



目录
1 准备环境
微调模型需要的环境有两个包:transformers,llama-factory。
1.1 transformers
这个包提供了调用hugging face上预训练模型的工具,如分词器等。
下载的命令是:
pip install transformers
1.2 llama-factory
这个包是用于微调的第三方工具,提供了可视化的界面,避免了书写繁杂的微调命令。
可以使用这个命令直接git下载,
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git也可以在https://github.com/hiyouga/LLaMA-Factory这个地址直接下载压缩包,然后解压。
下载完之后进入到这个文件夹。
cd LLaMA-Factory执行下面这个命令就能安装成功。
pip install -e ".[torch,metrics]"用这个命令检查是否安装成功。
llamafactory-cli version若出现下面这个页面就证明安装成功了。

2 准备模型
在这里我使用的是Qwen2.5-0.5B-instruct这个预训练模型,这个预训练模型是阿里云研制的通用大模型,微调要比运行模型需要更多的显存,根据不同的微调方法,需要的显存也不同。我在这里使用LoRA微调方法,建议不要低于8GB显存。
这是预训练模型的地址。
https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct
3 准备数据集
将需要微调的模型和准备好的数据集放在同一个根目录下。
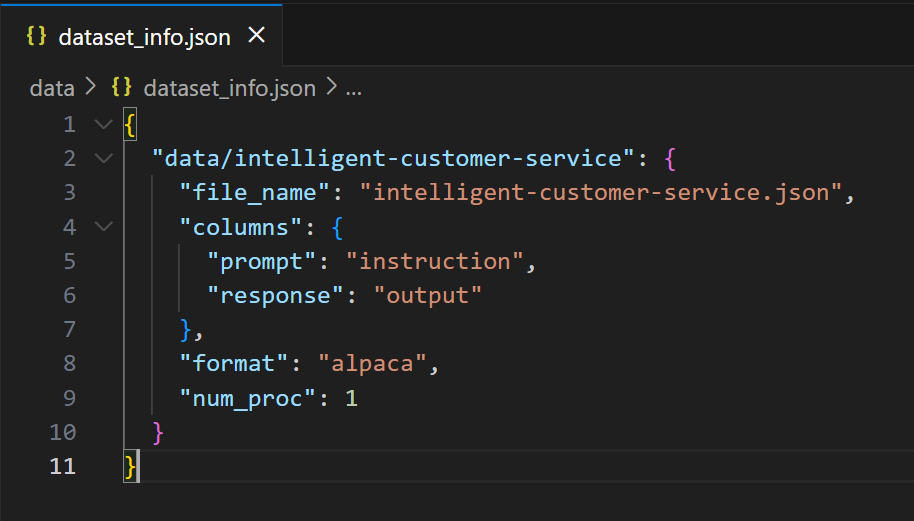
使用llama-factory微调模型时,数据集里必须有一个dataset_info.json文件,这个文件用于标示使用的数据集名称以及格式等参数,如果你有多个数据集,可以在这里都写上,在微调时可以选择多个数据集进行微调。
我这里微调的Qwen模型的数据集是由GPT生成的,instruction表示这句话的摘要,output表示应该输出的结果,其实这里应该也有一个input,但我懒得整,给省略了。但是instruct和output是必须要有的,不能省。
[
{
"instruction": "早安呀宝贝~今天有什么安排吗?",
"output": "早呀亲爱的~今天想和你视频一起做早餐,然后晚上去看新上映的爱情电影好不好呀?😘"
},
{
"instruction": "工作好累,求安慰...",
"output": "抱抱我的大英雄~给你准备了惊喜歌单🎵,下班后带你去吃最爱的寿司放松好吗?(摸摸头)"
}
]4 开始微调
使用这个命令打开可视化页面。打开后的页面长这个样子。
llamafactory-cli webui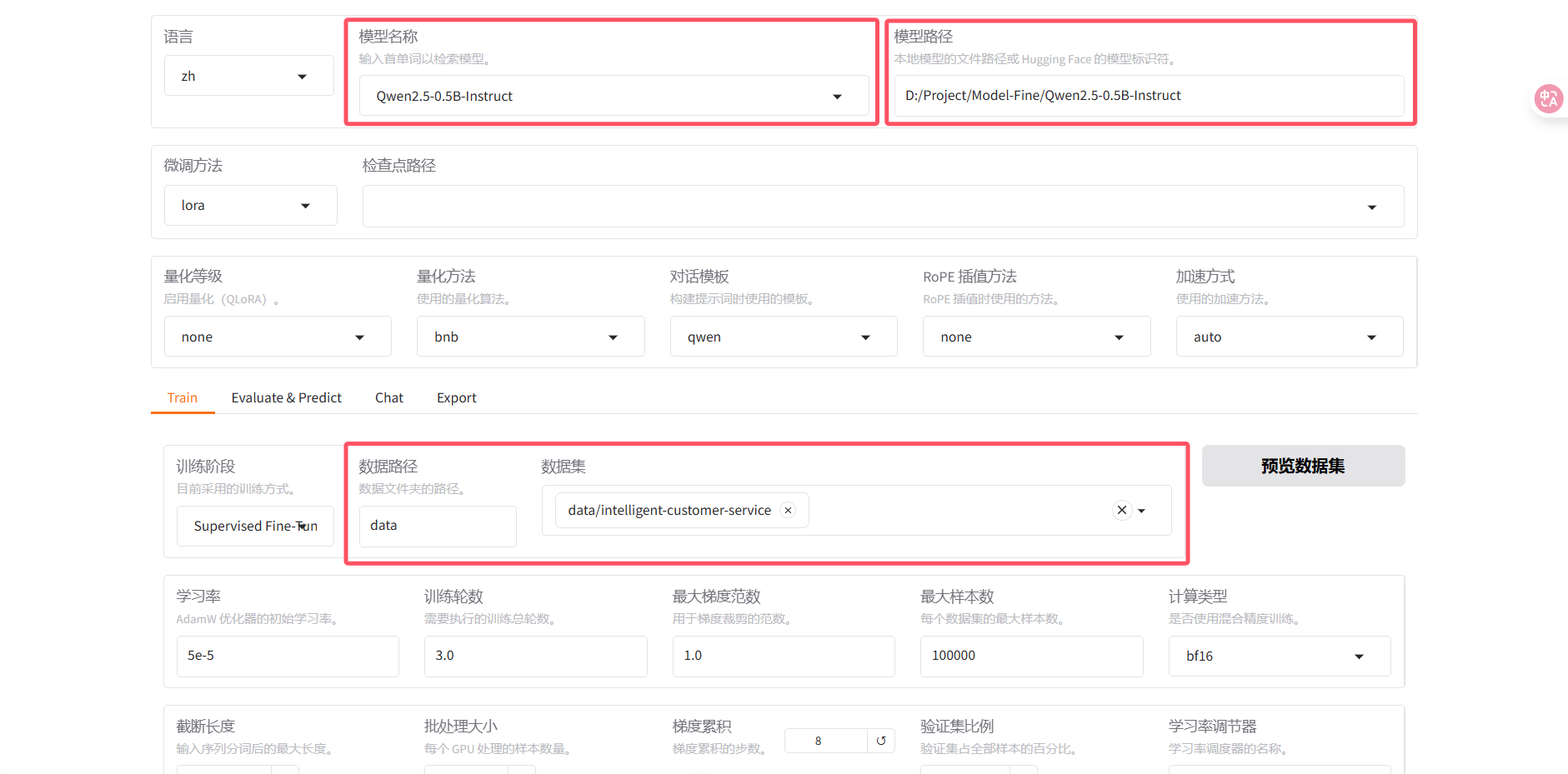
