




 本文详细介绍了Python的urllib库,包括基本使用、下载、请求对象定制、GET与POST请求、URL编码方法以及如何处理Cookie。同时,还探讨了Handler处理器在设置代理和解析网页数据中的应用,以及XPath解析器在提取网页信息中的作用。此外,文章还涵盖了AJAX的GET请求和微博的Cookie登录实践。
本文详细介绍了Python的urllib库,包括基本使用、下载、请求对象定制、GET与POST请求、URL编码方法以及如何处理Cookie。同时,还探讨了Handler处理器在设置代理和解析网页数据中的应用,以及XPath解析器在提取网页信息中的作用。此外,文章还涵盖了AJAX的GET请求和微博的Cookie登录实践。
1.urllib的基本使用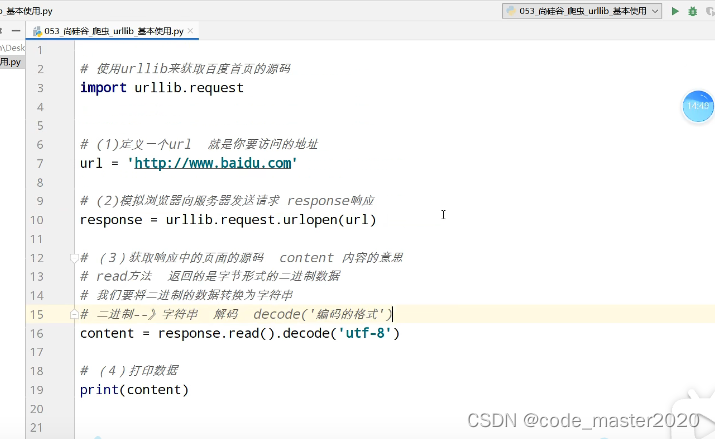
