




 本文详细解读了使用PyTorch实现的智能数字图像处理中FastRCNN模型的训练过程。通过create_model方法创建模型,包括设置分类数、加载预训练权重,并替换分类头部。在main方法中,处理设备选择、数据预处理、加载数据集、定义优化器、学习率调度器,并根据用户参数进行训练和权重保存。代码还包含了训练过程的损失和mAP曲线绘制功能。
本文详细解读了使用PyTorch实现的智能数字图像处理中FastRCNN模型的训练过程。通过create_model方法创建模型,包括设置分类数、加载预训练权重,并替换分类头部。在main方法中,处理设备选择、数据预处理、加载数据集、定义优化器、学习率调度器,并根据用户参数进行训练和权重保存。代码还包含了训练过程的损失和mAP曲线绘制功能。
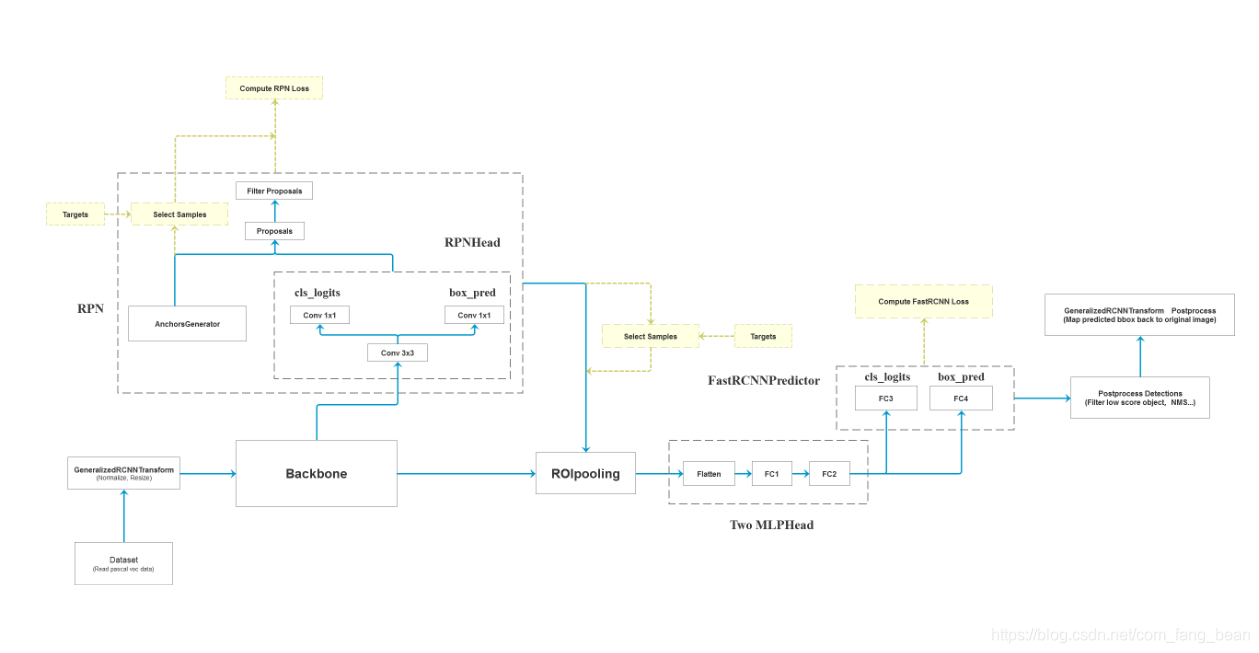
解读create_model方法
1. num_classes:分类数
2.backbone = resnet50_fpn_backbone()
model = FasterRCNN(backbone=backbone, num_classes=91)-》调用faster_rcnn_framework的FasterRCNN方法,传入分类数num_classes为91
3.weights_dict = torch.load("./backbone/fasterrcnn_resnet50_fpn_coco.pth")
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)-》加载预训练的权重文件
4. if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)-》打印预训练权重信息
5.in_features = model.roi_heads.box_predictor.cls_score.in_features-》获取分类器输入特征的数量
6.model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)-》用一个新的头替换一个预先训练好的头
解读main方法:
1.device = torch.device(parser_data.device if torch.cuda.is_available() else "cpu")-》查看设备是否有可用的GPU
2.data_transform = {-》图像预处理函数
"train": transforms.Compose([transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5)]),-》随机水平翻转
"val": transforms.Compose([transforms.ToTensor()])
}
3.VOC_root = parser_data.data_path-》数据集根目录
4.train_data_set = VOC2012DataSet(VOC_root, data_transform["train"], True)-》加载数据集的VOC2012DataSet方法
5.加载训练数据集
train_data_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=1,
shuffle=False,
num_workers=0,
collate_fn=utils.collate_fn)
val_data_set = VOC2012DataSet(VOC_root, data_transform["val"], False)
val_data_set_loader = torch.utils.data.DataLoader(val_data_set,
&nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3719
3719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









