






GraphRAG 本地部署、调试、到图形化展示过程记录
GraphRAG 是一种结构化的、分层的检索增强生成(RAG)方法,而不是使用纯文本片段的语义搜索方法。GraphRAG 过程包括从原始文本中提取出知识图谱,构建社区层级(这种结构通常用来描述个体、群体及它们之间的关系,帮助理解信息如何在社区内部传播、知识如何共享以及权力和影响力如何分布),为这些社区层级生成摘要,然后在执行基于 RAG 的任务时利用这些结构。

一、本地部署
部署相对简单,看看网页即可
参考网页 https://www.graphrag.club/
大模型我用的是本地的ollama
1.查看python版本
3.10到3.12 都行
#
python --version
Python 3.10.12
2.安装 GraphRAG
pip install graphrag
3.准备一个示例数据集
创建数据集文件夹
mkdir -p ./ragtest/input
准备一个丑小鸭的故事
sudo vi ./ragtest/input/chouxiaoya.txt
4.设置工作区变量
python -m graphrag.index --init --root ./ragtest
5.修改配置文件
.env
GRAPHRAG_API_KEY=ollama
GRAPHRAG_CLAIM_EXTRACTION_ENABLED=True
settings.yaml
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ollama
type: openai_chat # or azure_openai_chat
model: qwen2.5:7b
model_supports_json: true # recommended if this is available for your model.
max_tokens: 10000
request_timeout: 210.0
api_base: http://localhost:11434/v1/
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# temperature: 0 # temperature for sampling
# top_p: 1 # top-p sampling
# n: 1 # Number of completions to generate
parallelization:
stagger: 0.3
# num_threads: 50 # the number of threads to use for parallel processing
async_mode: threaded # or asyncio
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
# target: required # or all
# batch_size: 16 # the number of documents to send in a single request
# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request
llm:
api_key: ollama
type: openai_embedding # or azure_openai_embedding
model: mxbai-embed-large:latest
api_base: http://localhost:11434/v1/
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
chunks:
size: 1200
overlap: 100
group_by_columns: [id] # by default, we don't allow chunks to cross documents
input:
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.txt$"
cache:
type: file # or blob
base_dir: "cache"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
storage:
type: file # or blob
base_dir: "output/${timestamp}/artifacts"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
reporting:
type: file # or console, blob
base_dir: "output/${timestamp}/reports"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
