








 超级会员免费看
超级会员免费看

图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
本文直接从一个RLHF开源项目源码入手(deepspeed-chat),根据源码的实现细节,给出尽可能丰富的训练流程图,并对所有的公式给出直观的解释。希望可以帮助大家更具象地感受RLHF的训练流程。关于RLHF,各家的开源代码间都会有一些差异,同时也不止PPO一种RLHF方式。
1.强化学习概述
1.1 强化学习整体流程
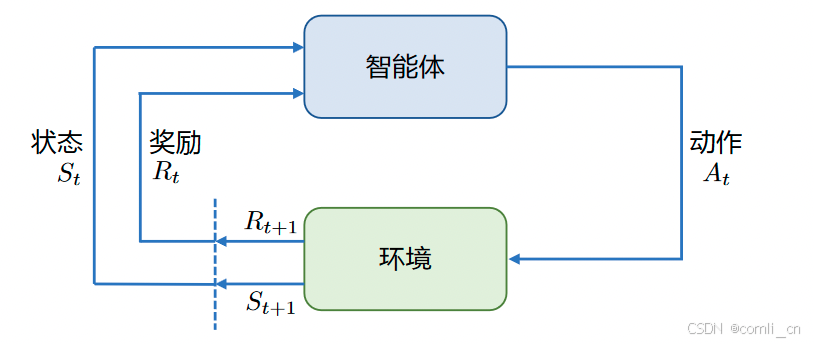
强化学习的两个实体:智能体(Agent)与环境(Environment)
强化学习中两个实体的交互:
- 状态空间S:S即为State,指环境中所有可能状态的集合
- 动作空间A:A即为Action,指智能体所有可能动作的集合
- 奖励R:R即为Reward,指智能体在环境的某一状态下所获得的奖励。
以上图为例,智能体与环境的交互过程如下:
- 在

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











