




 本文详细介绍了梯度下降的基本过程,包括如何构造Loss Function,参数迭代更新的原理,学习率调整的技巧,如Adagrad自适应梯度算法和SGD随机梯度下降。还探讨了特征归一化的必要性,以及梯度下降在非凸函数优化中的局限性。
本文详细介绍了梯度下降的基本过程,包括如何构造Loss Function,参数迭代更新的原理,学习率调整的技巧,如Adagrad自适应梯度算法和SGD随机梯度下降。还探讨了特征归一化的必要性,以及梯度下降在非凸函数优化中的局限性。
一、基本过程
解决一个优化问题,通常需要构造一个
L
o
s
s
F
u
n
c
t
i
o
n
Loss Function
LossFunction ,找到最优的参数
θ
\theta
θ 使
L
o
s
s
F
u
n
c
t
i
o
n
Loss Function
LossFunction 最小:
θ
∗
=
arg
max
θ
L
(
θ
)
,
L
:
l
o
s
s
f
u
n
c
t
i
o
n
θ
:
p
a
r
a
m
e
t
e
r
s
\theta^*=\mathop{\arg\max}\limits_{\theta}L(\theta),\quad L:loss function \quad\theta:parameters
θ∗=θargmaxL(θ),L:lossfunctionθ:parameters
假设
θ
\theta
θ 有两个变量
{
θ
1
,
θ
2
}
\{\theta_1,\theta_2\}
{θ1,θ2},随机选择始点
θ
0
=
[
θ
1
0
θ
2
0
]
\theta^0=\begin{bmatrix} \theta^0_1 \\ \theta^0_2 \end{bmatrix}
θ0=[θ10θ20]
求偏微分,更新参数, θ 1 = θ 0 − η ∂ L ( θ 0 ) ∂ θ \theta^1=\theta^0-\eta\frac{\partial L(\theta^0)}{\partial\theta} θ1=θ0−η∂θ∂L(θ0)
此处减号表示是沿着负梯度方向更新的,梯度是上升最快的方向,负梯度就是下降最快的方向。因为我们要使L达到最小,如果偏导数是正数,说明变量值增加,L变大,此时变量应该减小来使L减小,因此减去 η ∂ L ( θ 0 ) ∂ θ \eta\frac{\partial L(\theta^0)}{\partial\theta} η∂θ∂L(θ0);如果偏导数是负数,说明变量值增加,L变小,此时变量应该增加来使L减小,因此减去一个负数 η ∂ L ( θ 0 ) ∂ θ \eta\frac{\partial L(\theta^0)}{\partial\theta} η∂θ∂L(θ0)
