



 本文详细介绍了OpenMIPS架构中算术操作指令(加减乘除)、乘累加减指令的特性和实现思路,以及除法指令的复杂性。通过流水线设计和暂停机制探讨了如何优化多周期指令处理。
本文详细介绍了OpenMIPS架构中算术操作指令(加减乘除)、乘累加减指令的特性和实现思路,以及除法指令的复杂性。通过流水线设计和暂停机制探讨了如何优化多周期指令处理。
现MIPS32指令集架构定义的所有算术操作指令,共有21条,按照OpenMIPS实现这些指令的方式,可以分为三类,分别介绍如下。
(1)简单算术操作指令
共有15条,包括加法、减法、比较、乘法等指令,这些指令在流水线的执行阶段都只需要一个时钟周期,而且实现思路很直观,与第4章添加逻辑操作指令类似,只需修改译码阶段的ID模块、执行阶段的EX模块,即可实现。
(2)乘累加、乘累减指令
共有4条:乘累加(madd)、无符号乘累加(maddu)、乘累减(msub)、无符号乘累减(msubu)。其中madd、maddu要求操作数相乘后,再与HI、LO寄存器的值相加,msub、msubu指令要求操作数相乘后,再与HI、LO寄存器的值相减。也就是说,这四条指令都要做两次运算,一次乘法、一次加(减)法,如果将这两次运算放在流水线执行阶段的一个时钟周期中完成,那么会使流水线执行阶段所需要的时间明显增加,从而降低OpenMIPS工作时钟的频率,因此,OpenMIPS设计在流水线执行阶段使用两个时钟周期完成这类指令,一个时钟周期进行乘法,下一个时钟周期进行减(加)法。
(3)除法指令
共有两条:有符号除法(div)、无符号除法(divu)。OpenMIPS计划采用试商法完成除法运算,对于32位的除法,流水线执行阶段至少需要32个时钟周期。也就是说,除法指令需要多个时钟周期才能完成,所以单独作为一类。
7.1简单算术操作指令说明
1.add、addu、sub、subu、slt、sltu指令
这6条指令都是R类型指令,并且指令码都是6'b000000,即SPECIAL类。另外,第6~10bit都为0,需要依据指令中第0~5bit功能码的值进一步判断是哪一种指令。
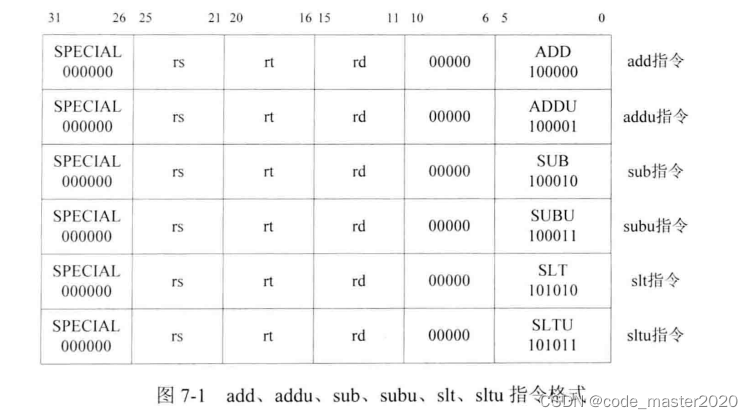
add和addu不同:add指令进行溢出检查,如果加法运算溢出,那么会产生溢出异常,同时不保存结果。而addu指令不进行溢出检查,总是将结果保存到目的寄存器。
sub和subu不同:类比add和addu。
--6'b101010 slt指令,比较运算
指令用法:slt rd , rs, rt
指令作用:rd <- (rs < rt),将地址为rs的通用寄存器的值与地址为rt的通用寄存器的值按照有符号数进行比较
--6'b101011 sltu指令,比较运算
指令用法 sltu rd, rs, rt
指令作用:按照无符号数进行比较
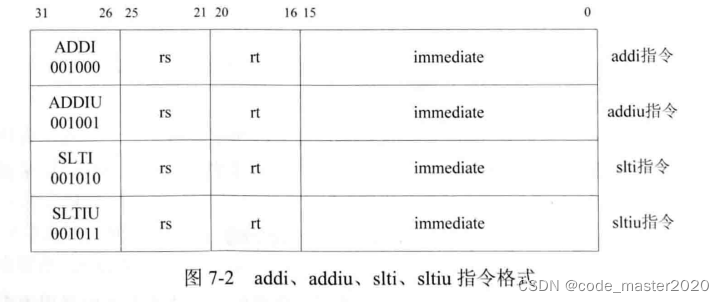
