







 超级会员免费看
超级会员免费看
目录
Transformer模型由于其卓越的表现,广泛应用于自然语言处理、计算机视觉等领域。然而,这种模型在训练时往往需要消耗巨大的计算资源,尤其是在面对大规模数据集和复杂任务时,计算需求呈指数增长。
Transformer模型的出现彻底改变了自然语言处理(NLP)和计算机视觉(CV)等领域的研究格局。自2017年《Attention is All You Need》论文提出Transformer架构以来,这一模型因其卓越的性能和强大的灵活性在各种任务中取得了令人瞩目的成绩。尤其是在机器翻译、文本生成、情感分析、语音识别等领域,Transformer展现了极大的潜力。然而,Transformer模型的训练通常需要非常庞大的计算资源,尤其是在处理大规模数据集和复杂任务时,计算需求呈现出指数级增长。
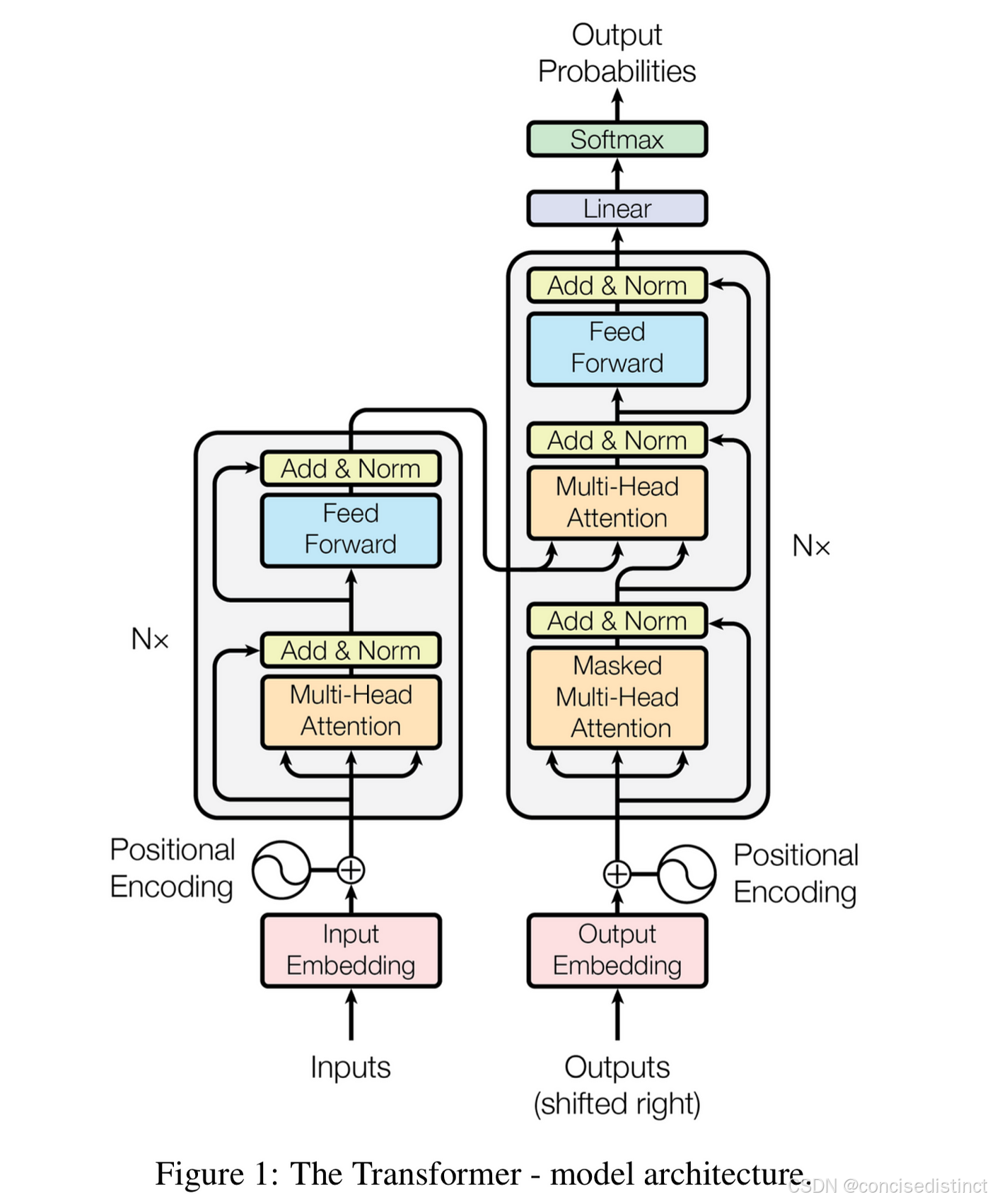
这种对算力的需求往往引发了一个重要的问题:为什么Transformer模型在训练过程中需要如此大量的计算资源?是否有理论上解释这一现象的原因?
1. 自注意力机制的计算复杂度
自注意力(Self-Attention)机制是Transfor

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