反复迭代得到 θ 2 , θ 3 , . . . \theta^2,\theta^3,... θ2,θ3,...
注:用上标0表示初始的一组参数,下表1和2表示初始的一组参数里面的两个组成(component)
二、一些细节
1. 调整学习率Learning Rate
- 学习率太小:速度会很慢,需要更多次的迭代来达到最小。
- 学习率太大:可能会错过最小点
在一维和二维情况下进行可视化展现,蓝色即学习率过小的情况,绿色即学习率过大的情况:
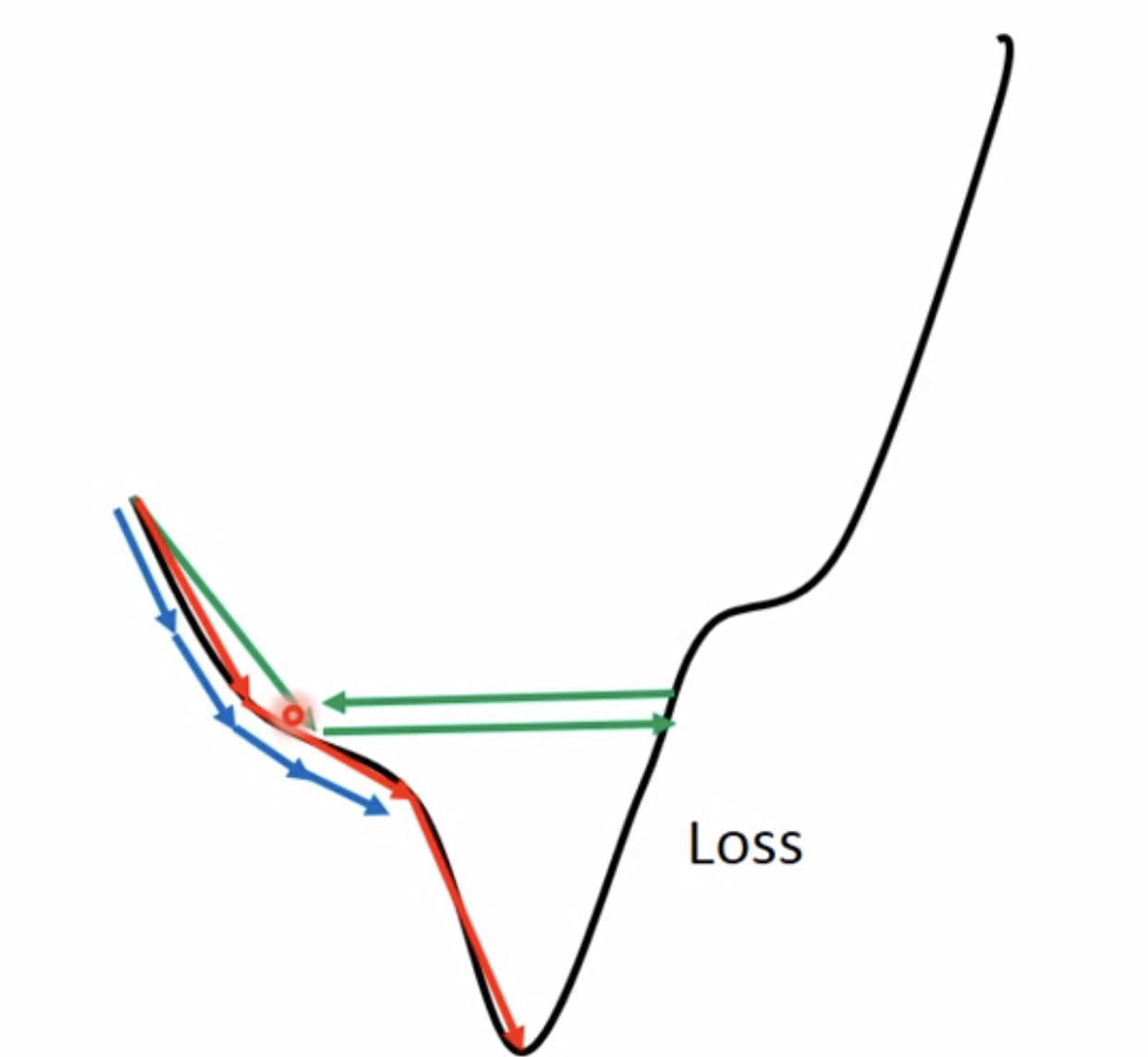
更多维的情况我们是通过对Loss Function的可视化进行观察:
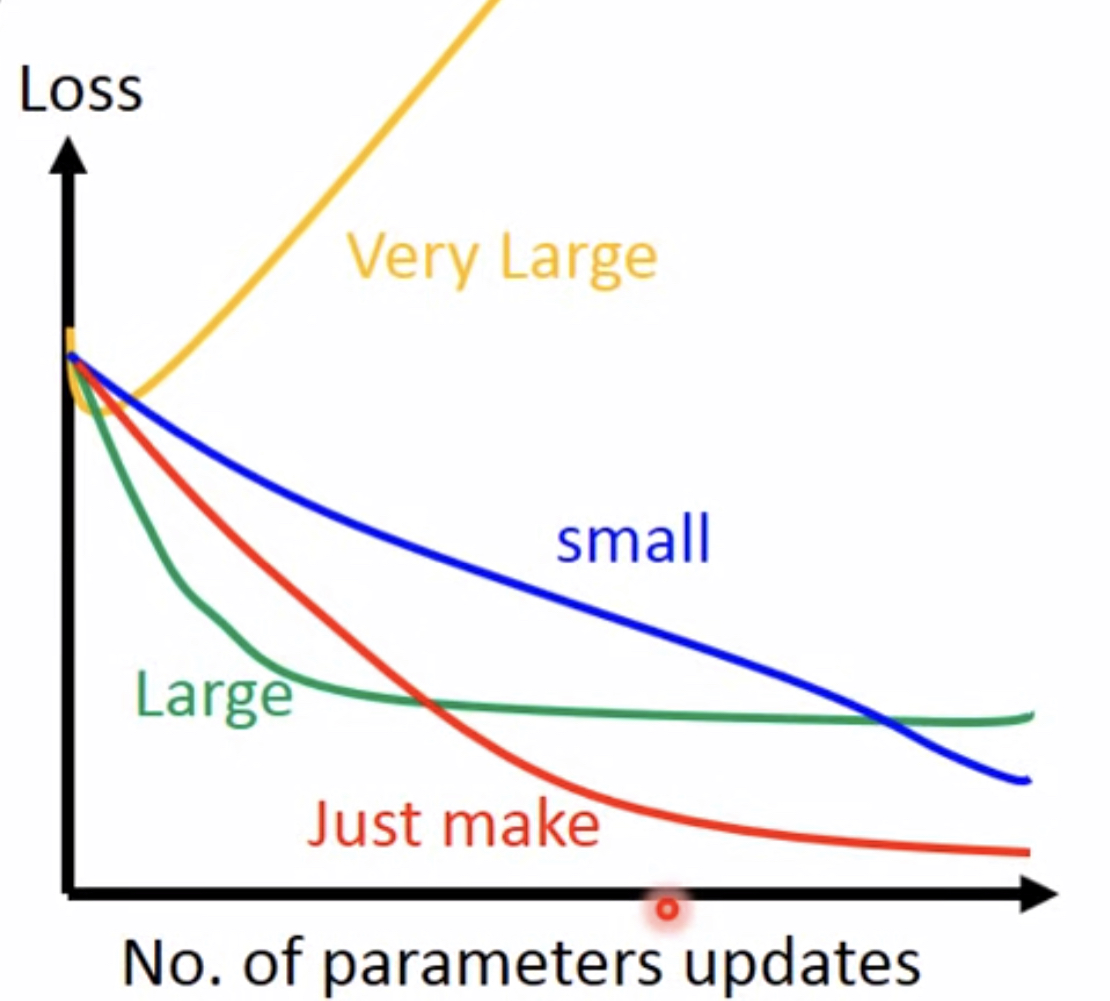
学习率的调参原则 :学习率随着参数更新越来越小(自适应adaptive)。因为刚开始的时候,离最优点通常是较远的,步伐可以大一点,经过多次迭代后会更加接近目标,所以应当减小学习率防止错过最低点。
● Adagrad自适应梯度算法
每一个参数的学习率都除以之前算出来的微分的均方根(RMS 将所有值平方求和, 求其均值, 再开平方)
- 普通梯度算法 w t + 1 ← w t − η t g t w^{t+1}\leftarrow w^t-\eta^tg^t wt+1←wt−ηtgt
- 自适应梯度算法 w t + 1 ← w t − η t σ t g t w^{t+1}\leftarrow w^t-\displaystyle{\frac{\eta^t}{\sigma^t}}g^t wt+1←wt−σtηtgt
σ t : \sigma^t: σt:过去所有的微分值相加求平均值,再开方。例如:
w 1 ← w 0 − η 0 σ 0 g 0 w^{1}\leftarrow w^0-\displaystyle{\frac{\eta^0}{\sigma^0}}g^0 w1←w0−σ0η0g0 σ 0 = ( g 0 ) 2 \sigma^0=\sqrt{(g^0)^2} σ0=(g0)2
