




目录
激活函数(Activation Function) 是神经网络中的一个关键组件,负责将输入的线性组合转化为非线性输出。它赋予神经网络模型以复杂的表达能力,使其能够处理非线性问题,比如分类、图像识别和自然语言处理等任务。
Sigmoid
Sigmoid 函数是深度学习中最早广泛使用的激活函数之一,它将输入值映射到 ( 0 , 1 ) 的区间,输出为一个概率值。其公式为:
特点:输出值在 0到1之间,因此常用于二分类问题。
缺点:梯度消失问题,在输入值较大或较小时,Sigmoid 函数的梯度(导数)接近零,这会导致反向传播过程中梯度逐渐减小(消失),影响权重的更新,特别是在深层网络中。
图示:

Tanh 函数
Tanh(双曲正切函数)是 Sigmoid 的扩展版本,输出范围为 ( − 1 , 1 ) ,可以解决 Sigmoid 在输出上的偏移问题。其公式为

特点:输出范围为 (-1, 1),相比 Sigmoid 更加居中,能够减少偏移(mean shift)问题。
缺点:同样存在梯度消失问题,在输入值非常大或非常小时,Tanh 的梯度依然会变得很小。
图示:

ReLU(Rectified Linear Unit)函数
ReLU 是目前使用最为广泛的激活函数之一。ReLU 函数的输出在正数区域保持线性,在负数区域则为 0。其公式为:
特点:当输入大于 0 时,ReLU 直接输出输入值;当输入小于 0 时,输出为 0。
优点:
解决梯度消失问题:ReLU 的梯度为 1(当 x > 0 x > 0x>0 时),不会像 Sigmoid 和 Tanh 那样使梯度变小,从而有效缓解梯度消失问题。
计算效率高:ReLU 计算非常简单,只需要一个最大值操作,非常适合在深层网络中使用。
缺点:死亡 ReLU 问题,当输入的值小于 0 时,ReLU 的输出一直为 0,这意味着神经元可能会永远不再激活,这在某些情况下会导致网络性能下降。

Leaky ReLU
Leaky ReLU 是对 ReLU 的一种改进,解决了 ReLU 在负数区域输出为 0 时神经元“死亡”的问题。Leaky ReLU 在负数区域给予一个很小的正数斜率 α (通常为 0.01)而不是完全为 0,其公式为:

优点:在负数区域仍然保持一个小的斜率,使得神经元不完全失活。减少了 ReLU 函数中的死亡 ReLU 问题,确保神经元即使在负值输入时也能有一定的梯度更新。

ELU(Exponential Linear Unit)
ELU 是另一种改进的 ReLU 激活函数,在负数区域使用指数函数进行平滑。其公式为:

其中 α 是一个超参数,通常取值为 1。
- 特点:在正数区域与 ReLU 类似,但在负数区域使用指数函数进行平滑,避免了死亡 ReLU 问题。
- 优点:与 Leaky ReLU 相比,ELU 在负数区域提供的平滑曲线可以在一定程度上减少偏差。
- 缺点:计算量比 ReLU 稍大,因为负数区域的计算涉及指数运算。

SEIU
是ELU激活函数的可扩展变体,如果你构建一个仅由密集层堆叠组成的神经网络,并且如果所有隐藏层都使用SELU激活函数,则该网络是自归一化的:每层的输出倾向于在训练过程中保留平均值0和标准差1,从而解决了梯度消失/梯度爆炸的问题。
SELU激活函数通常大大优于这些神经网络(尤其是深层神经网络)的其他激活函数。但是,有一些产生自归一化的条件
- ·输入特征必须是标准化的(平均值为0,标准差为1)。
- ·每个隐藏层的权重必须使用LeCun正态初始化。在Keras中,这意味着设置kernel_initializer="lecun_normal"。·
- 网络的架构必须是顺序的。不幸的是,如果你尝试在非顺序架构(例如循环网络)中使用SELU(见第15章)或具有跳过连接的网络(即在Wide&Deep网络中跳过层的连接),将无法保证自归一化,因此SELU不一定会胜过其他激活函数。
Swish
Swish 是一种新的激活函数,由 Google 提出,它结合了 ReLU 和 Sigmoid 的优势。其公式为

