






目录
在前两篇博客中,我们分别介绍了 GraphRAG 的基本概念、索引创建与优化。今天,我们将深入探讨 GraphRAG 的检索过程,了解如何从图数据库中提取相关信息,并生成精准的答案。检索是 GraphRAG 的关键环节,直接影响到最终生成结果的质量。
检索过程详解
GraphRAG 的检索过程主要包括以下几个步骤:
-
查询解析:对用户输入的查询进行解析,提取关键信息。
-
图检索:根据解析后的查询,在图数据库中检索最相关的节点和边。
-
结果排序:对检索到的结果进行排序,确保最相关的信息排在前面。
-
结果融合:将多个相关结果进行融合,生成最终的输入信息。
代码示例:检索过程
Python复制
import graphrag
# 初始化 GraphRAG
graphrag.init()
# 加载索引
index = graphrag.load_index("path/to/your/index")
# 解析查询
query = "这篇文章主要讲述了什么内容?"
parsed_query = graphrag.parse_query(query)
# 图检索
results = index.retrieve(parsed_query, top_k=5)
# 结果排序
sorted_results = graphrag.sort_results(results)
# 结果融合
fused_results = graphrag.fuse_results(sorted_results)
# 打印检索结果
print("检索到的相关信息:")
for result in fused_results:
print(result)应用场景
检索过程在多个实际应用场景中都非常重要,以下是一些典型的应用场景:
-
智能问答系统:通过检索相关知识,生成准确的回答。
-
文本生成:结合检索到的信息,生成高质量的文本内容。
-
知识管理:帮助用户快速找到所需的知识点,提高知识管理效率。
注意事项
-
查询质量:确保用户输入的查询清晰且具体,避免模糊或不相关的查询。
-
检索参数:调整检索参数(如 top_k、相似度阈值等)以提高检索精度。
-
结果处理:对检索到的结果进行合理的排序和融合,确保最终输入信息的质量。
通过优化检索过程,我们可以显著提升 GraphRAG 的性能,使其在各种应用场景中发挥更大的作用。在实际应用中,可以根据具体需求调整检索参数和处理逻辑,以实现最佳效果。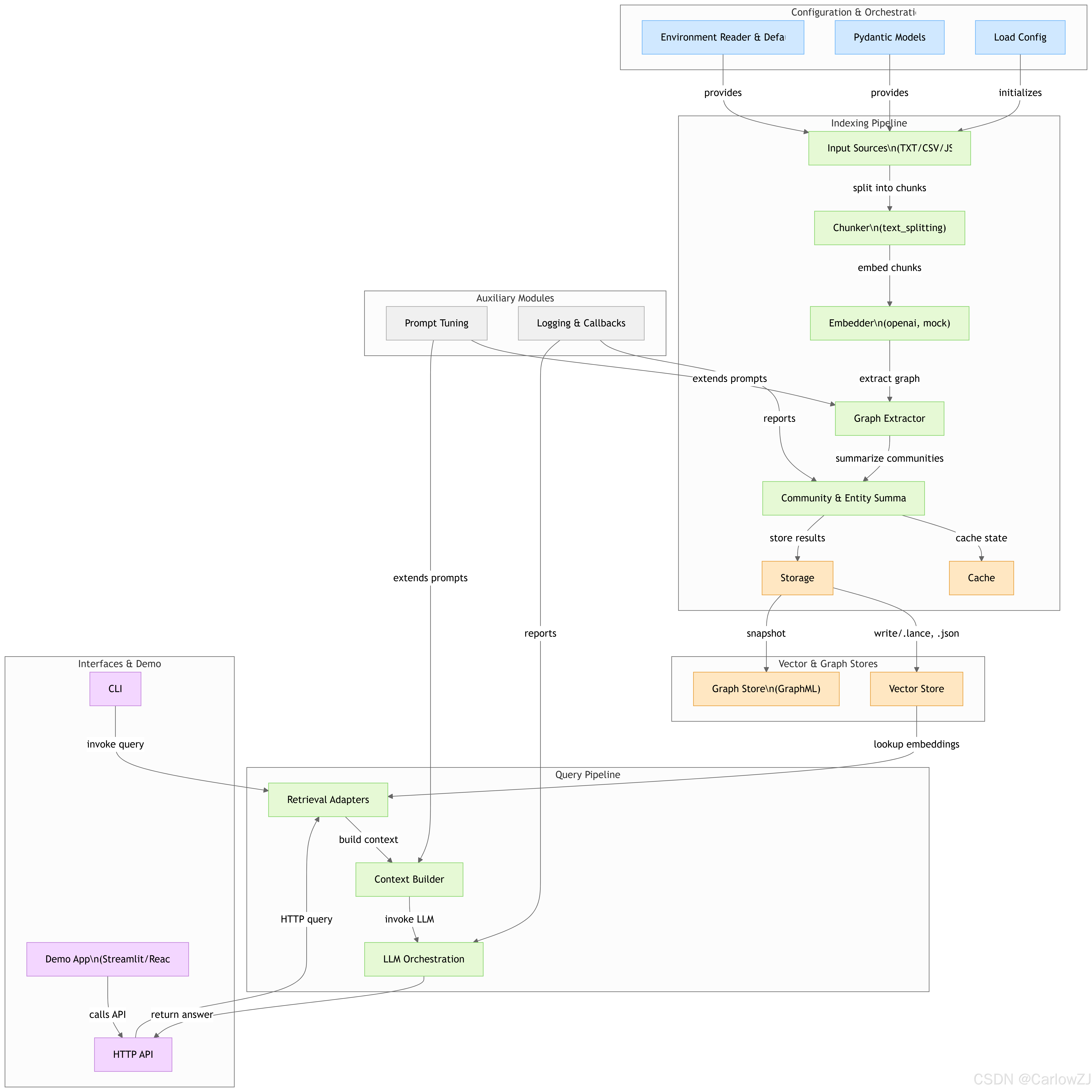


















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