w 2 ← w 1 − η 1 σ 1 g 1 w^{2}\leftarrow w^1-\displaystyle{\frac{\eta^1}{\sigma^1}}g^1 w2←w1−σ1η1g1 σ 1 = 1 2 [ ( g 0 ) 2 + ( g 1 ) 2 ] \sigma^1=\sqrt{\frac{1}{2}[(g^0)^2+(g^1)^2]} σ1=21[(g0)2+(g1)2]
.
.
.
.
.
.
......
......
w
t
+
1
←
w
t
−
η
t
σ
t
g
t
w^{t+1}\leftarrow w^t-\displaystyle{\frac{\eta^t}{\sigma^t}}g^t
wt+1←wt−σtηtgt
σ
t
=
1
t
+
1
∑
i
=
0
t
(
g
i
)
2
\sigma^t=\sqrt{\displaystyle{\frac{1}{t+1}}\sum\limits_{i=0}^t(g^i)^2}
σt=t+11i=0∑t(gi)2
而 η t = η t + 1 , \eta^t=\displaystyle{\frac{\eta}{\sqrt{t+1}}}, ηt=t+1η,
因此, w t + 1 ← w t − η ∑ i = 1 t ( g i ) 2 g t w^{t+1}\leftarrow w^t-\displaystyle{\frac{\eta}{\sqrt{\sum\limits_{i=1}^t(g^i)^2}}}g^t wt+1←wt−i=1∑t(gi)2ηgt
观察表达式可以看出,梯度下降的速度和两个因素有关,一个是学习率 η \eta η,在Adagrad中对其进行多一步的处理,另一个是梯度 g t g^t gt,而在此处出了一个矛盾 :之前一直说斜率/梯度越大,更新越快,而Adagrad中, g t g^t gt告诉我们微分值越大,参数更新得越快,而 η ∑ i = 1 t ( g i ) 2 \displaystyle{\frac{\eta}{\sqrt{\sum\limits_{i=1}^t(g^i)^2}}} i=1∑t(gi)2η 告诉我们微分值越大,更新速度反而小。
有些文章认为:Adagrad是想研究gradient有多反差:How surprise it is?考虑过去每一次的gradient,使之相除,造成反差的效果。
更正式的解释:Larger gradient, larger steps?