entity_extraction:
## strategy: fully override the entity extraction strategy.
## type: one of graph_intelligence, graph_intelligence_json and nltk
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/entity_extraction.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 1
summarize_descriptions:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
claim_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
# enabled: true
prompt: "prompts/claim_extraction.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 1
community_reports:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/community_report.txt"
max_length: 2000
max_input_length: 8000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodes
# num_walks: 10
# walk_length: 40
# window_size: 2
# iterations: 3
# random_seed: 597832
umap:
enabled: false # if true, will generate UMAP embeddings for nodes
snapshots:
graphml: true
raw_entities: false
top_level_nodes: false
local_search:
# text_unit_prop: 0.5
# community_prop: 0.1
# conversation_history_max_turns: 5
# top_k_mapped_entities: 10
# top_k_relationships: 10
# llm_temperature: 0 # temperature for sampling
# llm_top_p: 1 # top-p sampling
# llm_n: 1 # Number of completions to generate
# max_tokens: 12000
global_search:
# llm_temperature: 0 # temperature for sampling
# llm_top_p: 1 # top-p sampling
# llm_n: 1 # Number of completions to generate
# max_tokens: 12000
# data_max_tokens: 12000
# map_max_tokens: 1000
# reduce_max_tokens: 2000
# concurrency: 32
6.运行
python -m graphrag.index --root ./ragtest


二、调试
头疼的问题:Columns must be same length as key
1.查看日志
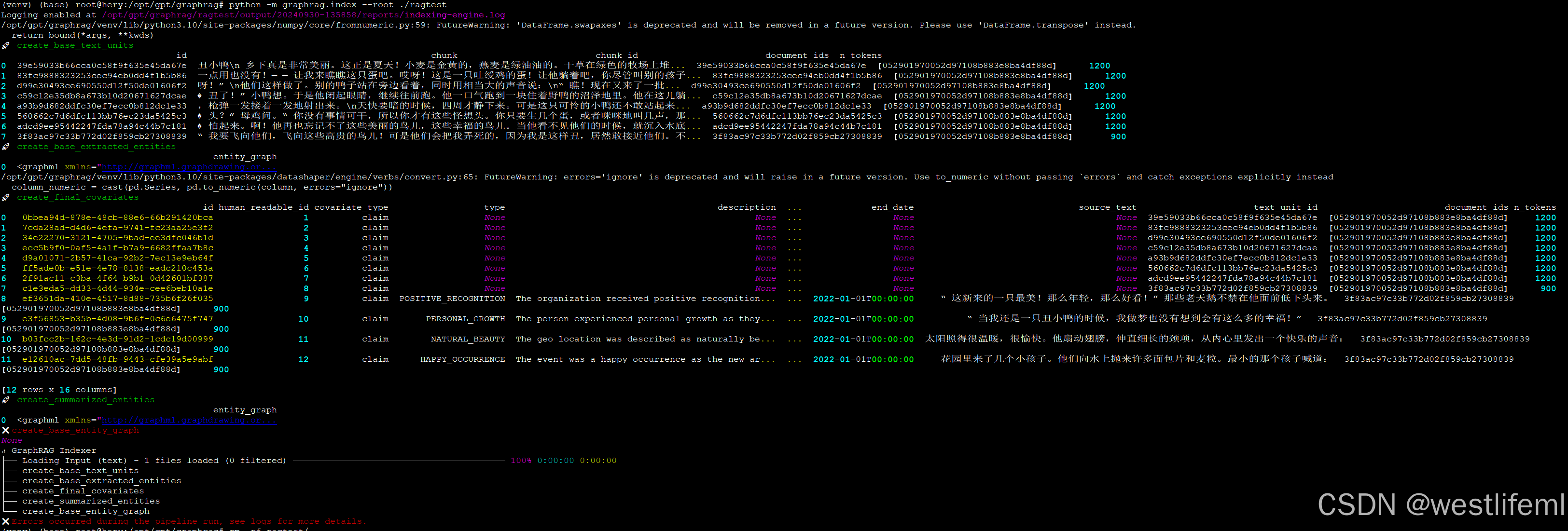
根据图片中信息 Logging enabled at /opt/gpt/graphrag/ragtest/output/20240930-135858/reports/indexing-engine.log
tail -333f /opt/gpt/graphrag/ragtest/output/20240930-135858/reports/indexing-engine.log
2.查看到报错信息
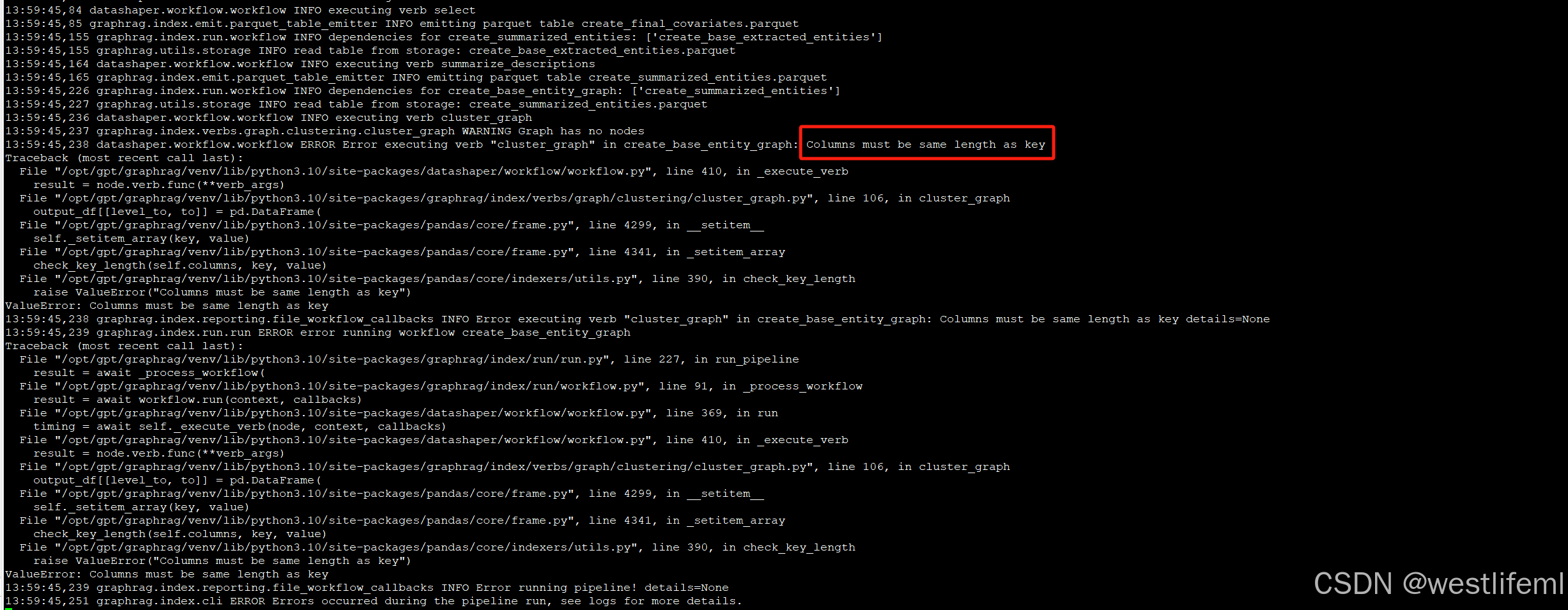
3.处理方法
墙裂推荐解决方案:必坑指南 点击打开 仔细看,用心看
总结一下,就是把 ./ragtest/cache/entity_extraction 路径下的chat_*全都删除
sudo rm -rf ./ragtest/cache/entity_extraction/chat_*
再次运行
python -m graphrag.index --root ./ragtest
完美!!!