2.addi、addiu、slti、sltiu指令
 3.clo、clz指令
3.clo、clz指令
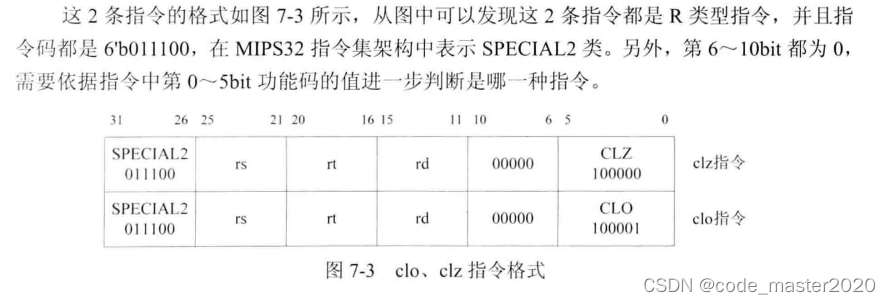 --6'b100000时,表示clz指令,计数运算
--6'b100000时,表示clz指令,计数运算
指令用法:clz rd, rs
指令作用:rd <- coun_leading_zeros rs,对地址为rs的通用寄存器的值,从其最高位开始向最低位方向检查,直到5遇到值为“1”的位,将该位之前“0”的个数保存到地址为rd的通用寄存器中,如果地址为rs的通用寄存器的所有位都是0,那么将32保存到地址为rd的通用寄存器中。
--6'b100001时,表示clo指令,计数运算
指令用法为:clo rd , rs
指令作用为:rd <- coun_leading_ones rs,对地址为rs的通用寄存器的值,从其最高位开始向最低位方向检查,直到5遇到值为“0”的位,将该位之前“1”的个数保存到地址为rd的通用寄存器中,如果地址为rs的通用寄存器的所有位都是1,那么将32保存到地址为rd的通用寄存器中。
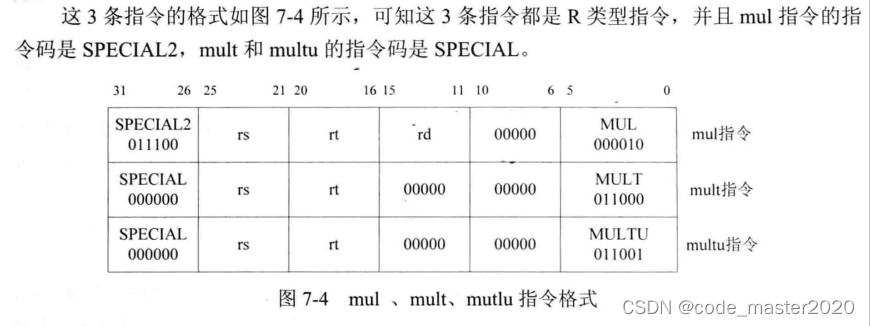
4.multu、mult、mul指令

7.2简单算术操作指令实现思路
(1)修改流水线译码阶段的ID模块,添加对上述简单算术操作指令的译码,给出运算类型alusel_o、运算子类型aluop_o、要写入的目的寄存器地址wd_o等信息;同时根据需要,读取地址为rs、rt的通用寄存器。
(2)修改流水线执行阶段的EX模块,根据传入的信息进行运算,得到运算结果,确定最终要写入目的寄存器的信息(包含:是否写、写入目的寄存器地址、写入的值),并将这些信息传递到访存阶段。
(3)上述信息会传递到回写阶段,最后修改目的寄存器。
7.3修改OpenMIPS以实现简单算术操作指令
7.3.1修改译码阶段的ID模块
在译码阶段要增加对简单算术操作指令的分析。
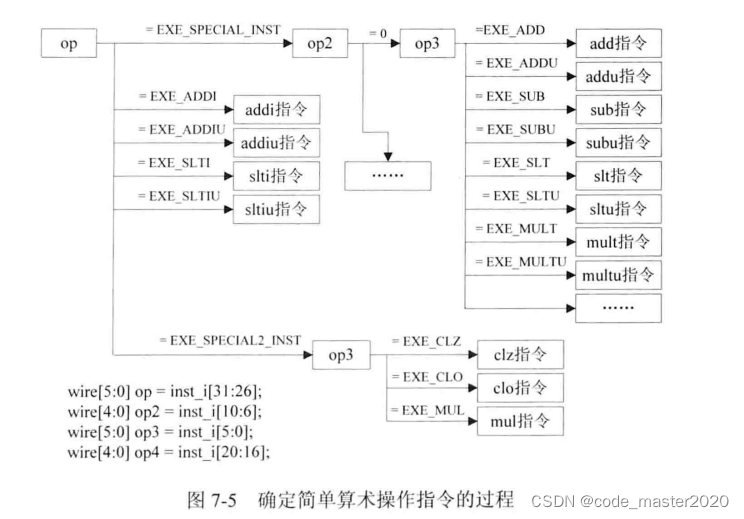
对任一条指令而言,译码工作的主要内容是:确定要读取的寄存器情况、要执行的运算、要写的目的寄存器等三个方面的信息。
1.add指令的译码过程
add指令译码需要设置的三方面内容如下(addu、sub、subu指令的译码过程可以参考add指令)
(1)要读取的寄存器情况:add指令需要读取rs、rt寄存器的值,所以设置reg1_read_o、reg2_read_o为1。默认通过Regfile模块读取端口1读取的寄存器地址reg1_addr_o的值是指令的第21~25bit,正是add指令中的rs,默认通过Regfile模块读取的寄存器地址reg2_addr_o的值是指令的第16~20bit,正是add指令中的rt所以最终译码阶段的输出reg1_o就是地址为rs的寄存器的值,reg2_o就是地址为rt的寄存器的值。
