



基于分布式深度学习的移动边缘计算网络卸载:突破网络瓶颈,提升计算效率
完整代码见文末
在5G、物联网以及智能设备飞速发展的背景下,移动边缘计算(MEC)作为一种新兴的计算架构,正迎来前所未有的机遇。然而,随着设备数量的增加和计算需求的不断提升,如何高效地利用边缘计算资源,实现智能设备的计算任务卸载,成为了亟待解决的难题。传统的边缘计算面临着计算资源分配不均、延迟过高、带宽压力大等痛点,迫切需要一种更智能的卸载方法。
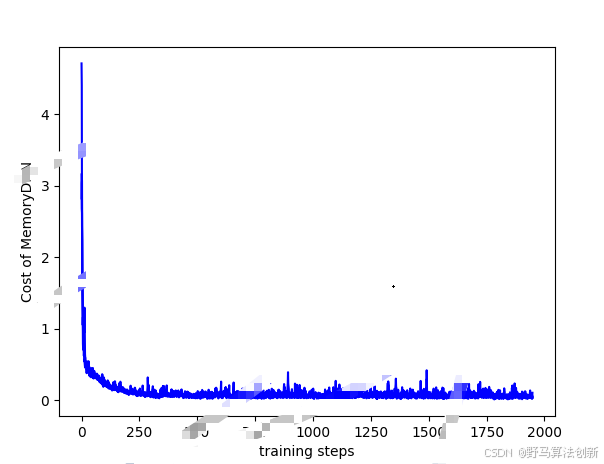
痛点:边缘计算资源紧张,网络负担过重
传统的移动边缘计算网络中,设备通常根据预设的规则将任务卸载到边缘服务器上,但这种方法的局限性在于它不能根据实际情况灵活地做出卸载决策。具体表现为:
- 计算资源分配不均:不同任务对计算资源的需求差异较大,简单的卸载方式往往不能做到精细化的资源分配,导致边缘服务器资源浪费或负载过重。
- 高延迟问题:在网络不稳定或者拥塞的情况下,传统的卸载方式可能导致任务无法及时完成,增加响应延迟,影响用户体验。
- 带宽限制:随着设备数目的增多和任务量的增加,网络带宽成为瓶颈,过多的任务上传会导致网络拥塞,进一步影响卸载效果。
解决方案:分布式深度学习赋能智能卸载
为了解决上述问题,基于分布式深度学习的移动边缘计算卸载技术应运而生。通过将深度学习引入到卸载决策中,能够根据任务的特性、网络状况以及边缘计算资源的实时状态,智能化地调整任务的卸载策略,从而大幅提升计算效率、减少延迟,充分利用边缘计算资源。
技术优势:
- 动态卸载决策:分布式深度学习模型能够根据实时的网络状态、设备负载和任务需求,灵活地做出卸载决策,确保计算任务能够在最合适的位置进行处理。
- 分布式计算架构:通过分布式深度学习,多个边缘节点能够协同工作,共享计算负载,避免了单个节点过载的情况,提高了整体系统的计算能力。
- 自适应学习能力:深度学习模型能够自我学习和优化,随着网络环境和任务的变化,模型能够动态调整卸载策略,确保任务处理效率最大化。
- 带宽优化:通过智能化的卸载决策,能够减少不必要的数据传输,减少网络带宽的占用,避免了过度依赖网络带宽导致的瓶颈问题。
完整的分布式深度学习卸载框架
在基于分布式深度学习的移动边缘计算卸载系统中,整个框架包括多个模块,分别承担不同的功能:
- 数据采集模块:通过传感器和网络模块实时采集设备的状态、任务信息以及网络带宽等数据,为卸载决策提供依据。
- 深度学习模型模块:基于收集到的数据,利用分布式深度学习算法训练出一个智能卸载决策模型。该模型能够根据不同的场景和需求,实时做出最优的卸载决策。
- 任务调度与资源管理模块:根据深度学习模型的输出,智能调度任务到不同的边缘服务器,并实时管理计算资源,确保资源的最大化利用。
- 反馈与优化模块:通过对卸载效果的反馈,持续优化深度学习模型,不断提升系统的整体性能。
实际应用:智能城市与工业物联网
基于分布式深度学习的移动边缘计算卸载技术,具有广泛的应用前景。在智能城市建设、工业物联网(IIoT)以及自动驾驶等领域,都能发挥巨大的作用。
- 智能城市:在智能城市中,基于分布式深度学习的卸载技术可以帮助处理大量的实时数据,如交通监控、环境监测等任务。通过智能卸载,提升了数据处理效率,减少了网络带宽的压力。
- 工业物联网:在工业生产中,设备数量庞大且任务繁重,传统的卸载方法难以满足高效能的要求。利用分布式深度学习技术,可以智能调度计算任务,优化生产流程,减少设备故障和停机时间。
- 自动驾驶:自动驾驶系统需要处理大量来自传感器和摄像头的数据,深度学习卸载能够有效分担边缘设备的计算任务,确保实时决策与反应的精准性。


















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











