








 超级会员免费看
超级会员免费看

Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Paper: https://arxiv.org/abs/2305.18290
Code: https://github.com/eric-mitchell/direct-preference-optimization
1.简介
基于人类反馈的强化学习(RLHF) 是一个复杂且不稳定的过程,拟合一个反映人类偏好的奖励模型,然后使用强化学习对大语言模型进行微调,以最大限度地提高估计奖励,同时又不能偏离原始模型太远。这涉及训练多个 LM,并在训练循环中从 LM 采样,从而产生大量的计算成本。
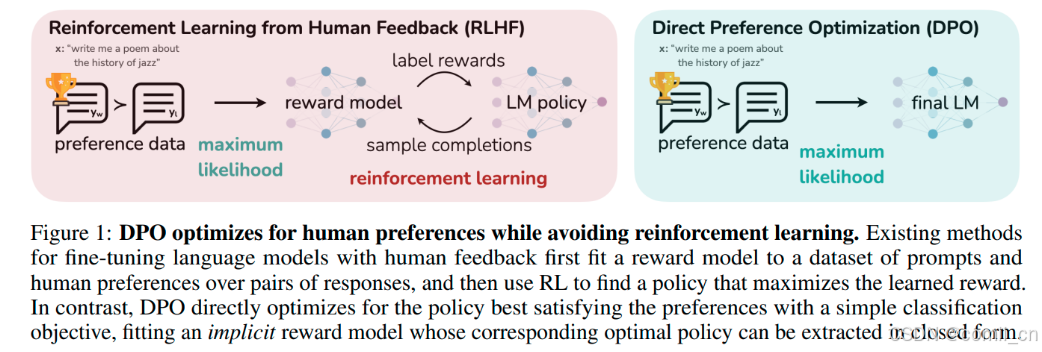
本文作者提出了直接偏好优化(DPO)算法,它稳定、高效且计算量轻,无需拟合奖励模型,也无需在微调期间从LM采样或执行显著的超参数调整。
实验表明,DPO 可以微调 LMs,使其与人类偏好保持一致,与现有方法一样或更好。值得注意的是,DPO 在情绪控制的能力上超越了 RLHF,提高了总结和单轮对话的响应质量,同时大大简化了实现和训练。
2.RLHF pipeline
RLHF通常由3个阶段组成:
- 监督微调 (SFT):

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 147
147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











