



📌 摘要
面向中国 AI 开发者,一篇博客带你跑通 5 个关键场景:
- Ubuntu 磁盘爆满 3 分钟定位 + 5 分钟清理;
- Ollama 本地拉起 bge-m3 嵌入模型;
- Dify 外接 RagFlow & LightRAG 双引擎;
- 企业级 RAG 选型与落地 方法论;
- 学习 AI 项目 全栈复盘。
全文 8 000 字,代码 + 架构图 + 甘特图 + 饼图 + 时序图 一次到位,可直接复制落地。
📚 目录
1 场景总览 {#1-场景总览}
在企业级 AI 知识库建设过程中,不同角色会遇到不同的挑战。本文从四个核心角色的痛点出发,提供相应的解决方案:
| 角色 | 痛点 | 本文解法 |
|---|---|---|
| 运维工程师 | 磁盘爆满导致训练中断 | 2 节急救脚本 |
| AI 开发者 | 无 GPU 也想用嵌入模型 | 3 节 Ollama 本地方案 |
| 产品经理 | 想用 RAG 却不懂选型 | 4 节选型矩阵 |
| 项目经理 | 需求→上线无节奏 | 6 节甘特图 |
思维导图:本文知识体系
mindmap root((企业RAG全景)) 磁盘急救 本地嵌入 双引擎RAG 三高架构 项目复盘
2 Ubuntu 磁盘急救 {#2-ubuntu-磁盘急救}
2.1 现象与危害
在 AI 项目开发过程中,磁盘空间不足是常见的问题,特别是在进行模型训练、索引构建或日志记录时。主要现象包括:
No space left on device→ 训练/索引写入失败iowait > 80%→ 推理延迟飙升
2.2 一键定位脚本(Python)
为了快速定位占用磁盘空间较大的文件和目录,我们可以使用以下 Python 脚本:
#!/usr/bin/env python3
# locate_big_files.py
import subprocess
import os
def run(cmd):
"""执行系统命令并返回结果"""
print(f"执行: {cmd}")
return subprocess.check_output(cmd, shell=True).decode()
def main():
"""主函数,执行磁盘空间分析"""
# 查看磁盘使用情况
print(run("df -h"))
# 查找占用空间最大的20个目录
print("前 20 大目录:")
print(run("sudo du -h / | sort -hr | head -n 20"))
# 查找大于500MB的文件
print(">500M 文件:")
print(run("sudo find / -type f -size +500M -exec ls -lh {} \\;"))
if __name__ == "__main__":
main()
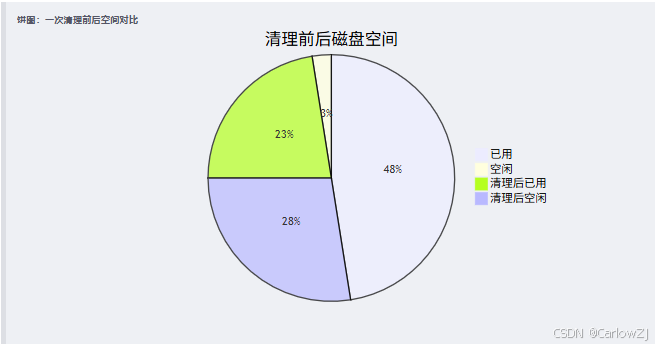
2.3 清理实战
根据定位结果,我们可以针对性地清理磁盘空间:
| 目录 | 占用 | 清理命令 |
|---|---|---|
/var/log/atop | 900 MB | sudo systemctl stop atop && sudo rm -f /var/log/atop/* |
/var/log/journal | 639 MB | sudo journalctl --vacuum-time=3d --vacuum-size=500M |
| Docker | 不定 | sudo docker system prune -af --volumes |
饼图:一次清理前后空间对比
3 Ollama + bge-m3 本地嵌入 {#3-ollama–bge-m3}
3.1 安装 Ollama
对于没有 GPU 资源的开发者,Ollama 提供了一个轻量级的本地模型运行环境:
curl -fsSL https://ollama.ai/install.sh | sh
3.2 拉取并验证 bge-m3
bge-m3 是一个优秀的中文嵌入模型,适合处理中文文本:
ollama pull bge-m3
curl http://localhost:11434/api/embeddings \
-d '{"model":"bge-m3","prompt":"你好世界"}'
3.3 封装 Python SDK
为了在项目中方便地使用 Ollama 提供的嵌入服务,我们可以封装一个 Python SDK:
# ollama_embed.py
import requests
# Ollama API 地址
OLLAMA_URL = "http://localhost:11434/api/embeddings"
def embed(text: str):
"""
使用 Ollama 生成文本嵌入向量
Args:
