




 超级会员免费看
超级会员免费看
1.简述
所谓数据并行,就是由于训练数据集太大;因此,将数据集分为N份,每一份分别装载到N个GPU节点中,同时,每个GPU节点持有一个完整的模型副本,分别基于每个GPU中的数据去进行梯度求导。然后,在GPU0上对每个GPU中的梯度进行累加,最后,再将GPU0聚合后的结果广播到其他GPU节点。
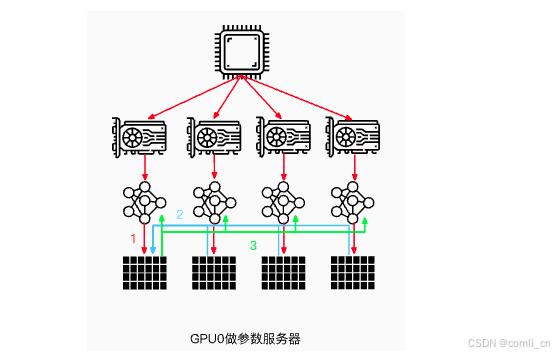
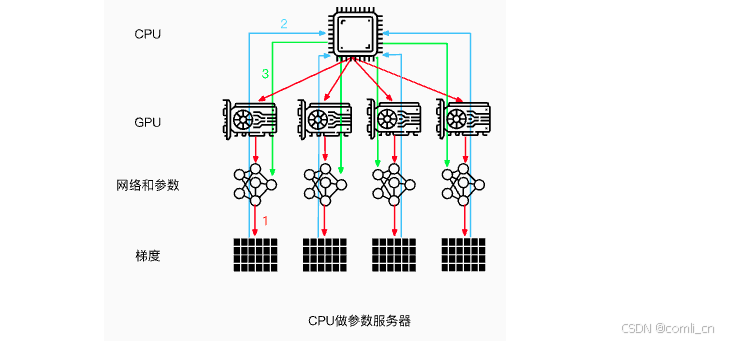
注意:这里是以GPU0作为参数服务器,除此之外,还可以使用CPU作为参数服务器。但是这种场景的训练速度通常会慢于使用GPU0作为参数服务器(通常情况下,GPU与CPU之间通信使用PCIe,而GPU与GPU之间通信使用Nvlink)。
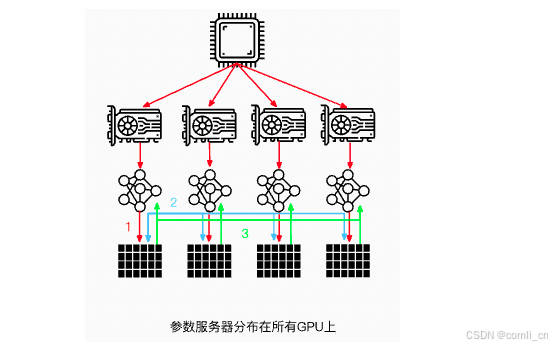
当然,还可以将参数服务器分布在所有GPU节点上面,每个GPU只更新其中一部分梯度。
当然,数据并行不仅仅指对训练的数据并行操作,还可以对网络模型梯度、权重参数、优化器状态等数据进行并行。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











