



 本文介绍了神经元模型、感知机、BP算法,强调了深度学习中多层网络的重要性,包括误差逆传播、权重调整策略以及深度信念网络和卷积神经网络的应用。
本文介绍了神经元模型、感知机、BP算法,强调了深度学习中多层网络的重要性,包括误差逆传播、权重调整策略以及深度信念网络和卷积神经网络的应用。
【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集
西瓜书《机器学习》+南瓜书《机器学习公式讲解》。
task04 详读西瓜书+南瓜书ch5
神经元模型
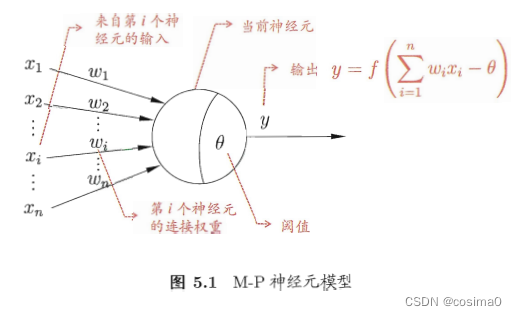
将一个神经网络视为包含了许多参数的数学模型,这
个模型是若干个函数,相互(嵌套)代入而得。有效的
神经网络学习算法大多以数学证明为支撑。
激活函数:最理想的是阶跃函数,Sigmoid函数将较大范围内变化的输入值挤压到 (0,1) 输出值范围内,作为近似。
感知机
结构:两层神经元。
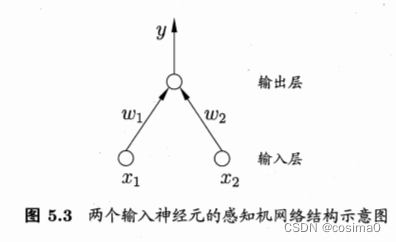
感知机能容易地实现逻辑与、或、非运算。只有输出层是M-P神经元,即只有输出层神经元进行激活函数处理,也称为功能神经元,输入层只是接受外界信号(样本属性)并传递给输出层(输入层的神经元个数等于样本的属性数目),而没有激活函数。由于感知机模型只有一层功能神经元,因此其功能十分有限,只能处理线性可分的问题。
要解决非线性可分问题,需要考虑使用多层功能神经元,即神经网络:
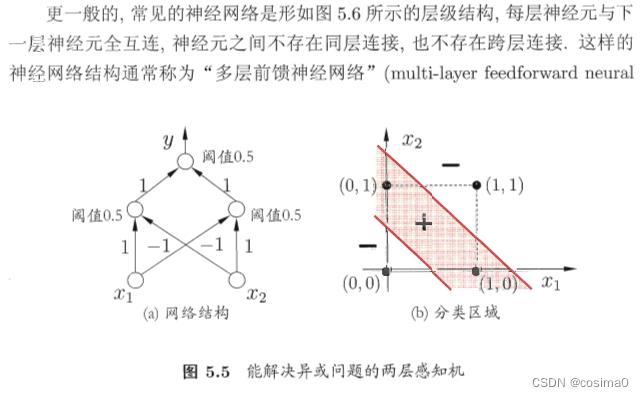
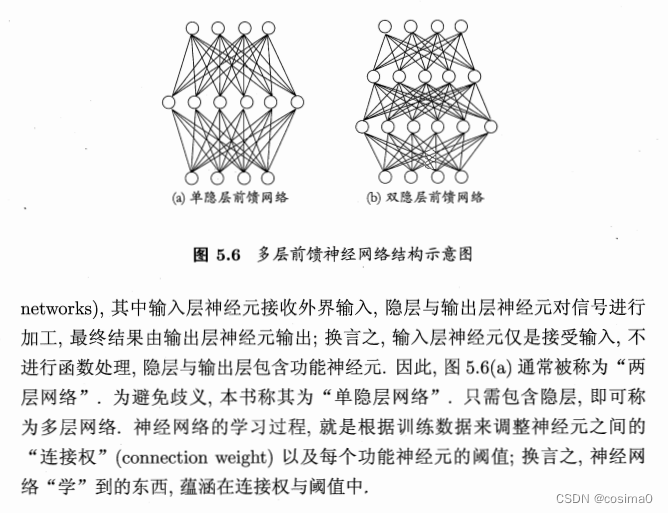
误差逆传播算法(BP算法)
神经网络的学习主要蕴含在权重和阈值中,多层网络使用简单感知机的权重调整规则显然不够,BP神经网络算法(误差逆传播算法)正是为学习多层前馈神经网络而设计,是迄今为止最成功的的神经网络学习算法。
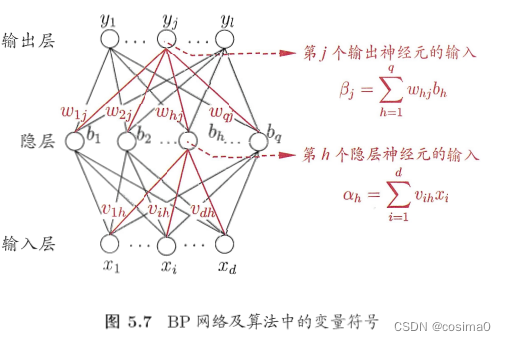
BP神经网络算法也使用梯度下降法(gradient descent),以单个样本的均方误差的负梯度方向对权重进行调节。学习率η控制着算法每一轮迭代中的更新步长。

[Hornik et al., 1989]证明,只需一个包含足够多神经元的隐层,多层前馈网络就能以任意精度逼近任意复杂度的连续函数.然而,如何设置隐层神经元的个数仍是个未决问题,实际应用中通常靠“试错法”(trial-by-error)调整。对于过拟合问题,常使用“早停”和“正则化”的策略。
全局最小与局部极小
“全局最小”一 定是 “局部极小”,反之不一定。

其他神经网络
深度学习
理论上,参数越多,模型复杂度就越高,容量就越大,从而能完成更复杂的学习任务。
增大模型复杂度:一是增加隐层的数目,二是增加隐层神经元的数目。前者更有效一些,因为它不仅增加了功能神经元的数量,还增加了激活函数嵌套的层数。但是对于多隐层神经网络,经典算法如标准BP算法往往会在误差逆传播时发散,无法收敛达到稳定状态。
训练多隐层神经网络常用两个方法:
无监督逐层训练:每次训练一层隐节点,把上一层隐节点的输出当作输入来训练,本层隐结点训练好后,输出再作为下一层的输入来训练,这称为预训练。全部预训练完成后,再对整个网络进行微调训练。如 深度信念网络(DBN)。可以视为把大量的参数进行分组,先找出每组较好的设置,再基于这些局部最优的结果来训练全局最优。
权共享:令同一层神经元使用完全相同的连接权,典型的例子是卷积神经网络(CNN)。可以大大减少需要训练的参数数目。
深度学习可以理解为一种特征学习,通过多个隐层来把与输出目标联系不大的初始输入转化为与输出目标更加密切的表示,使原来只通过单层映射难以完成的任务变为可能。即通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示,从而使得最后可以用简单的模型来完成复杂的学习任务。
参考:https://www.heywhale.com/mw/project/5e4fa28a0e2b66002c1f8a37

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









