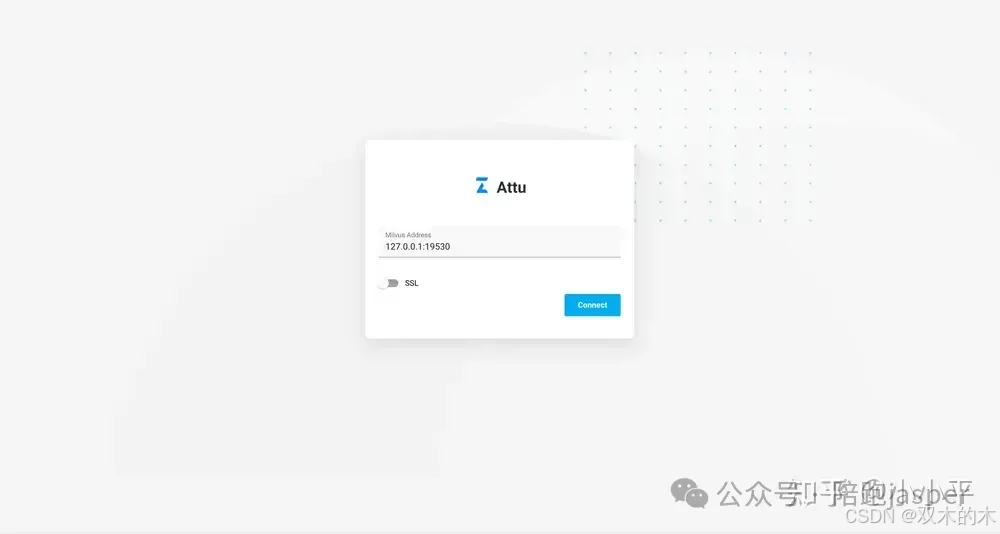
连接到Milvus服务:
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