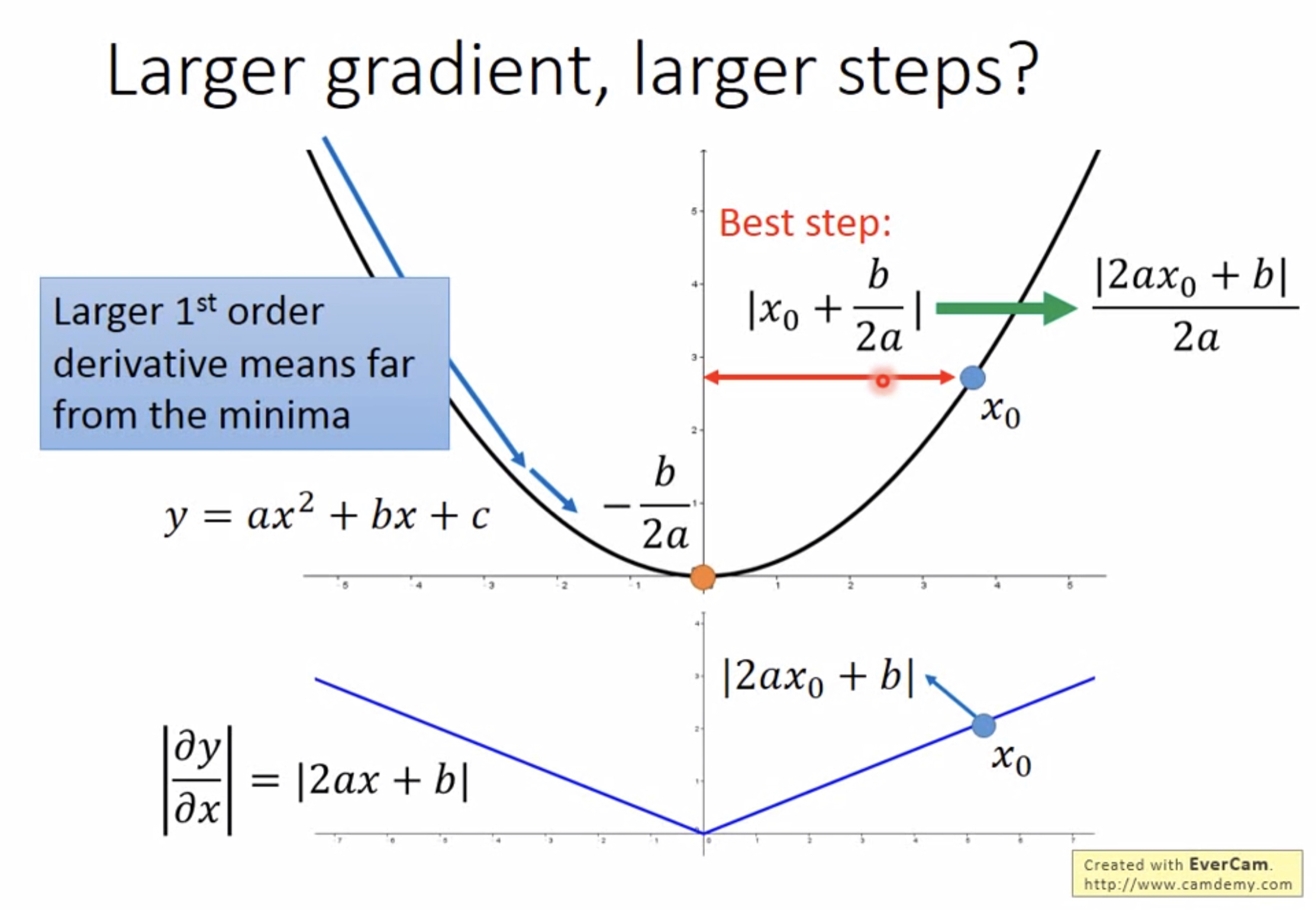
以二次函数为例,其最低点的横坐标是 − b 2 a -\frac{b}{2a} −2ab,任取一个 x 0 x_0 x0,多大的步长能使其到最低点呢? —— ∣ x 0 + b 2 a ∣ = ∣ 2 a x 0 + b ∣ 2 a |x_0+\frac{b}{2a}|=\frac{|2ax_0+b|}{2a} ∣x0+2ab∣=2a∣2ax0+b∣,分子刚好就是一阶导数,注意此处a是大于0的,若微分值越大,也就离最低点越远。 我们想要到达最低点,最好就选取 ∣ 2 a x 0 + b ∣ 2 a \frac{|2ax_0+b|}{2a} 2a∣2ax0+b∣为步长。
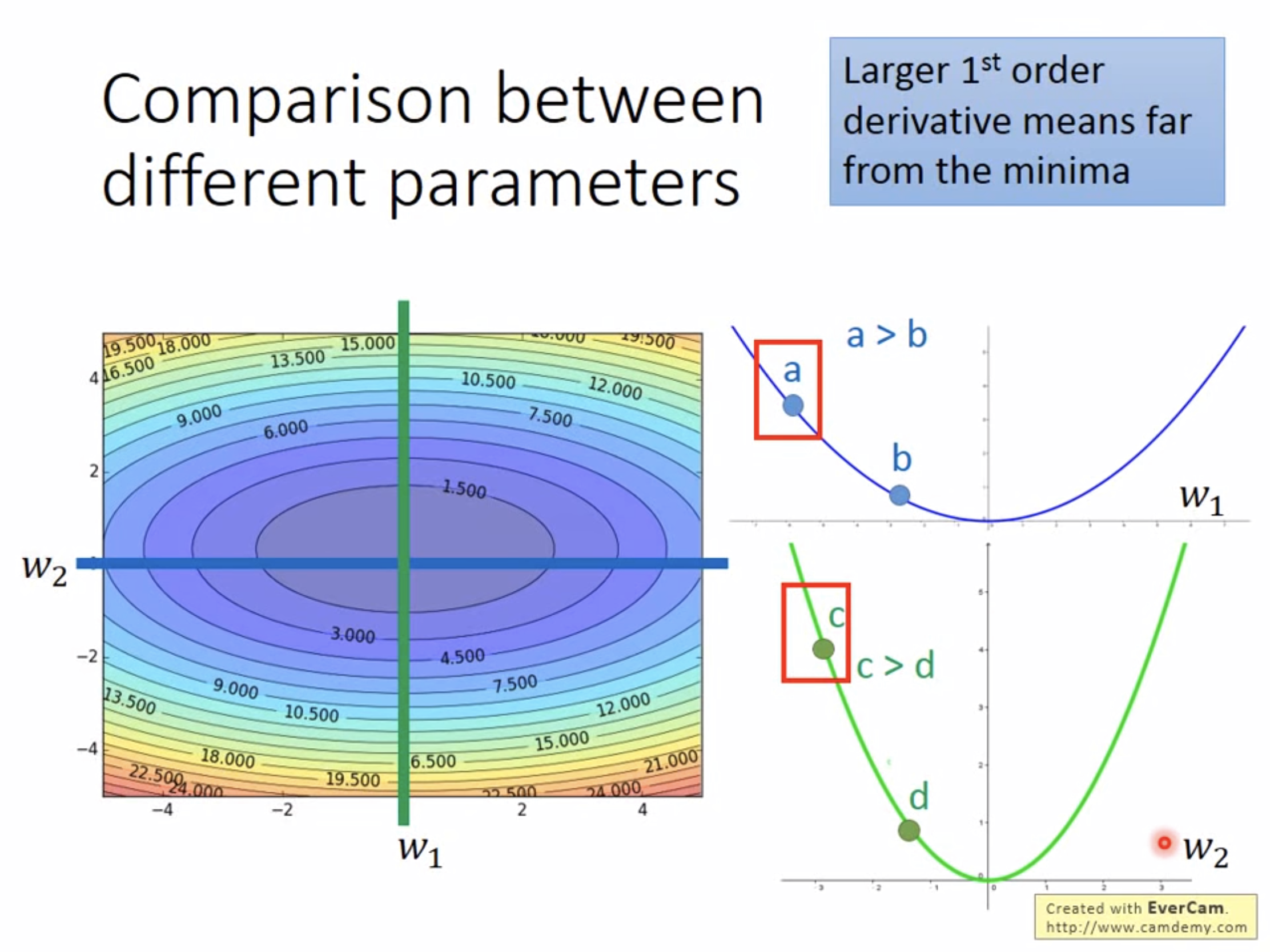
但是这只有在含一个参数的情况下成立,若有多个参数则不成立。以两个参数的情况为例:
只考虑
w
1
w_1
w1时,a的微分要大于b,a距离最低点也比b更远,这符合前面的描述;
只考虑
w
2
w_2
w2时,c的微分要大于d,c距离最低点也比d更远,这同样符合前面的描述;