(2)要执行的运算:add指令时算术运算中的加法操作,所以此处将alusel_o赋值为EXE_RES_ARITHMETIC,aluop_o赋值为EXE_ADD_OP.
(3)要写入的目的寄存器:add指令需要将结果写入目的寄存器,所以设置wreg_o为WriteEnable, 设置wd_o为要写入的目的寄存器地址,默认是指令字的第11~15bit,正是add指令中的rd。
2.addi指令的译码过程
addi指令译码需要设置的三方面如下(addiu、subi、subiu指令的译码过程可以参考addi指令)。
(1)要读取的寄存器情况:addi指令只需要读取rs寄存器的值,所以设置reg1_read_o为1、reg2_read_o为0。默认通过Regfile模块读端口1读取的寄存器地址reg1_addr_o的值是指令的第21~25bit,正是addi指令中的rs。设置reg2_read_o为0表示使用立即数作为参与运算的第二个操作数、imm就是指令中的立即数进行符号扩展后的值。最终译码阶段的输出reg1_o就是地址为rs的寄存器的值,reg2_o就是imm的值。
(2)要执行的运算:addi指令是算术运算中的加法操作,所以此处将alusel_o赋值为EXE_RES_ARITHMETIC,aluop_o赋值为EXE_ADDI_OP。
(3)要写入的目的寄存器:addi指令需要将结果写入目的寄存器,所以设置wreg_o为WriteEnable, 设置要写入目的寄存器地址wd_o是指令中16~20bit的值,正是指令中的rt。
3.slt指令的译码过程
slt指令译码需要设置的三方面内容如下(sltu指令的译码过程可以参考slt指令)。
(1)要读取的寄存器情况:slt指令需要读取rs、rt寄存器的值,所以设置reg1_read_o、reg_read_o为1.默认通过Regfile模块读端口1读取的寄存器地址reg1_addr_o的值是指令的第21~25bit,正是slt中的rs,默认通过Regfile模块读端口2读取的寄存器地址reg2_read_o的值是指令的第16~20bit,正是slt指令中的rt。所以最终译码阶段的输出reg1_o就是地址为rs的寄存器的值,reg2_o就是地址为rt的寄存器的值。
(2)要执行的运算:slt指令时算术运算中的比较操作,所以将alusel_o赋值为EXE_RES_ARITHMETIC,aluop_p赋值为EXE_SLT_OP。
(3)要写入的目的寄存器:slt指令需要将结果写入目的寄存器,所以设置wreg_o为WriteEnable,设置wd_o为要写入的目的寄存器地址,默认是指令中第11~15bit的值,正是slt指令中的rd。
4.slti指令的译码过程(sltiu指令的译码过程可以参考slti指令)。
