







前言
- 两年前接触强化学习是通过莫烦的课程,那时候对强化学习整体有一个基础的认识,最近听了David Silver的课程后又建立起了完整的强化学习体系,故连载David Silver系列的笔记.本讲会对强化学习整体做一个介绍,也会介绍强化学习中常用的概念,帮助读者理解,看完本文只需要建立起一个概念体系就行,不需要深究细节,细节在后面会展开说明.
目录
- 关于强化学习
- 强化学习中的要点
- 智能体内部
- 强化学习中的问题
- 参考
关于强化学习
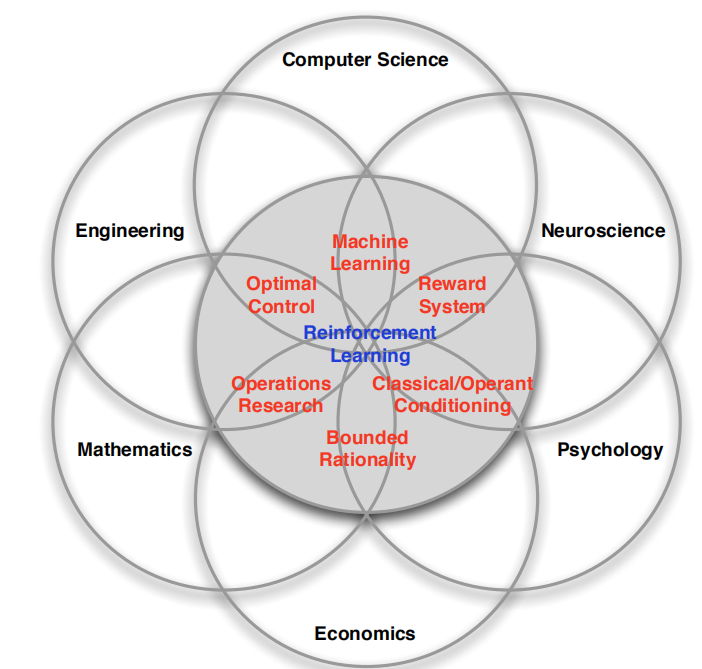
- 强化学习在各种领域都有着它的应用,比如:(1)在计算机科学领域,强化学习是一种机器学习的算法(2)在数学领域,强化学习体现在运筹学的研究(3)在工程师领域,强化学习则体现在最优控制理论 等等.
- 可以说机器学习有三个分支,分别是监督学习(给定标签学习),非监督学习(挖掘没标签样本之间的联系)和本文将介绍的强化学习.
强化学习的特点
- 不同于监督学习有标签告诉算法什么样的输入对应着什么样的输出,强化学习没有标签,只有一个做出一系列行为后最终反馈回来的奖励信号,通过奖励信号来调整算法.
- 强化学习的奖励信号反馈是延迟的,不是实时的,
- 强化学习中时间序列是一个重要的因素(作为序列决策问题,属于非独立同分布数据)
- 每一个决策的行为都会影响到下一次决策的输入.
强化学习应用的部分案例
游戏
阿法狗

强化学习中的要点
奖励Reward
- 奖励 R t R_t Rt是一种反馈信号,它是一个标量,它反映的就是个体在 t t t时刻做的怎么样,每个个体的目标就是最大化它积累的奖励(积累的奖励越多自然表示他做的更好).
- 强化学习就是基于这样的奖励假设:所有的目标都可以被描述成最大化累积奖励的期望。
奖励的例子
- 对于直升飞机飞行特技动作,在它按照规定好的轨迹飞行的时候给予它正奖励反馈,在它碰撞的时候给予它负奖励反馈.
- 对于下围棋来说,它赢了就给予它正奖励反馈,它输了就给予它负奖励反馈
序列决策Sequential Decision Making
- 目标:选择一序列的行为来最大化未来的奖励(比如为了完成飞行特技动作,直升飞机需要先往上再往下等等)
- 这些行为可能是一个长序列(完成一个特技动作需要一连串的行为)
- 奖励信号可能是延迟的(可能最后才知道这个特技动作做好了没)
- 有时候我们需要牺牲短期奖励来得到长期的奖励(一开始飞机不是直接飞,而是先加油,虽然一开始让大家等他消耗了大家的耐心,但最终完美的特技动作赢得了人们的鼓掌)
智能体和环境 Agent and Environment
- 首先,我们要区分这两者,智能体就是下图的大脑,是我们可以控制的,环境则是下图中的地球,我们控制不了,只能看
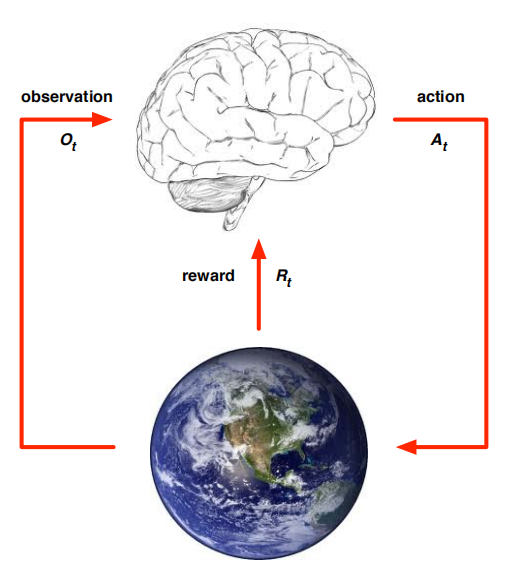
- 我们分别从智能体和环境两部分来阐述:
- 对于智能体本身,在每一个 t t t时刻,将分别做三件事:
- 接受在环境得到的一个观测observation O t O_t Ot,对机器人找宝藏这个实际例子来说则是机器人的摄像头看到的场景.
- 执行动作action A t A_t At,即机器人根据摄像头看到的路选择往左走或者往右走去寻找宝藏.
- 从环境接受一个奖励的信号 R t + 1 R_{t+1} Rt+1,环境会通过奖励信号告诉机器人这步走的好不好.(这里没有按照课件中的 R t R_t Rt,读者看到后面几讲就明白了)
- 对于环境本身,在每一个 t t t时刻,将分别做三件事:
- 接受智能体的动作 A t A_t At
- 更新环境的信息,让智能体得到下一个观察 O t + 1 O_{t+1} Ot+1,比如机器人向右走了一步后让机器人看到向右一步后的场景
- 给予智能体奖励信号 R t + 1 R_{t+1} Rt+1
历史和状态 History and State
- 历史history是观测observations,动作actions,奖励rewards的序列 H t = O 1 , R 1 , A 1 , ⋯ , A t − 1 , O t , R t H_t = O_1,R_1,A_1,\cdots,A_{t-1},O_t,R_t Ht=O1,R1,A1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









