







 超级会员免费看
超级会员免费看
在数据并行训练中,一个明显的特点是每个 GPU 持有整个模型权重的副本,这就带来了冗余问题,虽然,FSDP 可以缓解冗余的问题,但是对于超大规模模型来说,仅使用数据并行进行分布式训练没办法使模型的参数规模进一步提升。因此,另一种并行技术是模型并行,即模型被分割并分布在一个设备阵列上,每一个设备只保存模型的一部分参数。
模型并行分为张量并行和流水线并行,张量并行为层内并行,对模型 Transformer 层内进行分割、流水线为层间并行,对模型不同的 Transformer 层间进行分割。
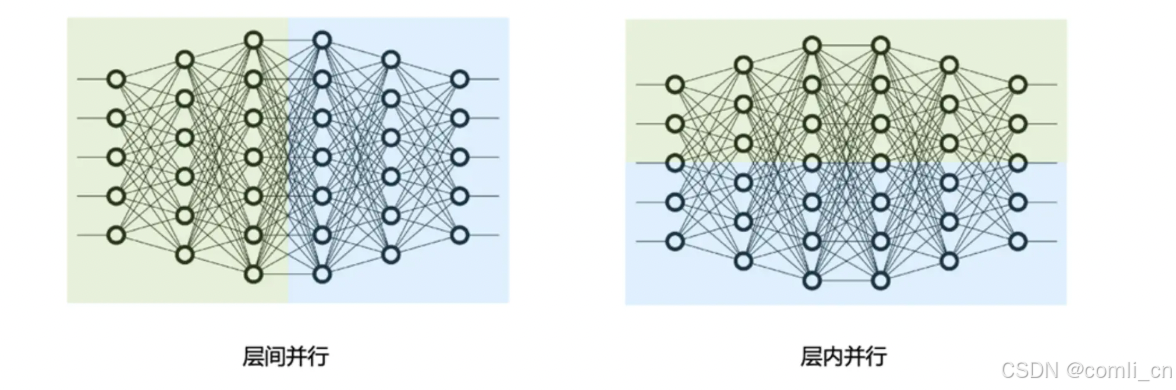
1.简介
所谓流水线并行,就是由于模型太大,无法将整个模型放置到单张GPU卡中;因此,将模型的不同层放置到不同的计算设备,降低单个计算设备的显存消耗,从而实现超大规模模型训练。 如下图所示,模型共包含四个模型层(如:Transformer层),被切分为三个部分,分别放置到三个不同的计算设备。即第 1 层放置到设备 0,第 2 层和第 3 层放置到设备 1,第 4 层放置到设备 2。
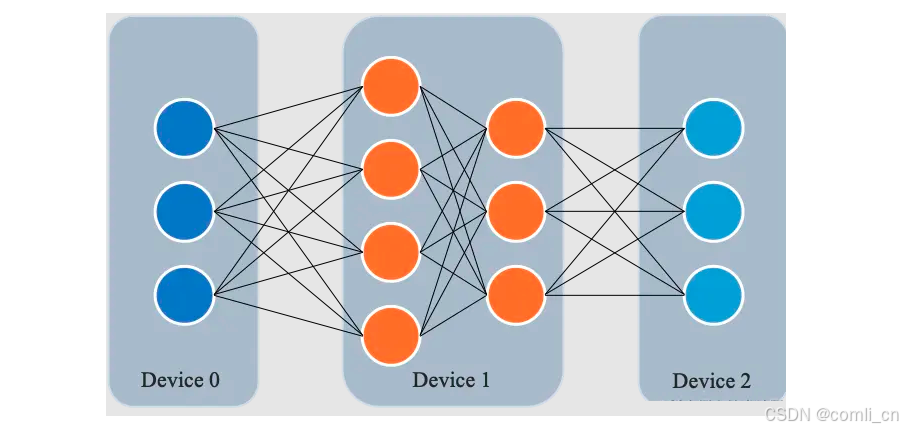
相邻设备间通过通信链路传输数据。具体地讲,前向计算过程中,输入数据首先在设备 0 上通过第 1 层

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