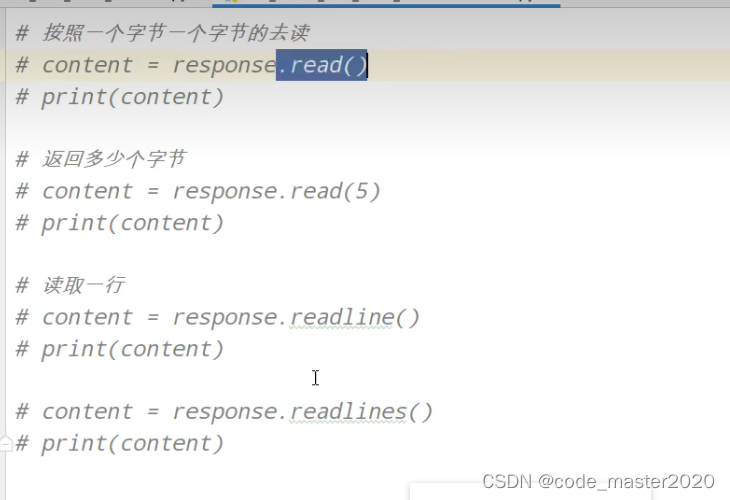
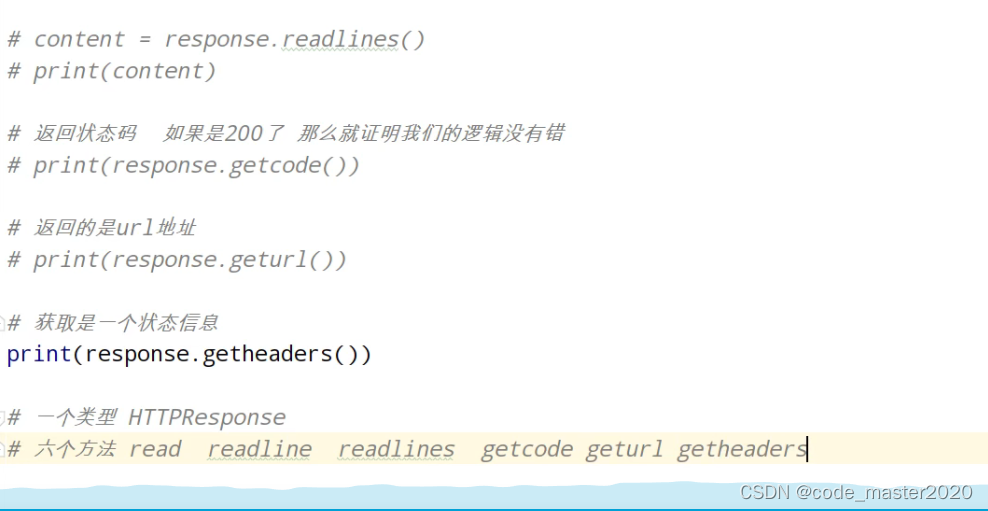
2.urllib——一个类型,六种方法
3.urllib——下载
4.urllib——请求对象的定制
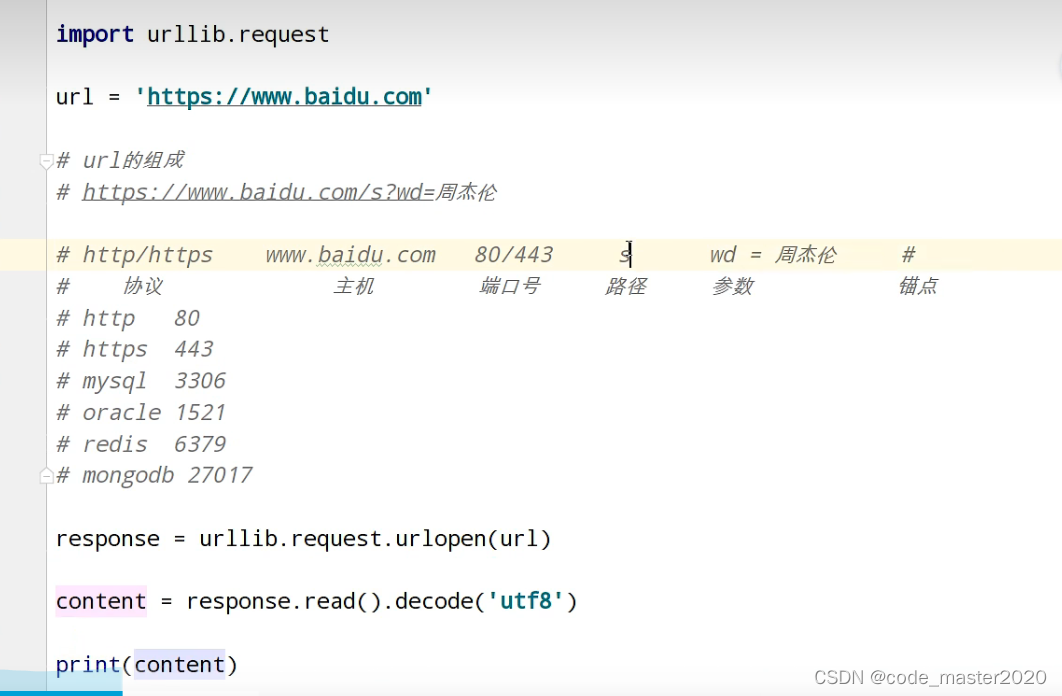
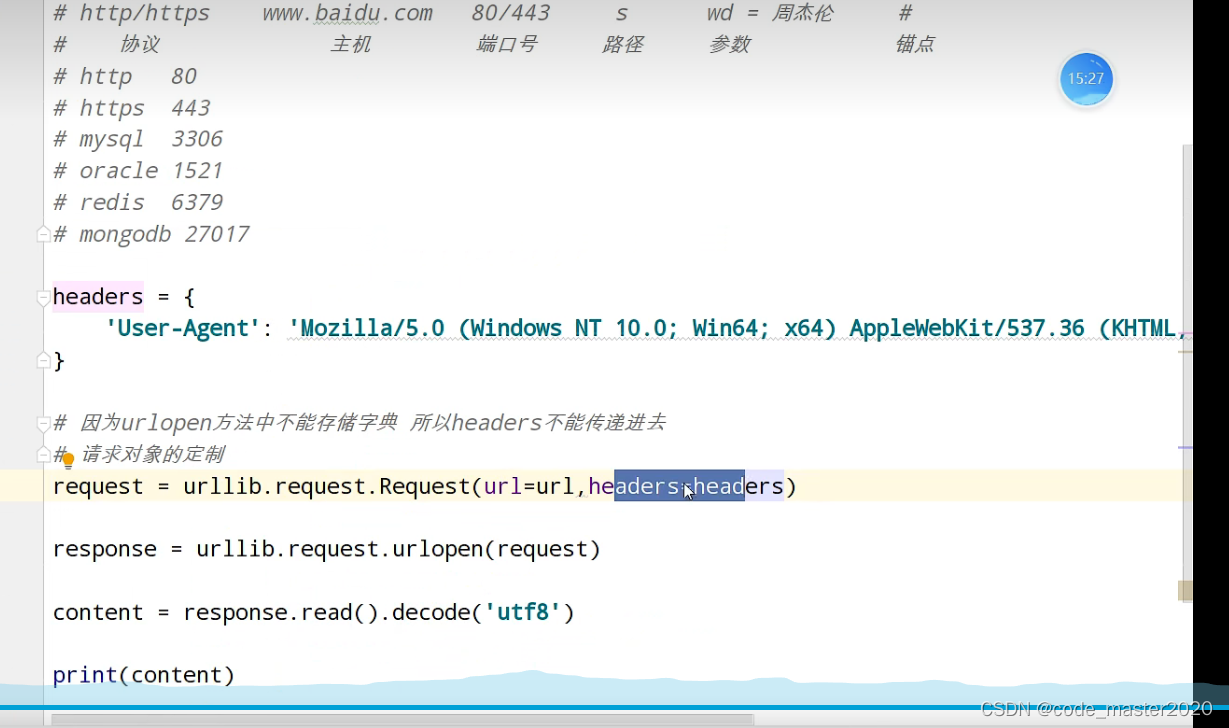
