




本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩说在前面
在45岁老架构师 尼恩的读者交流群(50+)中,通过 Java+AI双驱架构 帮助很多小伙伴拿到了一线企业如 字节、得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团、蚂蚁、得物的面试资格,遇到很多很重要的面试题:
说说 ClickHouse Group By 执行流程 ?
ClickHouse 支持 高吞吐写入与低延迟查询,可支撑亿级乃至十亿级数据的实时分析,原因是什么?
为啥mysql 不行?
最近有小伙伴在 面试希音,遇到 到了这个的面试题。 小伙伴没有 回答好,到手到 大厂 offer就 这样飞走了。 非常可惜。
小伙伴面试完了之后,来求助尼恩。
那么,遇到 这个问题,该如何才能回答得很漂亮,才能 让面试官刮目相看、口水直流。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
一、ClickHouse 高性能分析型数据库核心解析
1、ClickHouse 概述
ClickHouse 核心优势是高吞吐写入与低延迟查询,可支撑亿级乃至十亿级数据的实时分析需求。
ClickHouse 与其他数据工具的定位差异,可通过以下图 区分:

2、ClickHouse 整体架构
ClickHouse 的架构设计是其性能的核心基础,核心差异在于“存储与计算的关系”和“MPP 并行能力”。
ClickHouse 是面向联机分析处理(OLAP)场景的分布式列式数据库,其核心架构包含两大模块:
- 存储层:负责数据持久化与压缩优化
- 计算层:处理查询执行与分布式计算
ClickHouse 采用MPP(大规模并行处理)架构,各节点对等协作,通过数据分片与副本机制实现水平扩展。
MPP 与传统计算引擎不同,ClickHouse采用存储计算一体化设计,使存储层能针对查询需求进行深度优化。
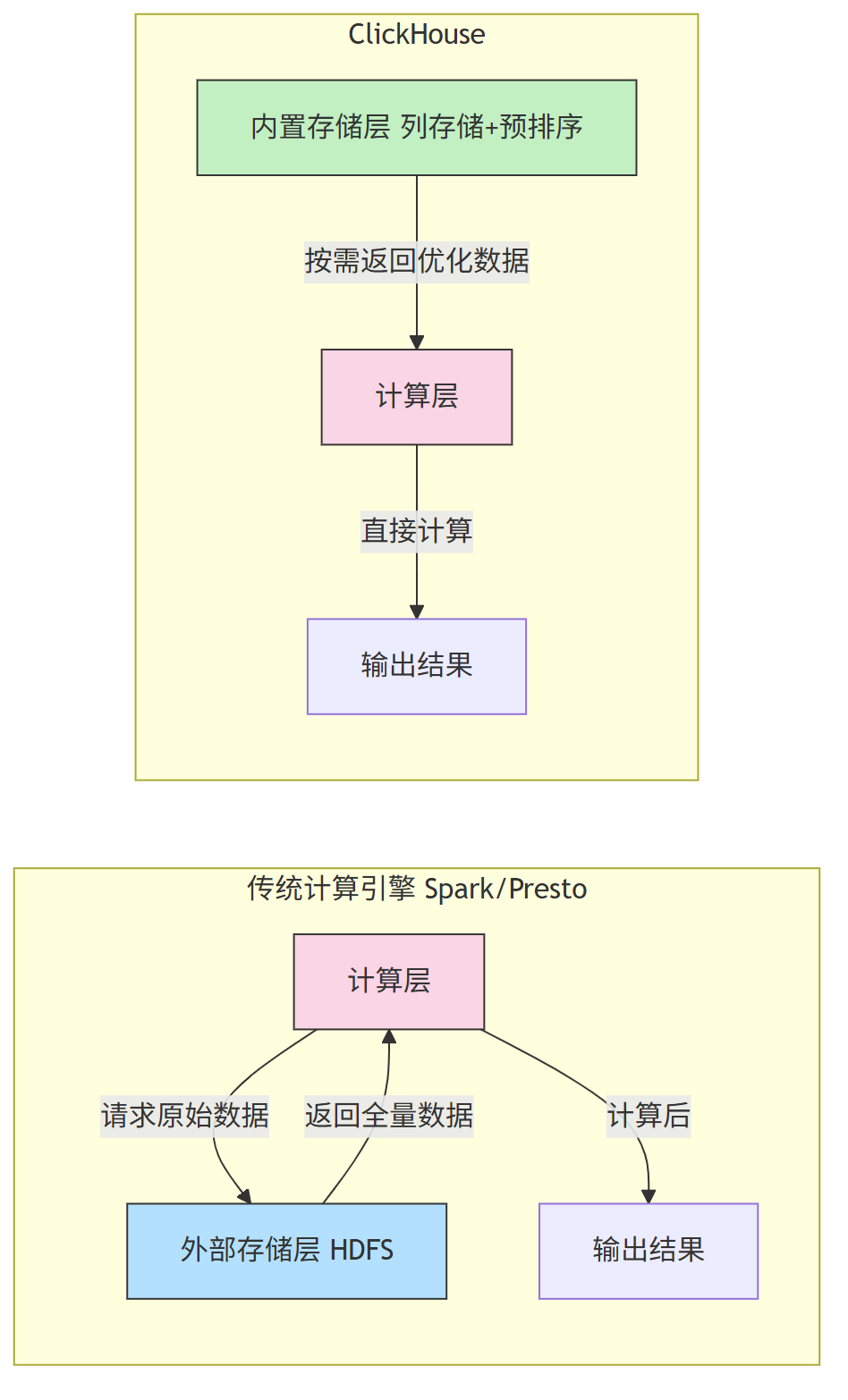
2.1 架构核心:存储服务于计算
传统大数据引擎(如 Spark)是 “计算 存储 分离 ”模式——计算层需从外部存储(HDFS/S3)读取原始数据,再进行计算;
而 ClickHouse 是 “计算 存储 一体化 ”模式 —— 自带存储层,可在存储阶段为计算做优化(如列存储、预排序),即“存储服务于计算”,大幅减少计算时的 I/O 开销。
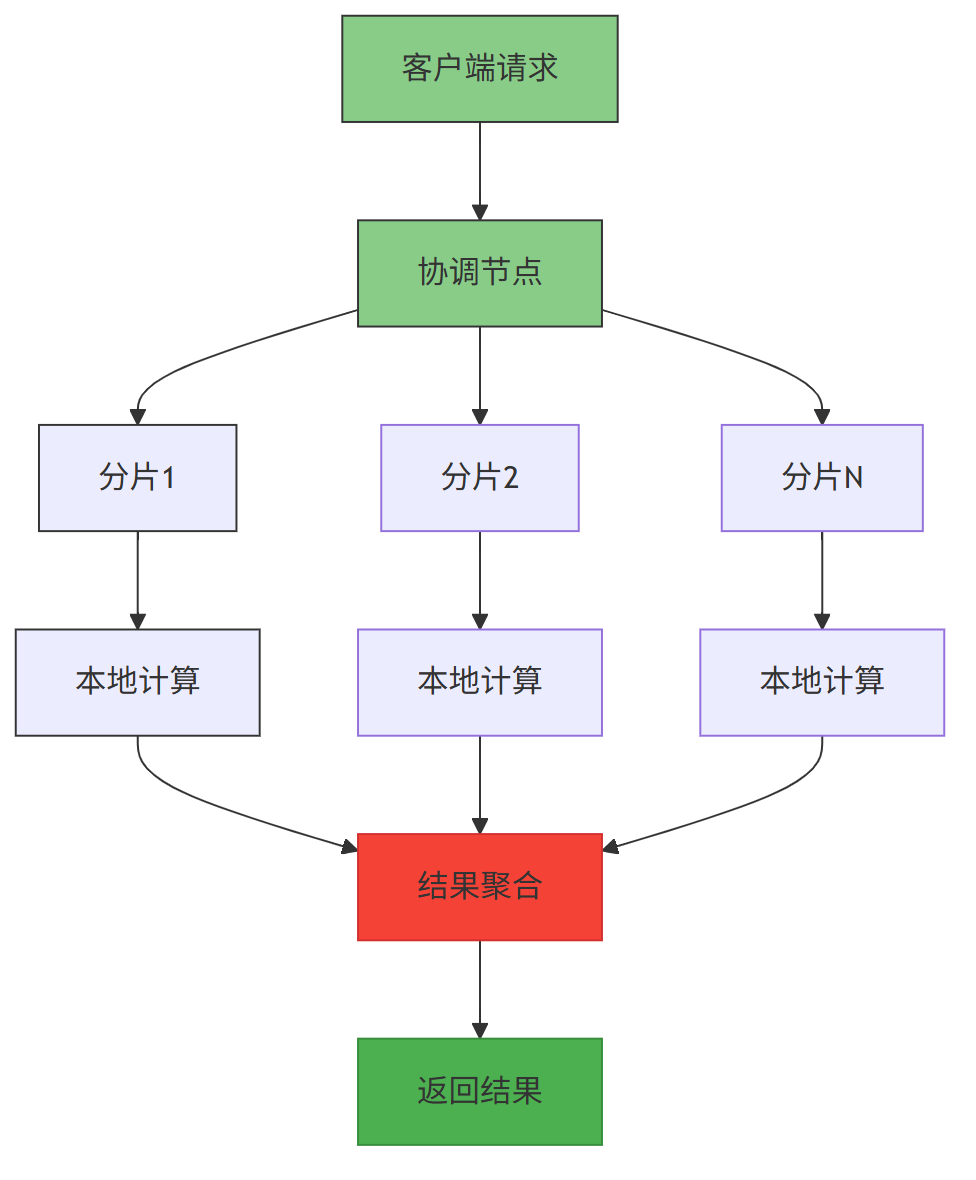
2.2 MPP 架构:并行计算提效
ClickHouse 采用大规模并行处理(MPP) 架构,集群中所有节点对等,无主从之分。
MPP 架构中,查询 任务会被拆分为多个子任务,并行分发到不同节点执行,最后汇总结果,充分利用多核 CPU 与多节点资源。
3、 ClickHouse 核心性能优化特性
ClickHouse 的极速查询能力,源于三大核心优化:
- 列式存储
- 向量化执行
- 数据预排序。
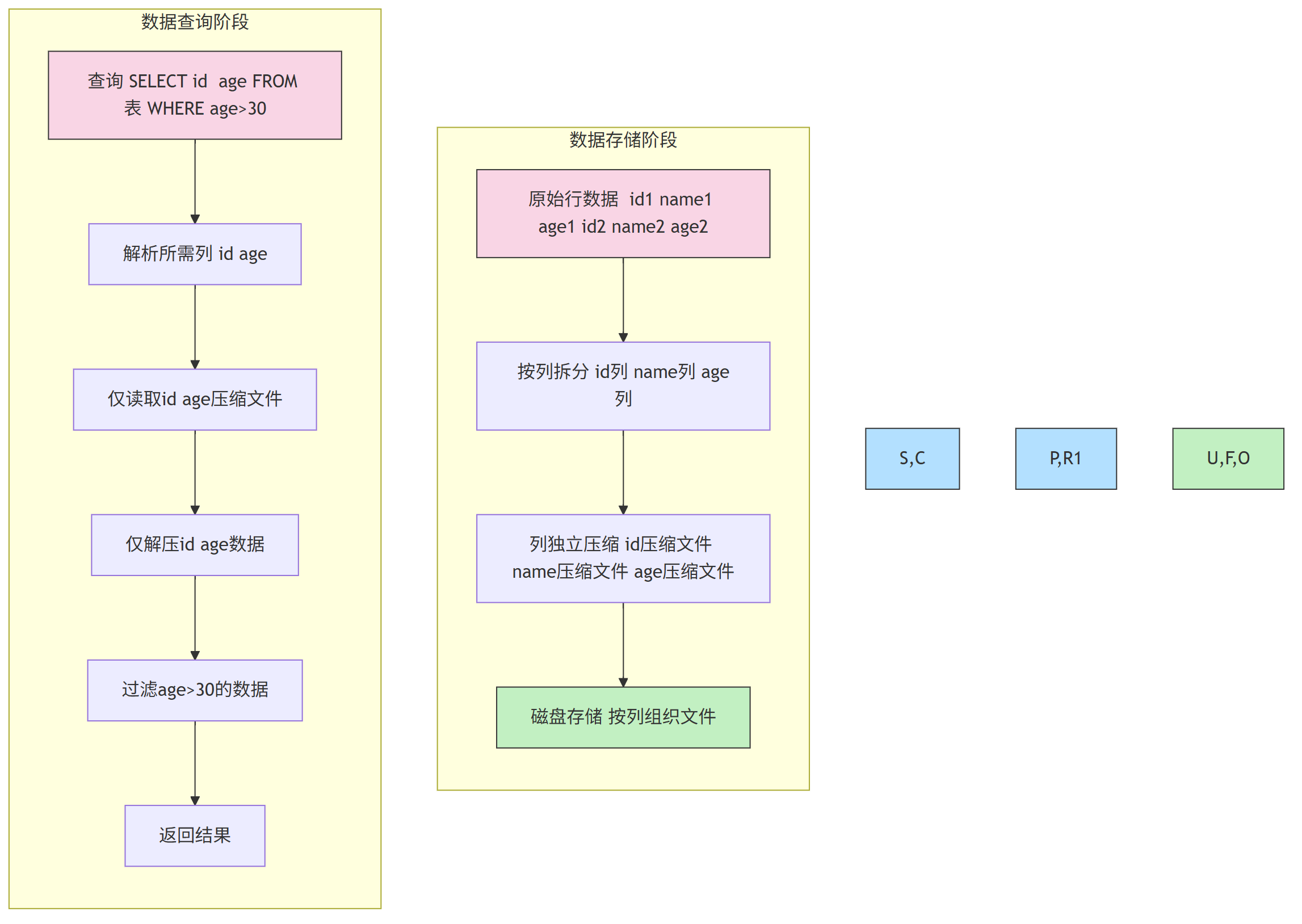
3.1 列式存储:减少无效数据读取