但是跨参数比较时就不一定成立,例如a的微分值小于c,但是a可能离最低点更远。所以要进一步改进,这时考虑, ∣ 2 a x 0 + b ∣ 2 a \frac{|2ax_0+b|}{2a} 2a∣2ax0+b∣的分子其实就是二次函数的二阶导,应当将二次微分也考虑进来,最佳步长: 一 阶 偏 微 分 二 阶 偏 微 分 \frac{一阶偏微分}{二阶偏微分} 二阶偏微分一阶偏微分
再回到Adagrad的参数更新表达式 w t + 1 ← w t − η ∑ i = 1 t ( g i ) 2 g t w^{t+1}\leftarrow w^t-\displaystyle{\frac{\eta}{\sqrt{\sum\limits_{i=1}^t(g^i)^2}}}g^t wt+1←wt−i=1∑t(gi)2ηgt, η \eta η是个常量
g t ∑ i = 1 t ( g i ) 2 \displaystyle{\frac{g^t}{\sqrt{\sum\limits_{i=1}^t(g^i)^2}}} i=1∑t(gi)2gt 分子是一阶微分,分母不是二阶微分,但是事实上是二阶微分的近似,且这样使得计算量小,因为一阶微分是我们本来就需要计算的,现在用这种方式对二阶微分进行近似,不需要进行额外的计算。
2. 更快的参数更新速度
● SGD随机梯度下降法