5.get请求的quote方法
将汉字变为对应的Unicode编码
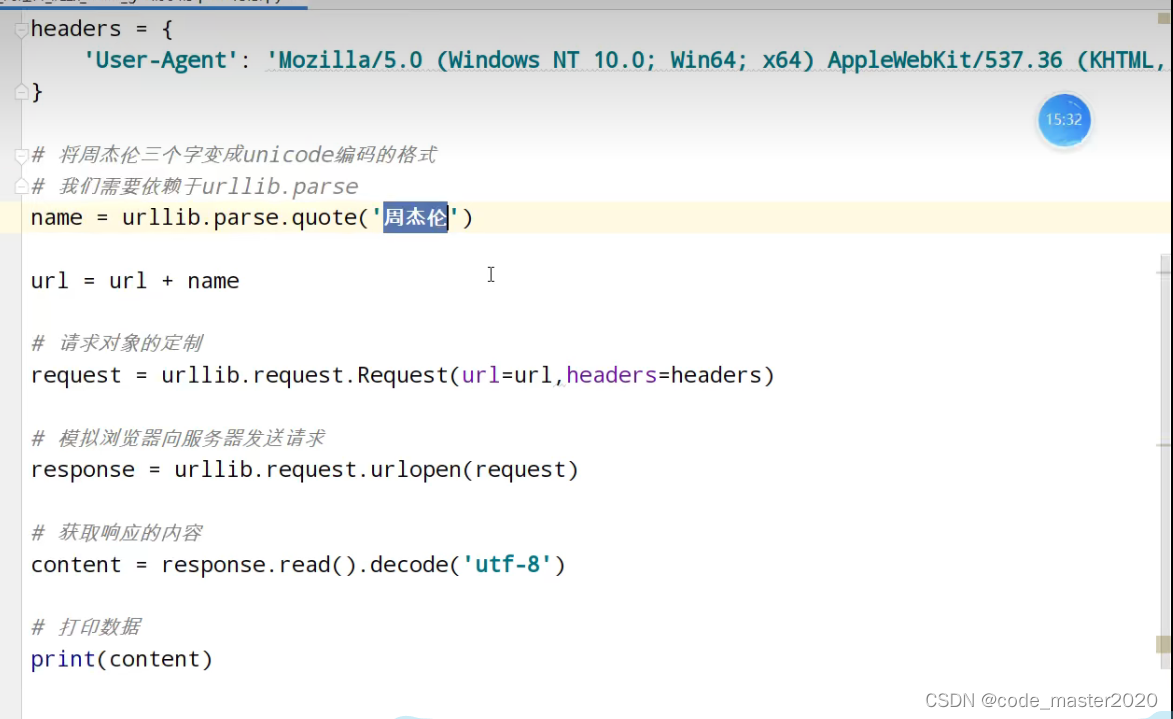
6.get请求的urlencode方法
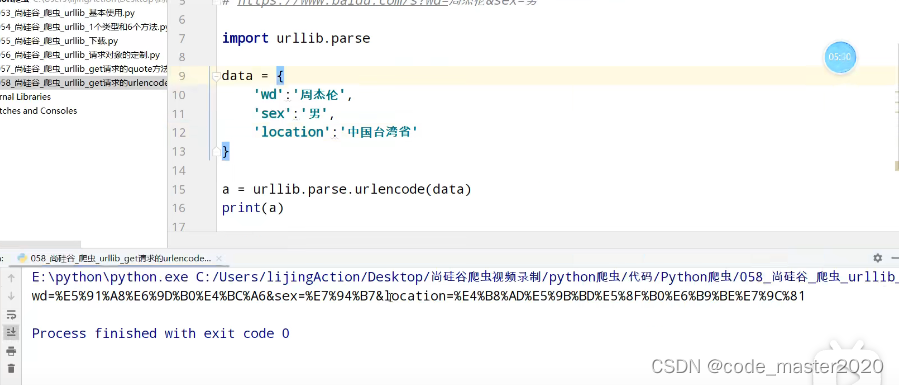
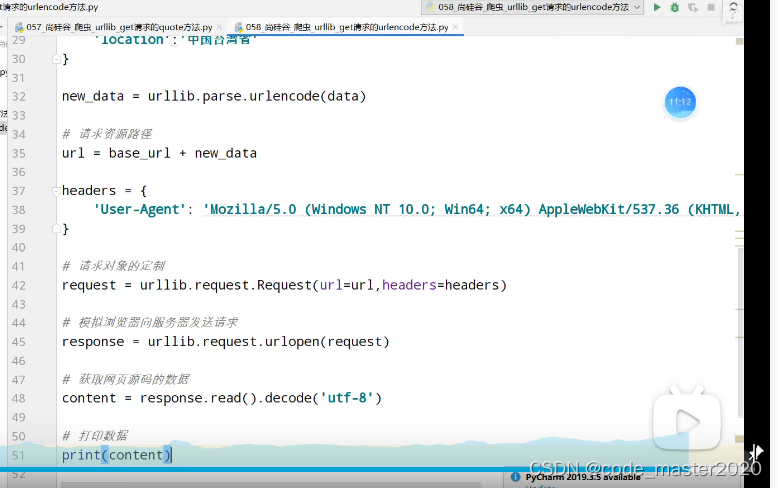