(1)要读取的寄存器情况:slti指令只需要读取rs寄存器的值,所以设置reg1_read_o为1、reg2_read_o为0。默认通过Regfile模块读端口1读取的寄存器地址reg1_addr_o的值是指令的第21~25bit,正是addi指令中的rs。设置reg2_read_o为0,表示使用立即数作为参与运算的第二个操作数、imm就是指令中的立即数进行符号扩展后的值。最终译码阶段的输出reg1_o就是地址为rs的寄存器的值,reg2_o就是imm的值。
(2)要执行的预算:slti指令是算术运算中的比较操作,所以将alusel_o赋值为EXE_RES_ARITHMETIC,aluop_o赋值为EXE_SLT_OP。
(3)要写入的目的寄存器:slti指令需要将结果写入目的寄存器,所以设置wreg_o为WriteEnable,设置要写入的目的寄存器地址wd_o是指令中第16~20bit的值,正是slti指令中的rt。
5.mult指令的译码过程(multu可参考)
(1)要读取的寄存器情况:mult指令需要读取rs、rt寄存器的值,所以设置reg1_read_o为1、reg2_read_o为1。默认通过Regfile模块读端口1读取的寄存器地址reg1_addr_o的值是指令的第21~25bit,正是slt中的rs,默认通过Regfile模块读端口2读取的寄存器地址reg2_read_o的值是指令的第16~20bit,正是slt指令中的rt。所以最终译码阶段的输出reg1_o就是地址为rs的寄存器的值,reg2_o就是地址为rt的寄存器的值
(2)要执行的运算:mult指令是乘法操作,并且乘法结果不需要写入通用寄存器,而是写入HI、LO寄存器,所以将aluel_o保持为默认值EXE_RES_NOP,aluop_o赋值为EXE_MULT_OP。
(3)要写入的目的寄存器:mult指令不需要写通用寄存器,所以设置wreg_o为1'b0.
6.mul指令的译码过程
(1)要读取的寄存器情况:mul指令需要读取rs、rt寄存器的值,所以设置reg1_read_o为1、reg2_read_o为1。默认通过Regfile模块读端口1读取的寄存器地址reg1_addr_o的值是指令的第21~25bit,正是slt中的rs,默认通过Regfile模块读端口2读取的寄存器地址reg2_read_o的值是指令的第16~20bit,正是slt指令中的rt。所以最终译码阶段的输出reg1_o就是地址为rs的寄存器的值,reg2_o就是地址为rt的寄存器的值
(2)要执行的运算:mul指令是乘法操作,并且乘法结果需要写入通用寄存器,所以将aluel_o赋值为EXE_RES_MUL,aluop_o赋值为EXE_MULT_OP。
(3)要写入的目的寄存器:mult指令需要写通用寄存器,所以设置wreg_o为1'b1.设置wd_o为要写入的目的寄存器地址,默认是指令字的第11~15bit,正是mul指令中的rd。
7.3.2修改执行阶段的EX模块