这里提供的功能非常全面,比如语言、微调方法、是否启用量化等。这里的参数大家可以后续自行研究,这里不再赘述。
我们选择我们要微调的模型名称,并在模型地址里指定我们刚才从hugging face里下载的模型地址即可,并选择我们要微调的数据集是哪一个(如果不配置dataset_info.json,会找不到数据集)。
设置好超参数等,点击开始就会自动微调了,并且还会自动显示损失值的变化情况。
5 模型导出
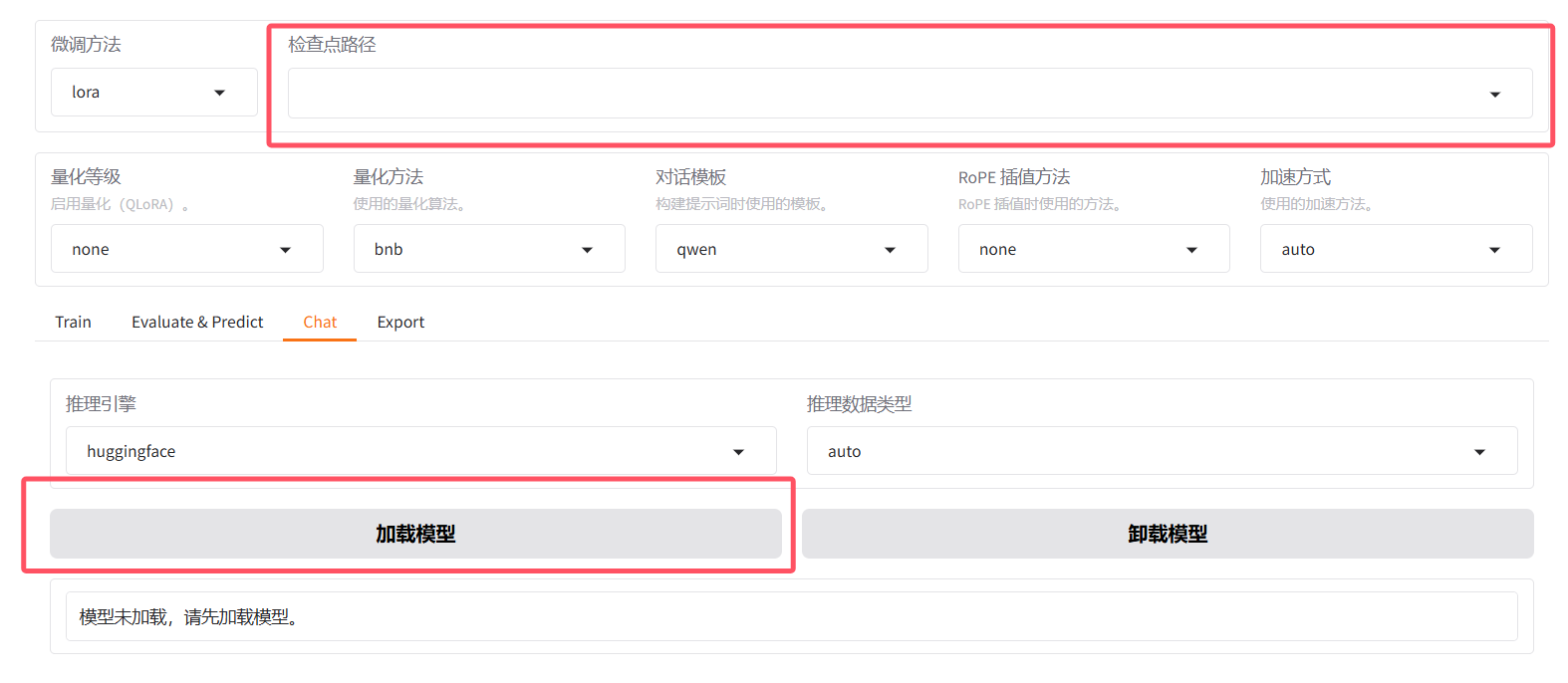
在检查点路径这里将微调的参数加载进来,然后点击加载模型,测试一下微调后的效果。如果不满意可以在这个基础上接着微调,如果感觉不错,可以把模型导出。
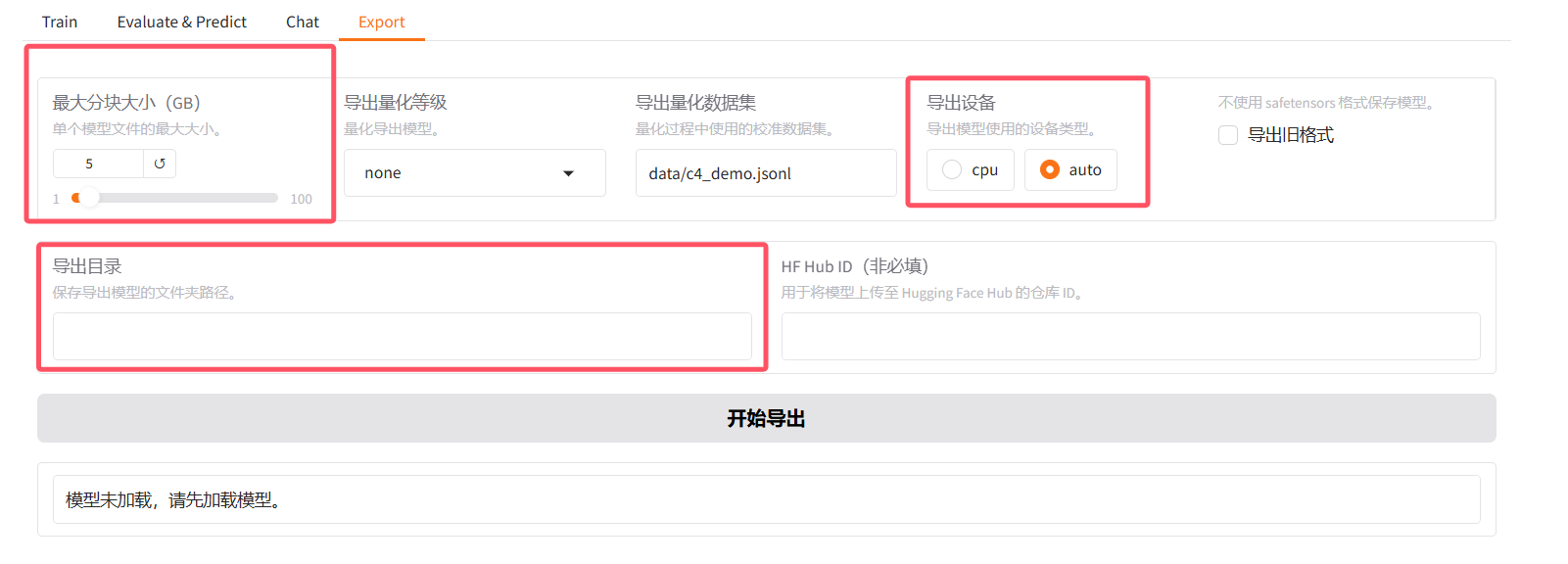
如果你微调的模型很大,可以把参数分块导出,导出的设备让他自动选择吧。设置好模型导出的目录就可以导出了。
到此为止,你就微调了一个模型并且导出成功了,你可以把模型微调成任何你想要的类型(如伴侣、朋友等),如果你觉得模型性能不够好,请准备更大的数据集和参数更多的模型,然后选择合适的量化方法,提升模型参数的同时,还可以降低显存的需求。


















 2762
2762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