特点:Swish 在小于 0 的输入值时逐渐趋近于 0,而在大于 0 时逐渐增大,因此它在负值区域不会像 ReLU 那样硬性截断。
优点:Swish 的非线性变化更加平滑,能够捕获更多的复杂模式,特别适合用于深度神经网络中。
缺点:计算量比 ReLU 更大,因为它涉及 Sigmoid 的计算。

激活函数的选择
神经网络中的激活函数选择取决于具体任务和网络结构。以下是一些常见的经验法则:
- ReLU 是目前最常用的激活函数,特别是在卷积神经网络(CNN)和全连接网络(FCN)中表现优异。对于大多数深度网络,ReLU 是一个很好的起点,因为它能有效避免梯度消失问题。
- Leaky ReLU 和 ELU 是 ReLU 的改进版本,适合于有负输入的场景或避免神经元失活的场景。
- Sigmoid 和 Tanh 适用于一些特殊情况,特别是在需要输出概率或对称输出的情况下(例如,输出为 [-1, 1])。不过它们通常会导致梯度消失,因此不推荐用于深层网络。
- Swish 是一种更平滑的激活函数,在某些复杂任务(如超深网络)上可能表现优异。
通常SELU>ELU>leaky ReLU(及其变体)>ReLU>tanh>logistic
- 如果网络的架构不能自归一化,那么ELU的性能可能会优于SELU(因为SELU在z=0时不平滑)。
- 如果你非常关心运行时延迟,那么你可能更喜欢leaky ReLU。
- 如果你不想调整其他超参数,则可以使用Keras使用的默认α值(例如,leaky ReLU为0.3)。
如果你有空闲时间和计算能力,则可以使用交叉验证来评估其他激活函数,例如,如果网络过拟合,则为RReLU;如果你的训练集很大,则为PReLU。也就是说,由于ReLU是迄今为止最常用的激活函数,因此许多库和硬件加速器都提供了ReLU特定的优化。因此,如果你将速度放在首位,那么ReLU可能仍然是最佳选择。
激活函数和初始化关联

初始化
keras常见的初始化方法
| 初始化方法 | 参数 |
| 正态化的Glorot初始化 | glorot_normal |
| 标准化的Glorot初始化 | glorot_uniform |
| 正态化的he初始化 | he_normal |
| 标准化的he初始化 | he_uniform |
| 正态化的lecun初始化 | lecun_normal |
| 标准化的lecun初始化 | lecun_uniform |
| 截断正态分布 | truncated_normal |
| 标准正态分布 | random_normal |
| 均匀分布 | random_uniform |
原理:
能显著缓解不稳定梯度问题的方法:
需要信号在两个方向上正确流动:进行预测时,信号为正向;在反向传播梯度时,信号为反向。既不希望信号消失,也不希望它爆炸并饱和
必须按照公式11-1中所述的随机初始化每层的连接权重,其中
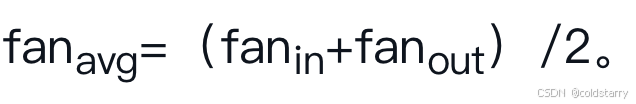
其中in和out代表该层的输入和神经元(这些数字称为该层的扇入和扇出),
Glorot