传统行存储按“行”存储数据(一行所有列存在一个文件),查询时需读取整行数据;
而列式存储按“列”拆分存储(每列单独一个文件),查询时仅读取所需列,同时同列数据特征相似,压缩率更高(生产中常达 8:1)。

3.2 向量化执行:提升 CPU 效率
传统计算引擎“单条数据处理”(一次处理 1 条数据,CPU 缓存命中率低);
ClickHouse 采用“批量处理”,将数据分成固定大小的块(如 1024 条),借助 CPU 的 SIMD(单指令多数据) 指令集,1 条指令处理多个数据,大幅提升 CPU 利用率。
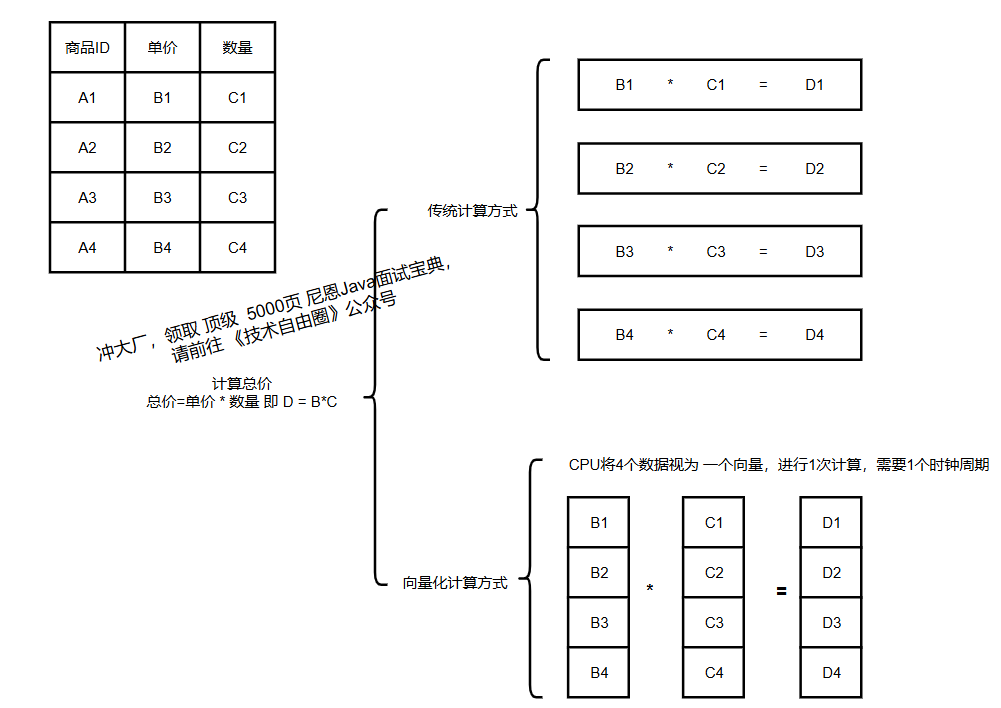
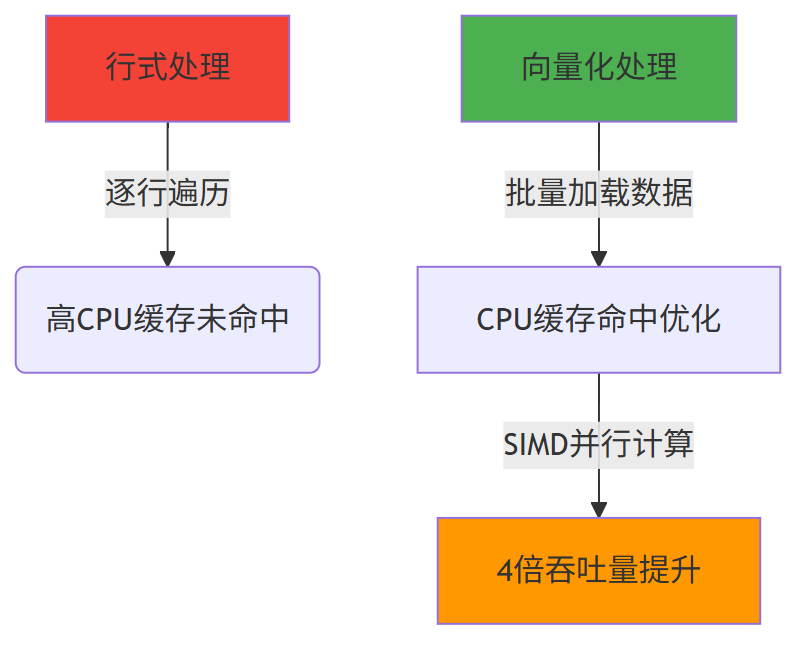
3.3 数据预排序:加速范围查询
ClickHouse 基于类 LSM 算法,数据写入时先在内存排序,刷盘后通过后台 Compaction 合并为有序大分区,确保磁盘数据始终有序。
查询时可利用有序性快速定位范围(如“时间>2024-01-01”),减少扫描的数据量。
MergeTree (本地表) 建表语句的 示例
-- 示例:创建 MergeTree 表(核心表引擎,支持预排序)
CREATE TABLE IF NOT EXISTS user_behavior (
user_id UInt64, -- 用户ID(无符号整数)
behavior_type String, -- 行为类型(点击/购买)
create_time DateTime, -- 行为时间
product_id UInt64 -- 商品ID
