







 本文深入解析了DQN算法,一种将深度学习与强化学习相结合的方法。重点介绍了如何通过经验池和目标网络解决传统方法遇到的问题,同时概述了DQN的工作流程和优缺点。
本文深入解析了DQN算法,一种将深度学习与强化学习相结合的方法。重点介绍了如何通过经验池和目标网络解决传统方法遇到的问题,同时概述了DQN的工作流程和优缺点。
目录
- 概念
- 深度学习与强化学习结合的问题
- DQN解决结合出现问题的办法
- DQN算法流程
- 总结
一、概念
原因:在普通的Q-Learning中,当状态和动作空间是离散且维数不高的时候可以使用Q-Table来存储每个状态动作对应的Q值,而当状态和动作空间是高维连续时,使用Q-Table不现实。一是因为当问题复杂后状态太多,所需内存太大;二是在这么大的表格中查询对应的状态也是一件很耗时的事情。
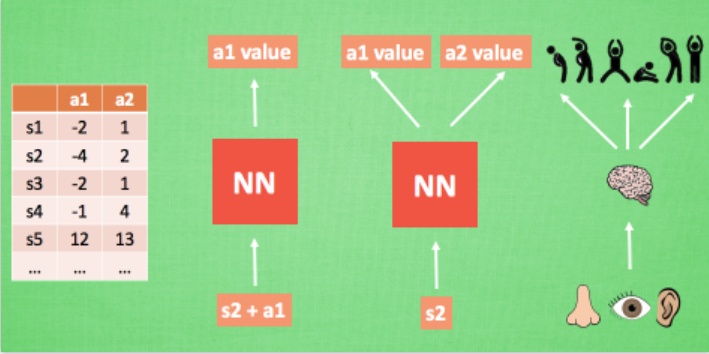
通常的做法是把Q-Table的更新问题变成一个函数拟合问题,相近的状态得到相近的输出动作。如: Q(s,a;θ)≈Q′(s,a),通过更新参数θ使Q函数逼近最优Q值,而深度神经网络可以自动提取复杂特征,因此,面对高维且连续的状态使用深度神经网络再合适不过。我们可以想象,神经网络接受外部的信息,相当于眼睛鼻子耳朵收集信息,然后通过大脑加工输出每种动作的值,最后通过强化学习的方式选择动作。
DRL是将深度学习(DL)和强化学习(RL)结合,直接从高维原始数据学习控制策略。而DQN是DRL的其中一种算法,它将卷积神经网络(CNN)和Q-Learning结合起来,CNN的输入是原始图像数据(作为状态state),输出则是每个动作Action对应的价值评估Value Function(Q值)。(或者输入状态和动作,通过神经网络输出对应的Q值)
二、深度学习与强化学习结合的问题
- 深度学习需要大量带标签的样本进行监督学习;强化学习只有reward
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