译码阶段的结果会传递到执行阶段,执行阶段的EX模块会据此进行运算,所以需要修改执行阶段EX模块的代码。
7.5流水线暂停机制的设计与实现
7.5.1流水线暂停机制的设计
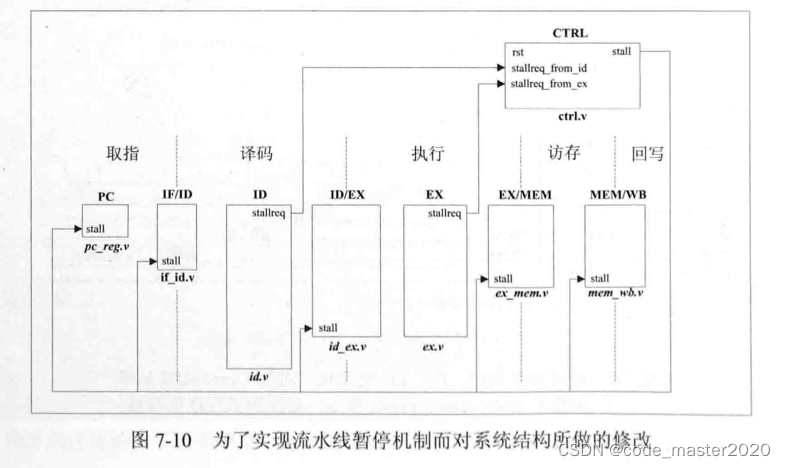
因为OpenMIPS设计乘累加、乘累减、除法指令在流水线执行阶段占用多个时钟周期,因此需要暂停流水线,以等待这些多周期指令执行完毕,一种直观的实现方法是:要暂停流水线,只需保持取指令地址PC的值不变,同时保持流水线各个阶段的寄存器(也就是IF/ID、ID/EX、EX/MEM、MEM/WB模块的输出)不变。
OpenMIPS采用的一种改进的方法:假如位于流水线第n阶段的指令需要多个时钟周期,进而请求流水线暂停,那么需保持取指令地址PC的值不变,同时保持流水线第n阶段、第n阶段之前的各个阶段的寄存器不变,而第n阶段后面的指令继续运行。比如:流水线执行阶段的指令请求流水线暂停,那么保持PC不变,同时保持取指、译码、执行阶段的寄存器不变,但是可以允许访存、回写阶段的指令继续运行。
为此,设计添加CTRL模块,其作用是接收各阶段传递过来的流水线暂停请求信号,从而控制流水线各阶段的运行。
为了实现流水线暂停机制,对系统结构做如图所示的修改。
CTRL模块的输入来自ID、EX模块的请求暂停信号stallreq,对于OpenMIPS教学版而言,只有译码、执行阶段可能会有暂停请求,取指、访存阶段都没有暂停请求,因为指令读取、数据存储器的读、写操作都可以在一个时钟周期内完成。
CTRL模块对暂停请求信号进行判断,然后输出流水线暂停信号stall。从图可知,stall输出到PC、IF/ID、ID/EX、EX/MEM、MEM/WB等模块,从而控制PC的值,以及流水线各个阶段的寄存器。
7.5.2流水线暂停机制的实现
1.CTRL模块的实现
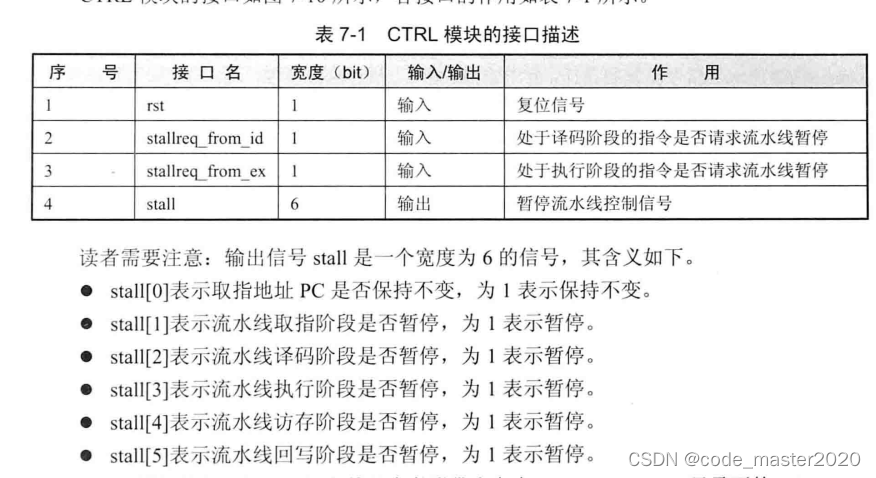
2.修改取指阶段
(1)修改PC模块
从上图可知,PC模块新增加了一个输入编号stall,其值就是CTRL模块的接口stall。
当stall[0] 为NoStop时,pc加4,否则,保持pc不变。
即pc = pc + 4'h4;
(2)修改IF/ID模块
--(1)当stall[1] 为Stop时,stall[2]为NoStop时,表明取指阶段暂停,而译码阶段继续,所以使用空指令作为下一个周期进入译码阶段的指令。
--(2)当stall[1]为NoStop时,取指阶段继续
--(3)其余情况下 ,保持译码阶段的寄存器id_pc、id_inst不变
3.修改译码阶段
(1)修改ID模块
(2)修改ID/EX模块
//(1)当stall[2]为Stop,stall[3]为NoStop时,表示译码阶段暂停,而执行阶段继续,所以使用空指令作为下一个周期进入执行阶段的指令。
//(2)(3)略
4.修改执行阶段