) ENGINE = MergeTree() -- MergeTree:支持预排序、Compaction
ORDER BY (user_id, create_time) -- 排序键:决定数据存储顺序(核心配置)
PARTITION BY toYYYYMM(create_time) -- 按年月分区(优化时间范围查询)
PRIMARY KEY user_id; -- 主键:需为排序键前缀(此处user_id是排序键首字段)
-- 关键解释:
-- 1. ORDER BY 是预排序的核心,查询常按 user_id+时间范围过滤,有序数据可快速定位
-- 2. PARTITION BY 按时间分区,查询时先定位分区,再扫描分区内数据
4、 ClickHouse 表引擎
表引擎决定了数据的存储方式、查询支持能力、并发控制等
4.1 ClickHouse 提供多种引擎
ClickHouse 提供多种引擎,适配不同场景,常用引擎如下:
| 表引擎类型 | 代表引擎 | 核心用途 | 适用场景 |
|---|---|---|---|
| 核心存储引擎 | MergeTree | 海量结构化数据存储(支持预排序、分区) | 业务核心表(如用户行为、订单表) |
| 分布式引擎 | Distributed | 管理分片集群(不存储数据,仅路由请求) | 分布式查询入口(对外提供统一表名) |
| 内存引擎 | Memory | 内存存储(数据重启丢失) | 临时计算、小表缓存 |
| 日志引擎 | Log | 轻量存储(无索引) | 日志数据(如审计日志、访问日志) |
Distributed 关键解释:
- Distributed 表本身不存数据,仅作为“路由入口”
- 写入时:按分片键计算分片ID,路由到对应节点的本地表
- 查询时:向所有分片发送子查询,汇总结果后返回
Distributed 表建表示例(分片管理)
-- 前提:已在 config.xml 配置集群 my_cluster(2个分片,每个分片1个副本)
CREATE TABLE IF NOT EXISTS user_behavior_dist (
user_id UInt64,
behavior_type String,
create_time DateTime,
product_id UInt64
) ENGINE = Distributed(
my_cluster, -- 集群名称(配置文件中定义)
default, -- 数据库名(与本地表一致)
user_behavior, -- 本地表名(每个分片节点上的表)
user_id -- 分片键(按user_id哈希分片,保证数据均匀)
);
4.2 Distributed 与 MergeTree 引擎在 ClickHouse 中的协作关系
在 ClickHouse 的高性能列式数据库架构中,Distributed 引擎和 MergeTree 系列引擎有着密切的协同关系,共同构建了 ClickHouse 的分布式处理能力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2099
2099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









