







 本文介绍目标检测中非极大值抑制技术,通过实例解释如何避免重复检测同一对象,确保每个对象仅被检测一次,提高算法准确性。
本文介绍目标检测中非极大值抑制技术,通过实例解释如何避免重复检测同一对象,确保每个对象仅被检测一次,提高算法准确性。
来源:Coursera吴恩达深度学习课程
目前为止的目标检测中可能出现的问题是你的算法可能对同一个对象做出多次检测。非极大值抑制(non-max suppression)这个方法可以确保你的算法对每个对象只检测一次,我们讲一个例子。

假设你需要在这张图片里检测行人和汽车,你可能会在上面放个19×19网格,理论上这辆车只有一个中点,所以它应该只被分配到一个格子里,左边的车子也只有一个中点,所以理论上应该只有一个格子做出有车的预测。

但是当你实际在运行算法时,会出现上图的情况,可能好几个格子会认为有车。
当你在361个格子上都运行一次图像检测和定位算法,最后可能会对同一个对象做出多次检测,所以非极大值抑制做的就是清理这些检测结果。这样一辆车只检测一次,而不是每辆车都触发多次检测。具体做法如下图:
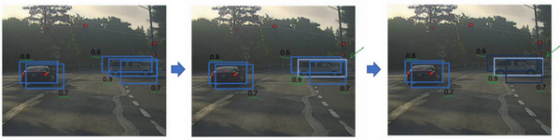
首先看概率最大的那个,这个例子(右边车辆)中p_c是0.9,然后就说这是最可靠的检测(most confident detection),所以我们就用高亮标记,表明这里找到了一辆车。这么做之后,非极大值抑制就会逐一审视剩下的矩形,所有和这个最大的边框有很高交并比(Intersection over union),高度重叠的其他边界框,那么这些输出就会被抑制。所以这两个矩形(p_c分别是0.6和0.7),和淡蓝色矩形重叠程度很高,所以会被抑制,变暗,表示它们被抑制了。
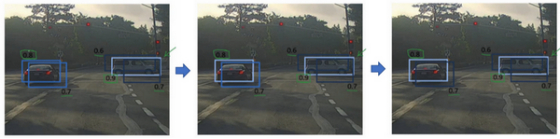
接下来,逐一审视剩下的矩形,找出概率最高,p_c最高的一个,在这种情况下是0.8,如上图,我们就认为这里检测出一辆车(左边车辆),然后非极大值抑制算法就会去掉其他loU值很高的矩形。所以现在每个矩形都会被高亮显示(highlighted)或者变暗(darkens),如果你直接抛弃变暗的矩形,那就剩下高亮显示的那些,这就是最后得到的两个预测结果。
所以这就是非极大值抑制(non-max suppression),非最大值意味着你只输出概率最大的分类结果,但抑制很接近,但不是最大的其他预测结果,所以这方法叫做非极大值抑制。
下面来看看算法的细节。假设这里只做汽车检测。

现在要实现非极大值抑制,你可以做的:
①第一件事是,去掉所有p_c小于某个阈值的边界框,这里假设是0.6,所以只是抛弃所有低概率(low probability)的边界框。
②接下来使用非极大值抑制,while循环的第一步你就一直选择概率p_c最高的边界框,取一个边界框,让它高亮显示,这样做出有一辆车的预测。
③while循环的第二步是上一步变暗的那些边界框以及和高亮标记的边界重叠面积很高的那些边界框抛弃掉。
到目前为止,Andrew只介绍了算法检测单个对象(a single object)的情况,如果你尝试同时检测三个对象,比如说行人、汽车、摩托,那么输出向量就会有三个额外的分量(three additional components)。事实证明,正确的做法是独立进行三次非极大值抑制,对每个输出类别都做一次。
这就是非极大值抑制,如果你能实现我们说过的目标检测算法,你其实可以得到相当不错的结果。
说明:记录学习笔记,如果错误欢迎指正!转载请联系我。

















 66
66

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