LeCun
公式11-1中,用fan in替换fan avg,就是LeCun,当fanin=fanout时,LeCun初始化等效于Glorot初始化
公式内容
首先编写一个简单模型,并初始化其参数,然后 get_weights 并 plot 查看初始化参数的分布,这里接受 initial 参数并传给参数初始化,可以把上述常见初始化方法直接传入函数即可。这里 Dense 层 kernel 参数共有 50000 x 100 = 5000000 个:
def getDenseWeights(initial):
inputs = layers.Input(shape=(100,), name='input')
d1 = layers.Dense(50000, activation='sigmoid', name='dense1',kernel_initializer=initial)(inputs)
output = layers.Dense(7, activation='sigmoid', name='output')(d1)
model = keras.Model(inputs=inputs, outputs=output)
# 100 x 500
w_dense1 = np.array(model.get_layer('dense1').get_weights()[0]).reshape(-1) # 获取dense1层的参数
n, bins, patches = plt.hist(w_dense1,bins=1000)
plt.title(initial)
plt.xlabel('data range')
plt.ylabel('probability')
plt.show()直接输入上述初始化方法名称即可:
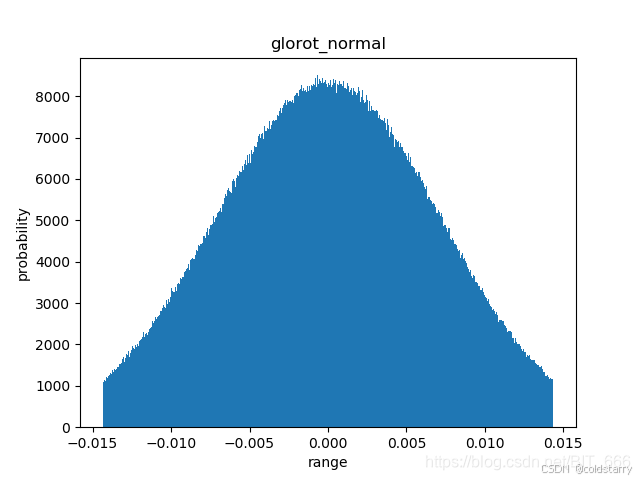
getDenseWeights("glorot_normal")glorot_normal(正态化的Glorot)
keras.initializers.glorot_normal(seed=None)
Glorot 正态分布初始化器,也称为 Xavier 正态分布初始化器。
它从以 0 为中心,标准差为 stddev = sqrt(2 / (fan_in + fan_out)) 的截断正态分布中抽取样本, 其中 fan_in 是权值张量中的输入单位的数量, fan_out 是权值张量中的输出单位的数量。
