







 超级会员免费看
超级会员免费看
和流水线并行类似,张量并行也是将模型分解放置到不同的GPU上,以解决单块GPU无法储存整个模型的问题。和流水线并行不同的地方在于,张量并行是针对模型中的张量进行拆分,将其放置到不同的GPU上。
1.简述
模型并行是不同设备负责单个计算图不同部分的计算。而将计算图中的层内的参数(张量)切分到不同设备(即层内并行),每个设备只拥有模型的一部分,以减少内存负荷,我们称之为张量模型并行。
张量并行从数学原理上来看就是对于linear层就是把矩阵分块进行计算,然后把结果合并;对于非linear层,则不做额外设计。
2.张量并行方式
张量切分方式分为按行进行切分和按列进行切分,分别对应行并行(Row Parallelism)与列并行(Column Parallelism)。
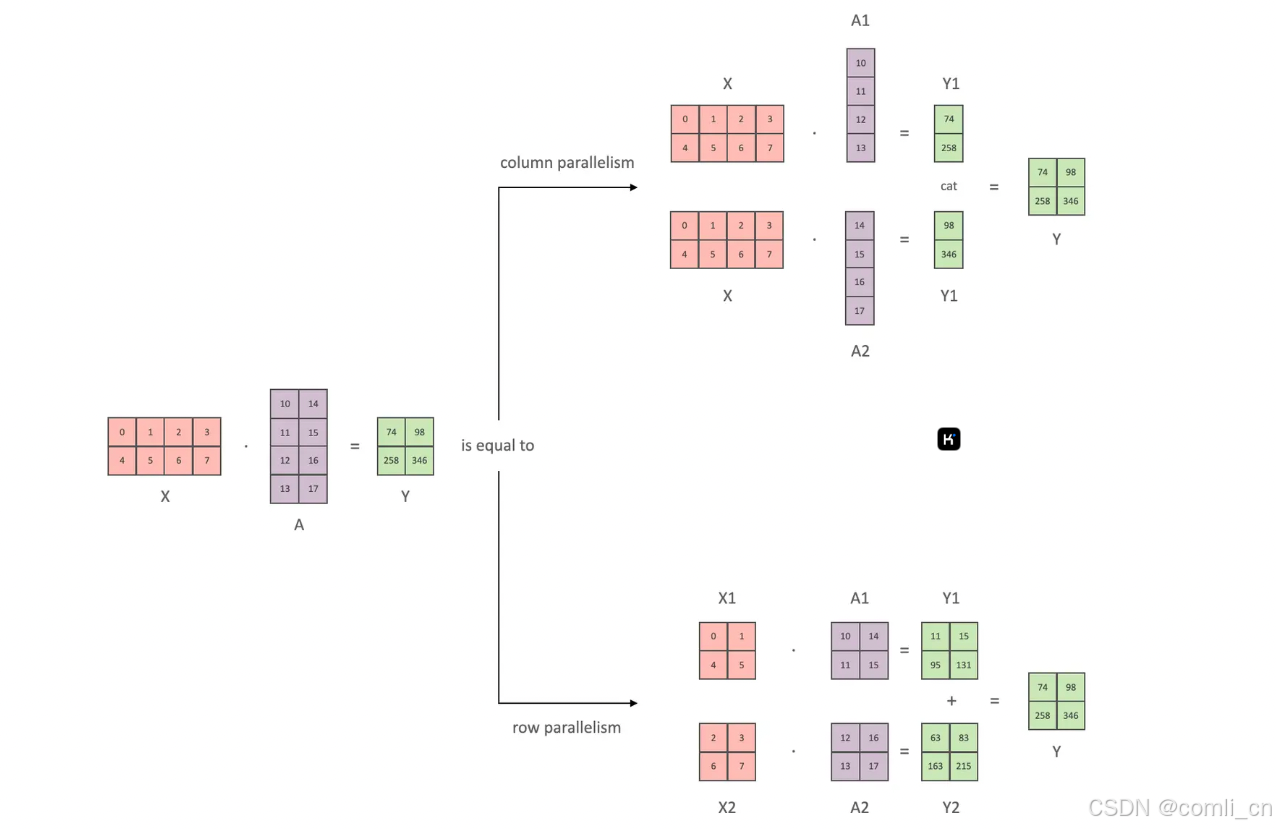
下面用通用矩阵的矩阵乘法(GEMM)来进行示例,看看线性层如何进行模型并行。假设 Y = XA ,对于模型来说,X 是输入,A是权重,Y是输出。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











