 100亿分库分表设计的16字真经
100亿分库分表设计的16字真经





本文的 原始地址 ,传送门
说在前面
在45岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题::
- 尼恩老师,面试官问我有一个订单表。有商品类别,订单id用户id,运营id,数据量上百亿这种情况,要有能对商品类别进行查询,运营查询他负责的跟单信息,按照订单号查询用户查询对应订单。要怎么去设计数据库的存储结构?
- 100亿数据海量数据,如何进行存储架构?
最近有小伙伴在面试 携程,又遇到了相关的面试题。小伙伴懵了,因为没有遇到过,所以支支吾吾的说了几句,面试官不满意,面试挂了。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V171版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,回复:领电子书
100亿数据海量数据 架构的16字设计原则 :
100亿数据海量数据 架构,尼恩给大家梳理一个 16字设计原则 :
-
冷热分离:以访问频率驱动存储成本优化
-
强弱解耦:以业务重要性划分一致性等级
-
冗余双写:以查询需求驱动数据冗余
-
延迟分级:以响应速度定义技术选型
面试过程中,可以 结合电商、金融等场景说明分层设计的具体落地方法。
这就是一个分库分表的 120分殿堂答案 (塔尖级):

第一个维度:冷热分离 理论架构
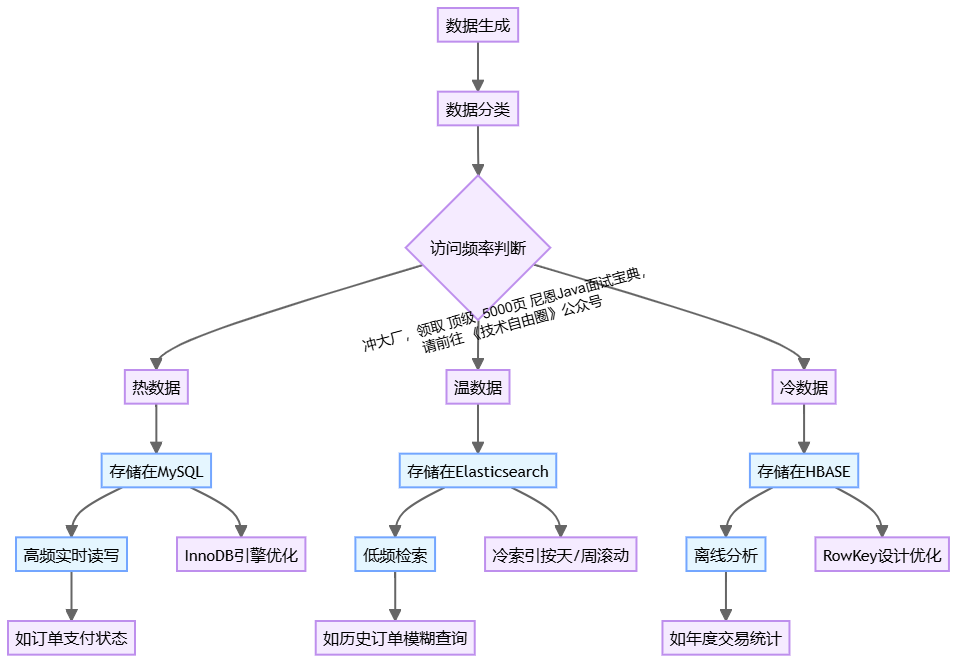
热-》温-》冷 : 冷热数据分离存储
根据访问频率定义冷热边界(如3个月未访问自动归档)
冷热数据的概念:热数据是频繁访问且时效性强的数据,温数据则是访问频率相对低数据,冷数据则是访问频率低且可能过期的数据。
热-》温-》冷 分离 基本知识要点:
- 冷热数据分离的概念及其在数据存储中的重要性。
- 热数据的特点:高访问频率、低延迟要求,适合存储在MySQL等关系型数据库中。
- 冷数据A的特点:中等访问频率,适合存储在Elasticsearch(ES)中,支持秒级检索。
- 冷数据B的特点:低访问频率,适合存储在HBASE等大数据分析平台中,支持批量分析。
数据生命周期管理:
-
热数据(MySQL):高频实时读写(如订单支付状态)
-
温数据 (ES):低频检索(如历史订单模糊查询)
-
冷数据 (HBASE):离线分析(如年度交易统计)
存储选型逻辑:
不同存储介质的特点:如MySQL适合实时查询,ES适合秒级检索,HBASE适合批量分析。
- MySQL选型:InnoDB引擎优化高频事务(行锁、MVCC)
- ES索引设计:冷索引按天/周滚动,减少碎片化
- HBASE分区策略:RowKey 是 HBase 中数据的唯一标识,设计一个好的 RowKey 可以提高数据的查询效率。
数据同步方案:
- 热转冷:基于定时任务、或者 主从同步(如 Canal监听Binlog触发 同步)
架构设计的要点:
-
实际业务中,需要 根据数据访问频率和业务需求合理划分冷热数据。
-
冷热数据存储方案 的设计与实现,需要 确保数据的高效访问与存储成本优化。
-
各存储介质在数据迁移、查询性能等方面的关键技术点。
第一个维度:冷热分离 架构设计实操
百亿级订单表冷热分离存储设计方案(基于访问频率分层)
1. 冷热分层定义与边界划分
- 热数据(实时访问层)
存储近3个月订单(日均访问量千万级),支持实时读写,响应时间≤50ms。
保留字段:订单ID、用户ID、运营ID、商品类别、支付状态、金额、时间戳等核心字段。
- 温数据(近线检索层):
存储3~12个月订单(月均访问量百万级),支持秒级检索,响应时间≤500ms。
保留字段:订单ID、用户ID、运营ID、商品类别、评价内容、物流信息等分析字段。
- 冷数据(离线分析层):
存储1年以上历史订单(年访问量十万级),支持分钟级批量查询,响应时间≤10s。
保留字段:全量数据(含业务扩展字段),用于审计、年度报表等场景。
冷热迁移规则:
- 每日凌晨通过定时任务扫描热数据表,将超3个月数据迁移至ES(标记is_hot=0)
- 每月初将ES中超9个月数据迁移至HBase(标记is_warm=0)
也可以通过 canal+ binlog ,异步 把数据 写入 近线检索层 + 离线分析层
2. 存储选型与容量规划
| 层级 | 存储引擎 | 容量预估 | 部署模 |
|---|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8436
8436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