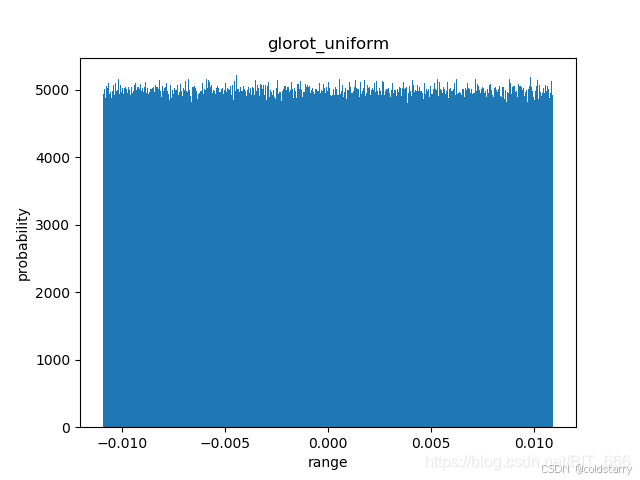
glorot_uniform(标准化的Glorot初始化)
keras.initializers.glorot_uniform(seed=None)
Glorot 均匀分布初始化器,也称为 Xavier 均匀分布初始化器。
它从 [-limit,limit] 中的均匀分布中抽取样本, 其中 limit 是 sqrt(6 / (fan_in + fan_out)), fan_in 是权值张量中的输入单位的数量, fan_out 是权值张量中的输出单位的数量。
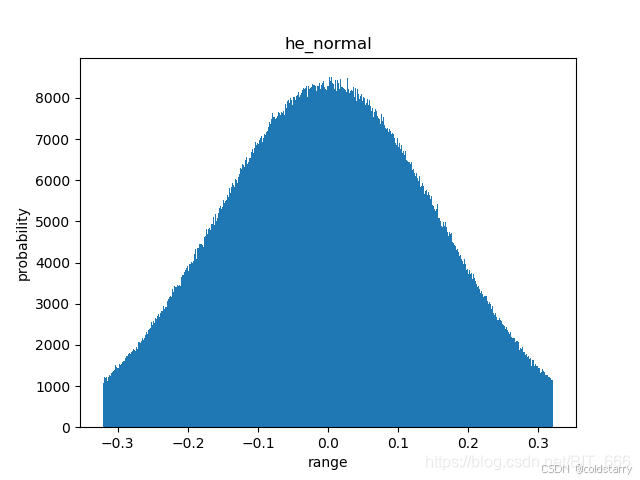
he_normal(正态化的he):
- 这种初始化方法由 He 等人在 2015 年提出,主要用于ReLU激活函数的网络中。
- 权重被初始化为均值为0,标准差为sqrt(2 / fan_in) 的正态分布,其中
fan_in是权重矩阵的输入维度。 - 这种初始化方法有助于在ReLU激活下保持输入和输出的方差一致,从而减少梯度消失或爆炸的问题。
keras.initializers.he_normal(seed=None)
He 正态分布初始化器。它从以 0 为中心,标准差为 stddev = sqrt(2 / fan_in) 的截断正态分布中抽取样本, 其中 fan_in 是权值张量中的输入单位的数量。
he_uniform(标准化化的he)
keras.initializers.he_uniform(seed=None)
He 均匀方差缩放初始化器。
它从 [-limit,limit] 中的均匀分布中抽取样本, 其中 limit 是 sqrt(6 / fan_in), 其中 fan_in 是权值张量中的输入单位的数量。
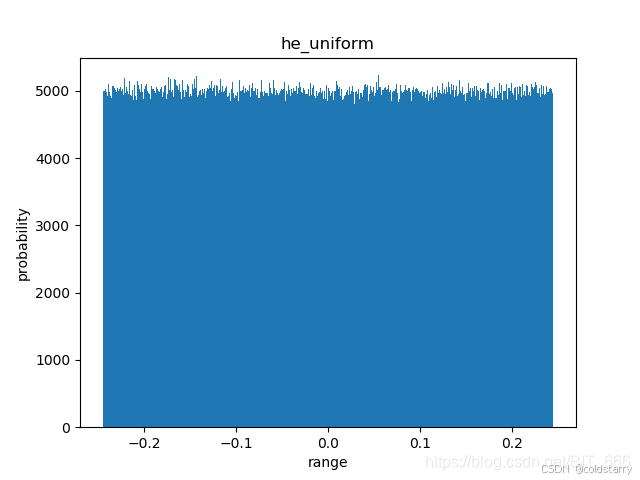
lecun_normal(正态化的lecun)
keras.initializers.lecun_normal(seed=None)
LeCun 正态分布初始化器。
它从以 0 为中心,标准差为 stddev = sqrt(1 / fan_in) 的截断正态分布中抽取样本, 其中 fan_in 是权值张量中的输入单位的数量。
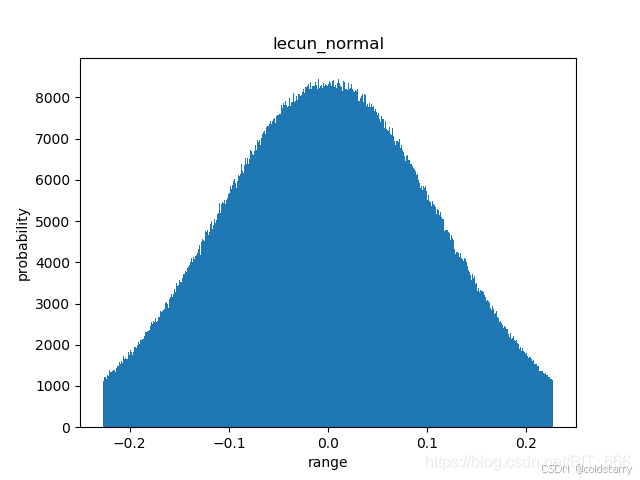
lecun_uniform(标准化的lecun)