- 普通梯度下降: L = ∑ n ( y ^ n − ( b + ∑ w i x i n ) ) 2 L=\sum\limits_n(\hat{y}^n-(b+\sum{w_ix^n_i}))^2 L=n∑(y^n−(b+∑wixin))2
- 随机梯度下降: L n = ( y ^ n − ( b + ∑ w i x i n ) ) 2 L^n=(\hat{y}^n-(b+\sum{w_ix^n_i}))^2 Ln=(y^n−(b+∑wixin))2
SGD是随机选取一个 x n x^n xn ,根据参数在该样本中的表现计算Loss,注意SGD的式子中,保留了第二个 ∑ \sum ∑,这是表示对样本 x n x^n xn的所有feature进行计算。
SGD每次根据一个数据进行计算并更新参数,而不是考察所有数据后再更新,这样使得SGD计算速度很快。
与SGD相对的是Batch GD 批量梯度下降,我们一般说的GD就是BGD,将二者进行对比:
| BGD | SGD | |
|---|---|---|
| 所用数据 | 每一次更新要用到所有数据 | 每次更新仅用一个数据 |
| 梯度方向 | 更准确的梯度计算方向 | 梯度下降准确性降低 |
| 收敛性 | 100%能找到全局最优 | 对于凸函数可能也只找到局部最优 |