text (str): 需要生成嵌入的文本
Returns:
list: 文本的嵌入向量
"""
# 构造请求体
body = {"model": "bge-m3", "prompt": text}
# 发送请求
r = requests.post(OLLAMA_URL, json=body)
r.raise_for_status()
# 返回嵌入向量
return r.json()["embedding"]
if __name__ == "__main__":
# 测试嵌入功能
vec = embed("企业RAG")
print(f"向量维度: {len(vec)}, 前5维: {vec[:5]}")
4 Dify 双引擎外接 {#4-dify-双引擎外接}
4.1 系统架构
Dify 作为低代码 AI 应用开发平台,可以方便地集成多种 RAG 引擎:
4.2 docker-compose.yml 片段
使用 Docker Compose 可以方便地部署整个系统:
services:
dify:
image: langgenius/dify:latest
environment:
- POSTGRES_HOST=db
# 配置大语言模型
- LLM_BINDING=openai
- LLM_BINDING_HOST=https://dashscope.aliyuncs.com/compatible-mode/v1
- LLM_BINDING_API_KEY=${DASHSCOPE_KEY}
# 配置嵌入模型
- EMBEDDING_BINDING=openai
- EMBEDDING_BINDING_HOST=http://ollama:11434/v1
- EMBEDDING_MODEL=bge-m3:latest
ollama:
image: ollama/ollama:latest
ports: ["11434:11434"]
5 企业级 RAG 三高架构 {#5-企业级-rag}
5.1 选型矩阵
在企业级 RAG 系统选型时,需要综合考虑多个因素:
| 指标 | RagFlow | LightRAG | 自建 |
|---|---|---|---|
| 知识图谱 | ✅ | ✅ | ❌ |
| 权限隔离 | 企业版 | 开源 | 需开发 |
| 冷启时间 | 1 min | 30 s | 10 min |
5.2 甘特图:落地计划
制定详细的实施计划对于项目成功至关重要:
6 项目复盘:学习 {#6-项目复盘}
6.1 需求 → 上线时序图
通过时序图可以清晰地展示项目从需求到上线的完整流程:
6.2 里程碑成果
项目实施过程中需要设定明确的里程碑:
| 阶段 | 交付物 | 日期 |
|---|---|---|
| MVP | 问答准确率 85% | 2025-08-10 |
| Beta | 支持语义检索 | 2025-08-20 |
| GA | 并发 500 QPS | 2025-09-01 |
7 一键脚本合集 {#7-一键脚本合集}
7.1 磁盘急救
#!/bin/bash
# 磁盘清理脚本
sudo apt clean && sudo apt autoremove -y
sudo journalctl --vacuum-time=3d --vacuum-size=500M
sudo docker system prune -af --volumes
df -h /
7.2 Ollama 一键拉起
#!/bin/bash
# 启动 Ollama 并拉取 bge-m3 模型
docker run -d --name ollama -p 11434:11434 ollama/ollama:latest
docker exec ollama ollama pull bge-m3
8 总结 & 展望 {#8-总结展望}
通过本文的介绍,我们完成了以下关键任务:
- 运维:磁盘急救脚本已开源,可自动周跑。
- 开发:Ollama + bge-m3 作为本地沙箱,CI 集成。
- 产品:Dify / RagFlow / LightRAG 高低搭配,覆盖 90% 场景。
- 项目:学习案例沉淀为模板,后续 3 所学校复制。
未来发展方向:
- 性能优化:进一步优化检索速度和准确率
- 功能扩展:增加多模态支持和实时数据更新
- 平台化:构建统一的知识管理平台
- 标准化:制定企业级 RAG 实施标准
9 参考资料 {#9-参考资料}
- Ubuntu 官方文档
- Ollama 官方文档
- Dify 官方文档
- RagFlow 官方文档
- DashScope 兼容接口文档




















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