keras.initializers.lecun_uniform(seed=None)
LeCun 均匀初始化器。
它从 [-limit,limit] 中的均匀分布中抽取样本, 其中 limit 是 sqrt(3 / fan_in), fan_in 是权值张量中的输入单位的数量。
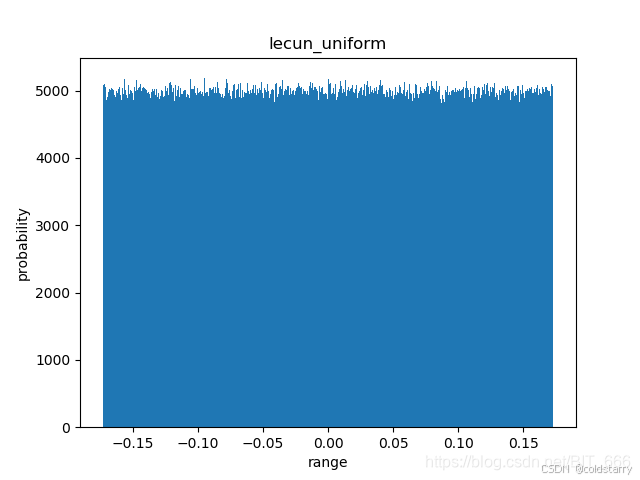
截断正态分布 -- truncated_normal
keras.initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None)
这个初始化方法是 tensorflow 的默认初始化方法,按照截尾正态分布生成随机张量的初始化器。
生成的随机值与 RandomNormal 生成的类似,但是在距离平均值两个标准差之外的随机值将被丢弃并重新生成。这是用来生成神经网络权重和滤波器的推荐初始化器。
参数
- mean: 一个 Python 标量或者一个标量张量。要生成的随机值的平均数。
- stddev: 一个 Python 标量或者一个标量张量。要生成的随机值的标准差。
- seed: 一个 Python 整数。用于设置随机数种子。
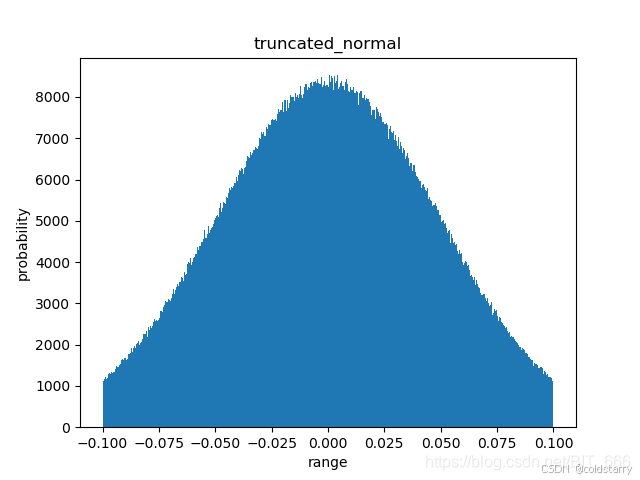
标准正态分布——random_normal
keras.initializers.RandomNormal(mean=0.0, stddev=0.05, seed=None)
标准正太分布
参数
- mean: 一个 Python 标量或者一个标量张量。要生成的随机值的平均数。
- stddev: 一个 Python 标量或者一个标量张量。要生成的随机值的标准差。
- seed: 一个 Python 整数。用于设置随机数种子。
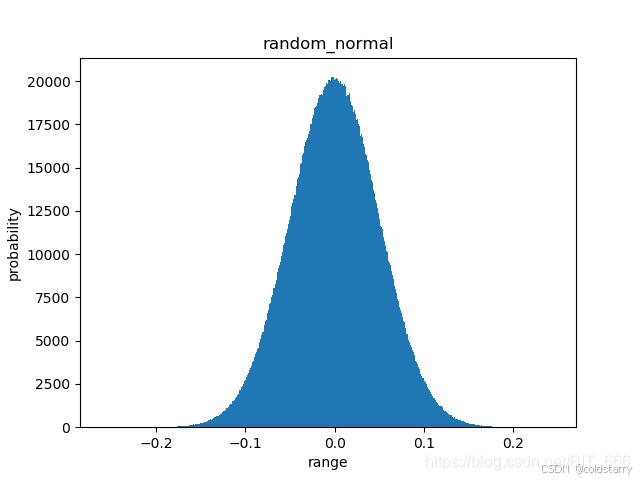
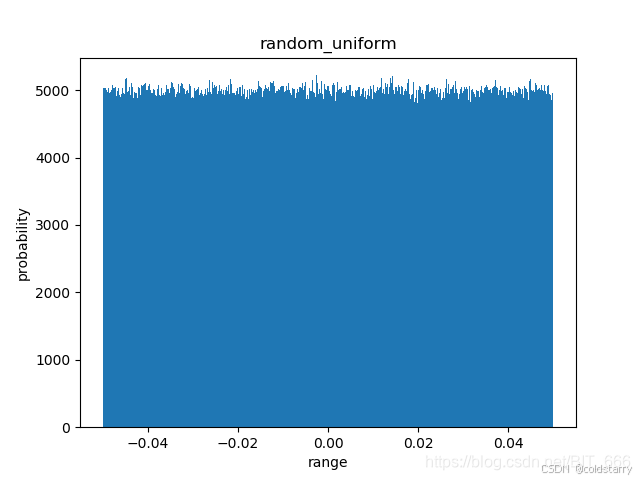
random_uniform(随机均匀分布):
- 这种初始化方法将权重初始化为在
[-0.05, 0.05]区间内均匀分布的随机值。 - 均匀分布的初始化方法简单直观,但可能不如正态分布那样有助于保持网络各层的激活值方差一致。
keras.initializers.RandomUniform(minval=-0.05, maxval=0.05, seed=None)