--(1)当stall[3] 为Stop时,stall[4]为NoStop时,表示执行阶段暂停,而访存阶段继续,所以使用空指令作为下一个周期进入访存阶段的指令
--(2)(3)略
5.修改访存阶段
--(1)当stall[4] 为Stop,stall[5]为NoStop时,表示访存阶段暂停,而回写阶段继续,所以使用空指针作为下一个周期进入回写阶段的指令
--(2)(3)略
6.修改顶层模块
7.6乘累加、乘累减指令说明
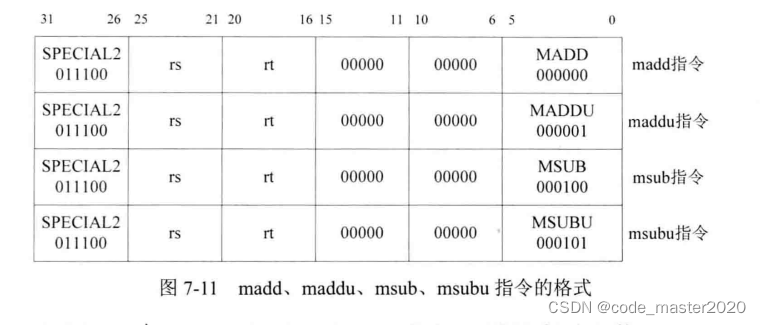


7.7乘累加、乘累减指令的实现思路
本章开始已经说明了乘累加、乘累减指令的实现思路,计划在流水线执行阶段采用两个时钟周期完成运算,第一个时钟周期进行乘法运算,第二个时钟周期将乘法结果与HI、LO寄存器进行jia/减法
7.10除法指令说明
除法指令有两条,包括: div/divu,各指令的格式如图。从图中可知这2条指令的指令码都是SPECIAL,第6~15bit都为0,可以依据第0~5bit的功能码确定是哪一种指令。
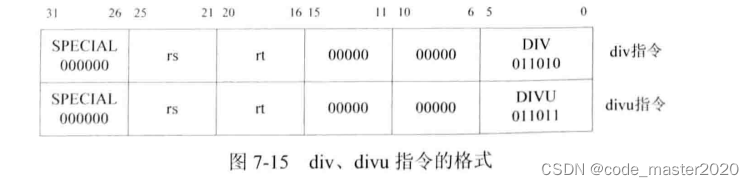
--6'b011010,div指令,有符号除法运算
指令用法为:div rs, rt。
指令作用为:{HI,LO} <- rs/rt,将地址为rs的通用寄存器的值,与地址为rt的通用寄存器的值,作为有符号数进行除法运算,将商保存到寄存器LO,余数保存到寄存器HI。
--6'b011011,divu指令,无符号除法运算
指令用法为:divu rs, rt。
指令作用为:{HI,LO} <- rs/rt,将地址为rs的通用寄存器的值,与地址为rt的通用寄存器的值,作为无符号数进行除法运算,将商保存到寄存器LO,余数保存到寄存器HI。
7.11除法指令实现思路
7.11.1试商法
OpenMIPS设计采用试商法实现除法运算,对于32位的除法,至少需要32个时钟周期才能得到除法结果。本节介绍试商法的一般过程。
设被除数是m,除数是n,商保存在s中,被除数的位数是k,其计算步骤如下(为了便于说明,在此将所有数据的最低位称为第1位,而不是第0位)
1.设被除数的最高位m[k],使用被除数的最高位减去除数n没如果结果大于0,则商的s[k]为1,反之为0
2.如果上一步得出的结果是0,表示当前的被减数小于除数,则取出被除数剩下的值的最高位m[k-1],与当前被减数组合作为下一轮的被除数;如果上一步得出的结果是1,表示当前的被减数大于除数,则利用上一步减法的结果与被除数剩下的值的最高位m[k-1]组合作为下一轮的被减数。然后,设置k等于k-1.
3.新的被减数减去除数,结果大于等于0,则商的s[k]为1,否则s[k]为0后面的步骤重复2-3,直到k等于1。

















 4363
4363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