三、图形化展示
参考视频 图形化方案 需要一个梯子
没有梯子的先下软件吧 gephi
好看无极限,各位自己慢慢调吧。
简简单单的一张图
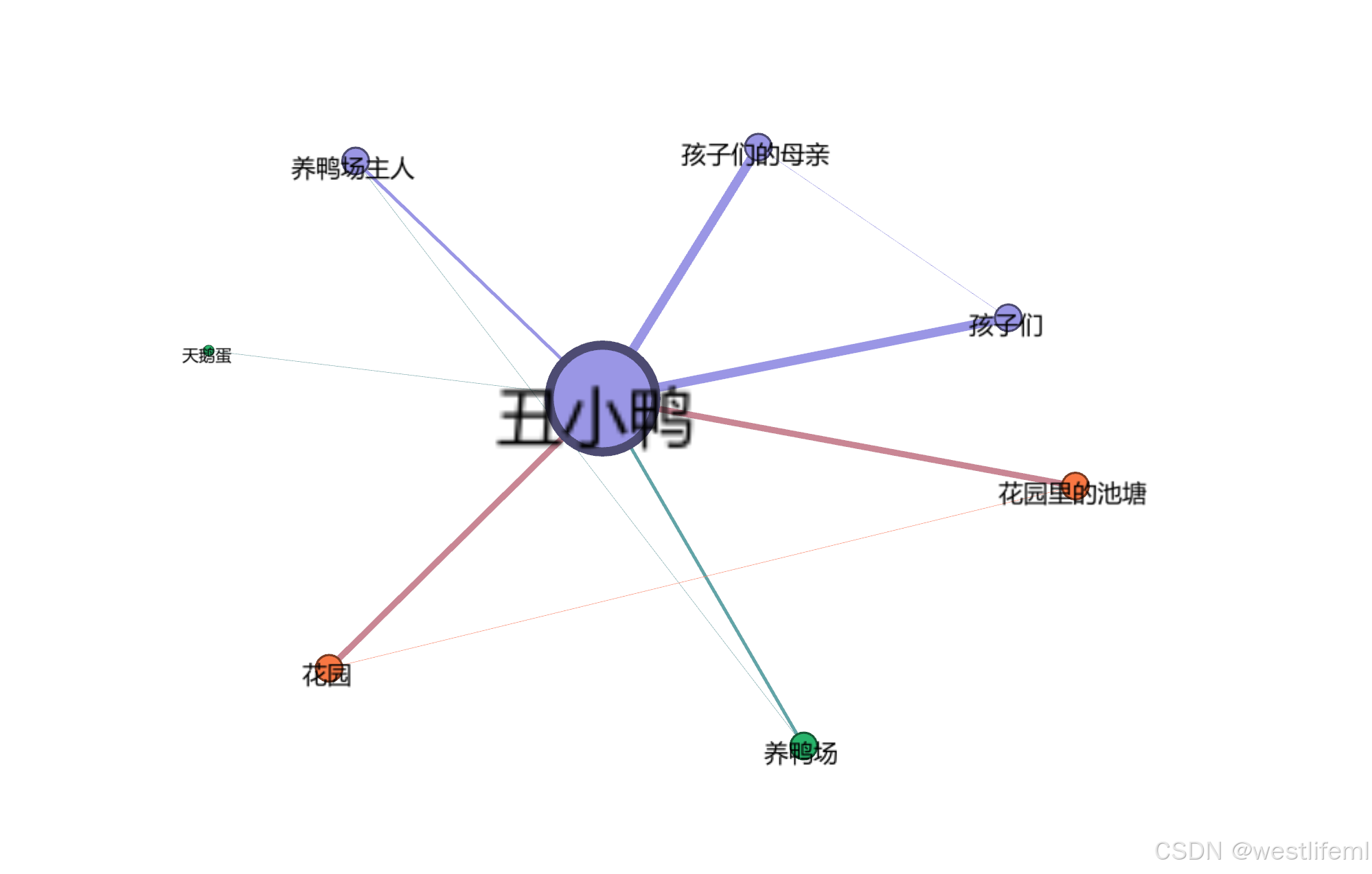
收工!!!


















 4392
4392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