- minval: 一个 Python 标量或者一个标量张量。要生成的随机值的范围下限。
- maxval: 一个 Python 标量或者一个标量张量。要生成的随机值的范围下限。默认为浮点类型的 1。
- seed: 一个 Python 整数。用于设置随机数种子。
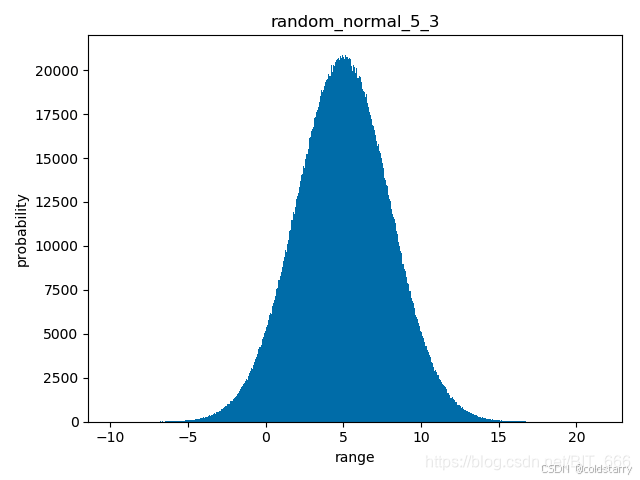
用initializers初始化参数
上面展示的初始化方法都使用了默认的函数名传入,无法控制 mean, std, limit 等参数,如果想要输入非默认的参数,可以采用如下形式,以 mean = 5 ,std = 3 的标准正态分布为例:
init = keras.initializers.RandomNormal(mean=5, stddev=3, seed=None)
def getDenseWeights(init):
inputs = layers.Input(shape=(100,), name='input')
d1 = layers.Dense(50000, activation='sigmoid', name='dense1',kernel_initializer=init)(inputs)
output = layers.Dense(7, activation='sigmoid', name='output')(d1)
model = keras.Model(inputs=inputs, outputs=output)参数换成对应的 initializers
自定义方式初始化参数
除了使用Api给出的方法外,也可以调用其他方法,自定义参数。自定义参数需要遵循如下条件,如果传递一个自定义的可调用函数,那么它必须使用参数 shape(需要初始化的变量的尺寸)和 dtype(数据类型):
def api_init(shape, dtype=None):
return K.random_normal(shape, dtype=dtype)把 api_init 传给 getDenseWeights 即可。
参考文章
【AI知识点】激活函数(Activation Function)-优快云博客
机器学习实战:基于Scikit-Learn、Keras和TensorFlow 书,封皮是个蜥蜴

















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









