






摘要
LLaMA-Factory作为大模型微调与部署的旗舰项目,其高质量数据准备与处理流程是模型效果的基石。本文系统梳理LLaMA-Factory数据采集、标注、清洗、增强、格式转换、自动化校验、管理与可视化等全流程,结合源码解读、配置实战、可视化图表、最佳实践与常见问题,助力中国AI开发者高效打造高质量训练数据集。
适用人群: AI应用开发者、机器学习工程师、数据工程师、科研人员、企业技术团队
目录
1. 知识体系思维导图
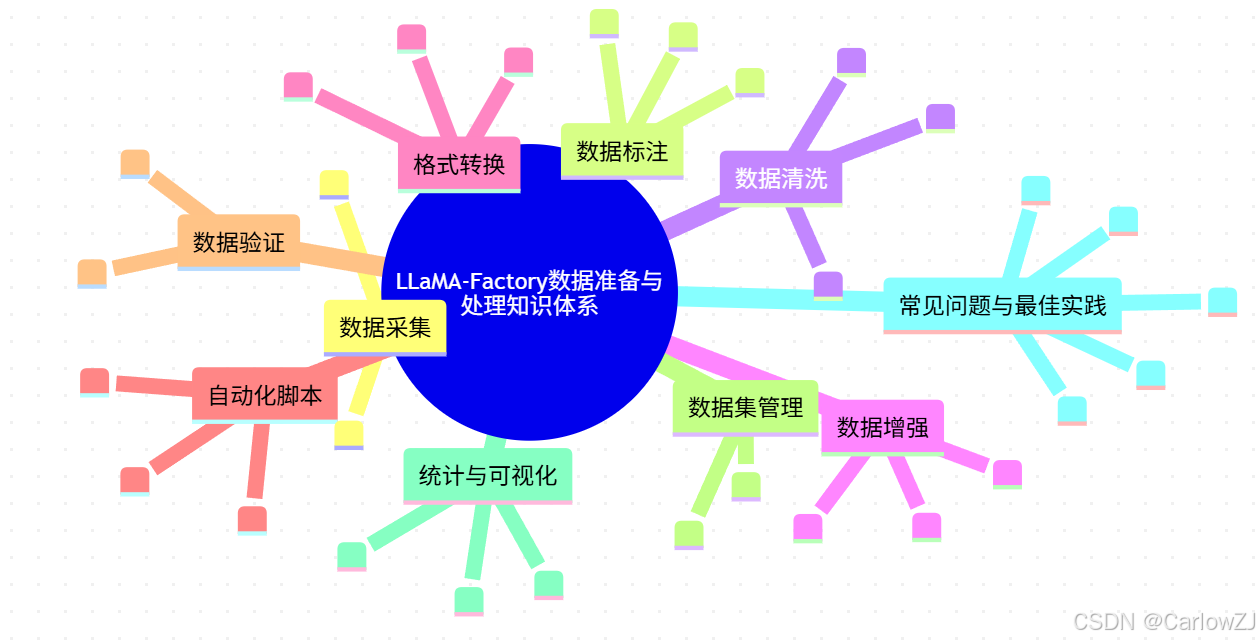
mindmap
root((LLaMA-Factory数据准备与处理知识体系))
数据采集
- 数据源调研
- 数据抓取
数据标注
- 人工标注
- 自动标注
- 标注工具
数据清洗
- 去重
- 格式校验
- 异常检测
数据增强
- 伪造样本
- 数据扩充
- 多模态增强
格式转换
- Alpaca格式
- ShareGPT格式
- 多模态格式
自动化脚本
- 预处理
- 增强
- 校验
数据验证
- 自动化校验
- 抽样检查
数据集管理
- 版本控制
- 备份
统计与可视化
- 长度分布
- 格式分布
- 质量分析
常见问题与最佳实践
- 格式错误
- 缺失值
- 多模态对齐
- 采样策略
- 质量控制
2. 数据格式与分布
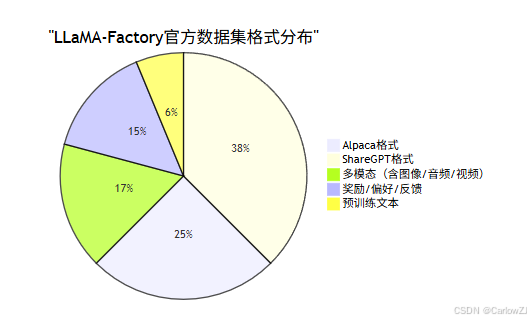
2.1 官方支持数据格式
- Alpaca格式:{“instruction”: “…”, “input”: “…”, “output”: “…”}
- ShareGPT格式:{“conversations”: [{“role”: “user”, “content”: “…”}, …]}
- 多模态格式:支持图片、音频、视频等字段
- 奖励/偏好/反馈格式:用于RLHF、DPO等任务
- 预训练文本格式:纯文本或jsonl
2.2 典型样例
// Alpaca格式
{"instruction": "请写一首诗", "input": "春天", "output": "春天来了,百花齐放..."}
// ShareGPT格式
{"conversations": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好,有什么可以帮您?"}
]}
2.3 数据格式分布饼图
3. 数据准备与处理全流程
3.1 流程总览
3.2 全流程甘特图
4. 数据预处理与增强实践
4.1 典型增强方法
- 文本伪造、同义替换、数据扩增、多模态扩充
- 参考脚本:
scripts/llama_pro.py、scripts/pissa_init.py、scripts/loftq_init.py
4.2 Python代码示例:批量文本增强
import json
import random
from typing import List
# 伪造样本生成函数
def augment_text(text: str) -> str:
"""简单的文本增强:随机插入标点或同义词替换"""
synonyms = {"春天": ["阳春", "春季"], "百花": ["鲜花", "花朵"]}
for word, syns in synonyms.items():
if word in text:
text = text.replace(word, random.choice(syns))
# 随机插入标点
if random.random() > 0.5:
text += random.choice(["!", "。", "~"])
return text
# 批量增强主流程
def batch_augment(input_path: str, output_path: str):
"""批量读取jsonl,增强后输出"""
with open(input_path, 'r', encoding='utf-8') as fin, \
open(output_path, 'w', encoding='utf-8') as fout:
for line in fin:
try:
sample = json.loads(line)
sample['output'] = augment_text(sample['output'])
fout.write(json.dumps(sample, ensure_ascii=False) + '\n')
except Exception as e:
print(f"增强失败: {e}")
# 示例调用
if __name__ == "__main__":
batch_augment('alpaca_en_demo.json', 'alpaca_en_demo_aug.json')
注意: 实际增强可结合NLP工具包(如NLTK、jieba、textaugment等)实现更复杂的操作。
5. 数据验证与质量控制
5.1 自动化校验机制
- 字段完整性、格式一致性、多模态对齐、缺失值检测、异常值检测
- 参考脚本:
src/llamafactory/data/loader.py、src/llamafactory/data/formatter.py
5.2 Python代码示例:字段校验
import json
def validate_sample(sample: dict, required_fields: List[str]) -> bool:
"""校验样本是否包含所有必需字段"""
for field in required_fields:
if field not in sample or sample[field] in [None, ""]:
print(f"缺失字段: {field}")
return False
return True
# 批量校验
def batch_validate(input_path: str, required_fields: List[str]):
with open(input_path, 'r', encoding='utf-8') as fin:
for idx, line in enumerate(fin):
try:
sample = json.loads(line)
if not validate_sample(sample, required_fields):
print(f"第{idx+1}行校验失败")
except Exception as e:
print(f"解析失败: {e}")
# 示例调用
if __name__ == "__main__":
batch_validate('alpaca_en_demo_aug.json', ['instruction', 'input', 'output'])
最佳实践: 校验脚本应集成日志输出、异常捕获,支持多格式、多模态字段。
6. 数据集管理与版本控制
6.1 目录结构与配置
- 推荐结构:
data/任务名/格式/,每个数据集配dataset_info.json说明 - 版本管理:定期备份、增量管理、云同步
6.2 dataset_info.json示例
{
"name": "alpaca_en_demo",
"format": "alpaca",
"fields": ["instruction", "input", "output"],
"num_samples": 1000,
"description": "英文Alpaca格式演示数据集"
}
7. 实战案例与常见问题
7.1 实战案例:自动化高质量数据集打造
- 多源采集 → 人工/自动标注 → 清洗去重 → 增强扩充 → 格式转换 → 自动化校验 → 统计可视化 → 版本管理
7.2 常见问题与解决
- 格式不兼容:严格参考官方字段说明,必要时自定义转换脚本
- 缺失值/异常值:批量校验+日志输出,人工复查
- 多模态对齐:校验图片/音频/视频数量,自动/人工补全
- 采样策略不合理:多轮抽样、统计分析
- 增强失效:脚本单元测试、日志监控
8. 最佳实践与扩展阅读
8.1 最佳实践
- 严格遵循官方格式与字段说明
- 自动化脚本处理,减少人工失误
- 多轮校验与抽样,提升数据质量
- 多模态数据一致性校验
- 版本管理与定期备份
8.2 扩展阅读
9. 参考资料
- LLaMA-Factory官方文档与源码
- HuggingFace Datasets官方文档
- 相关数据增强与多模态处理论文
- 业界开源数据集与工具链
10. 总结
高质量数据集是大模型训练的基石。LLaMA-Factory通过标准化格式、自动化脚本、严格校验与可视化分析,极大提升了数据工程效率与数据质量。建议开发者结合官方工具链与最佳实践,打造高质量、可复现、可扩展的数据集,为大模型微调与创新应用打下坚实基础。
如需进一步细化某一章节、添加案例或有其他定制需求,欢迎随时提出!



















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