| 训练时间 | 训练速度慢 | 训练速度很快 |
将二者结合即得到mini-Batch GD(小批量梯度下降),每次选取一定量的数据进行参数更新,相比BGD可以降低时间花费,相比SGD更加准确。
3. Feature Scaling特征归一化
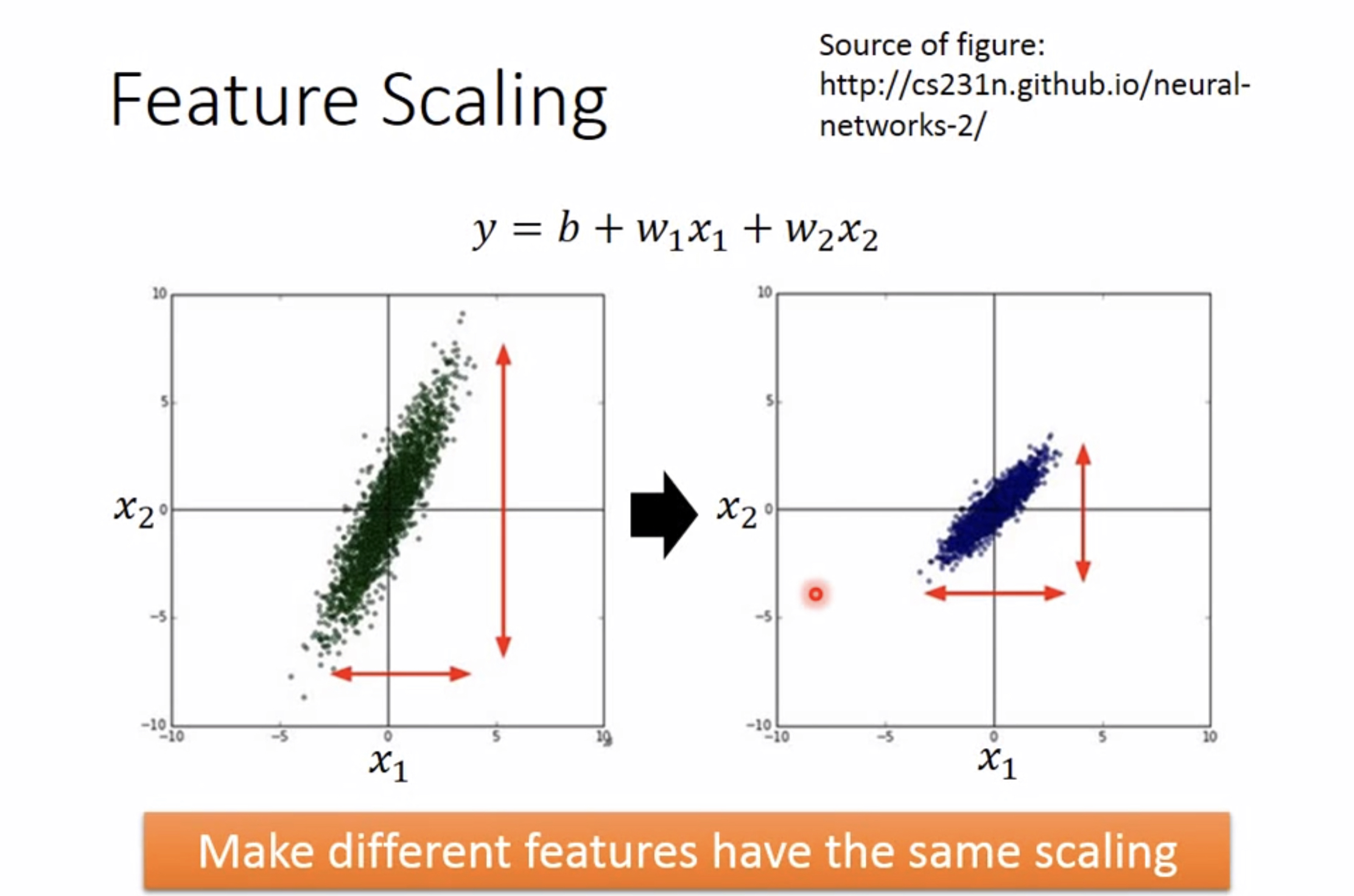
为什么?
- 特征间的单位(尺度)可能不同,比如身高和体重,比如摄氏度和华氏度,比如房屋面积和房间数,一个特征的变化范围可能是[1000,10000],另一个特征的变化范围可能是[−0.1,0.2],在进行距离有关的计算时,单位的不同会导致计算结果的不同,尺度大的特征会起决定性作用,而尺度小的特征其作用可能会被忽略,为了消除特征间单位和尺度差异的影响,以对每维特征同等看待,需要对特征进行归一化。
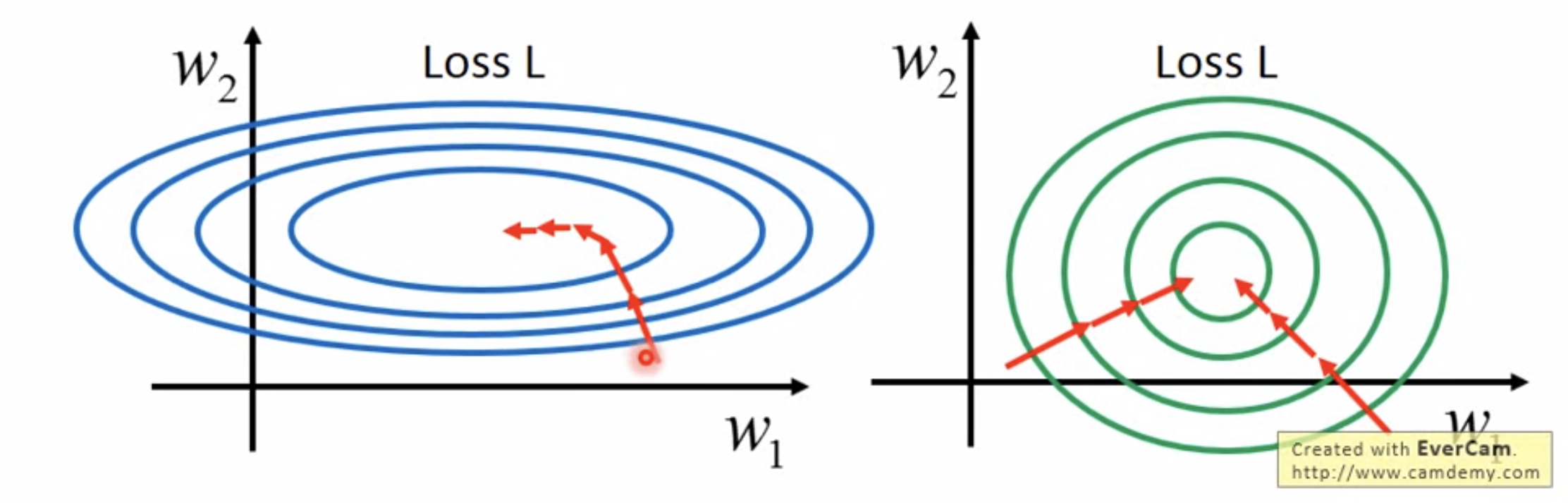
- 原始特征下,因尺度差异,其损失函数的等高线图可能是椭圆形,梯度方向垂直于等高线,下降会走zigzag路线,而不是指向local minimum。通过对特征进行zero-mean and unit-variance变换后,其损失函数的等高线图更接近圆形,梯度下降的方向震荡更小,收敛更快。
——来自为什么要归一化?
怎么做?
归一化方法有很多,最常用的是z-score法 和min-max法。
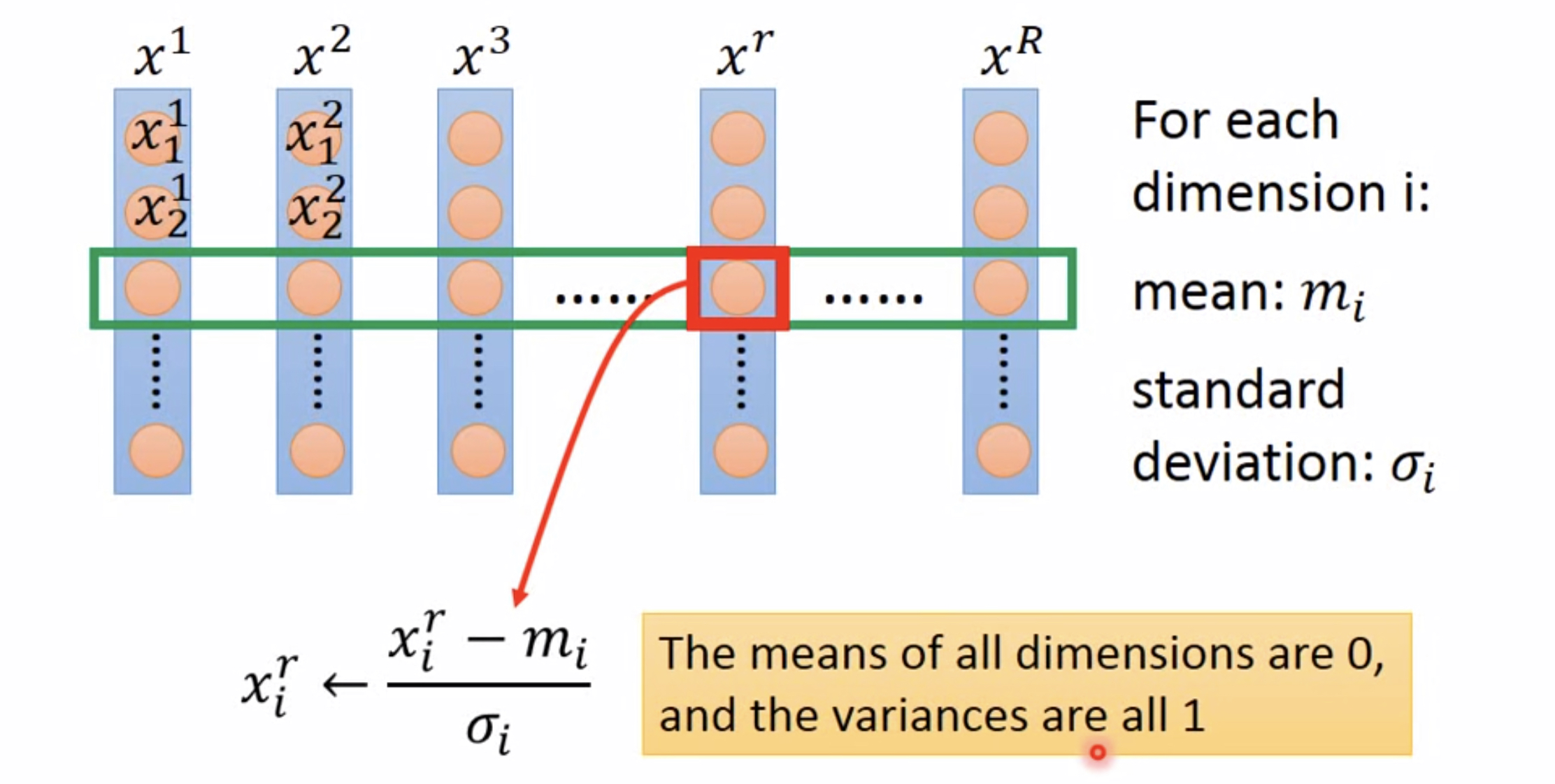
上图所示为z-score方法的思想,注意归一化是对每一个属性分别归一化,对于一个属性,计算其取值的出平均值和方差,归一化后的属性值为 x − μ σ \displaystyle\frac{x-\mu}{\sigma} σx−μ,在实际应用中,是否归一化会对结果产生较大的影响,一般我们都会在数据预处理阶段进行归一化操作。
三、梯度下降的局限性
对于非凸函数,并不一定能找到全局最优。

















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