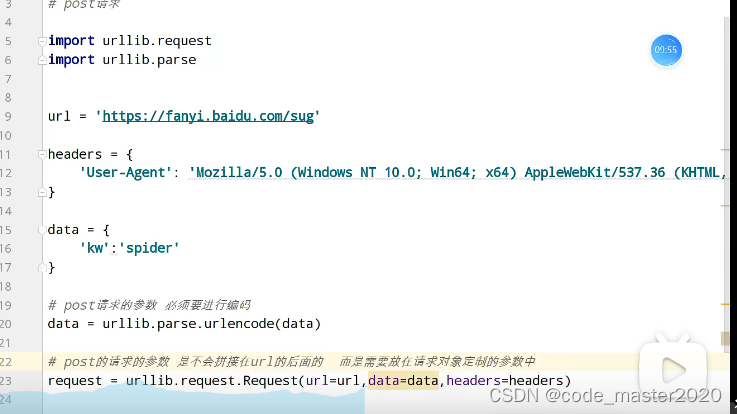
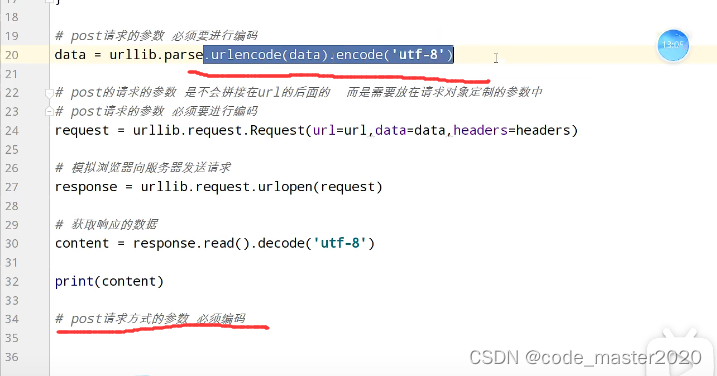
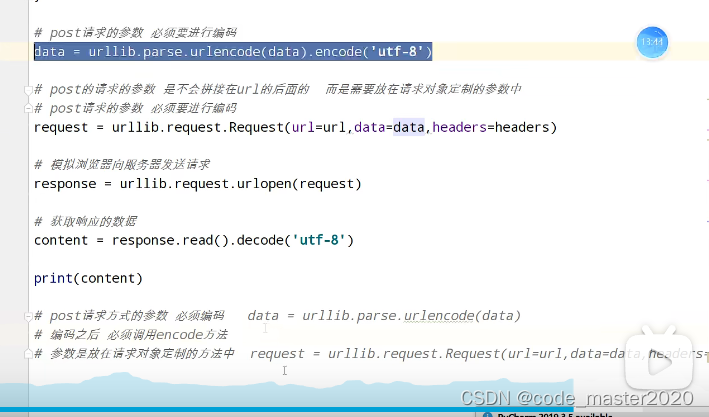
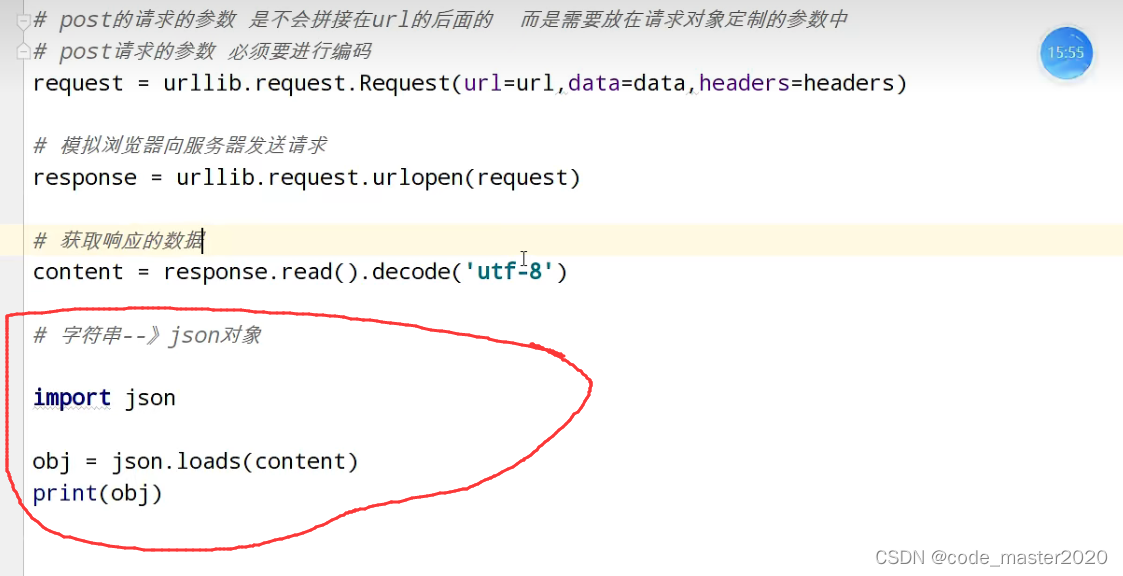
7.post请求方式

8.ajax的get请求豆瓣电影的第一页
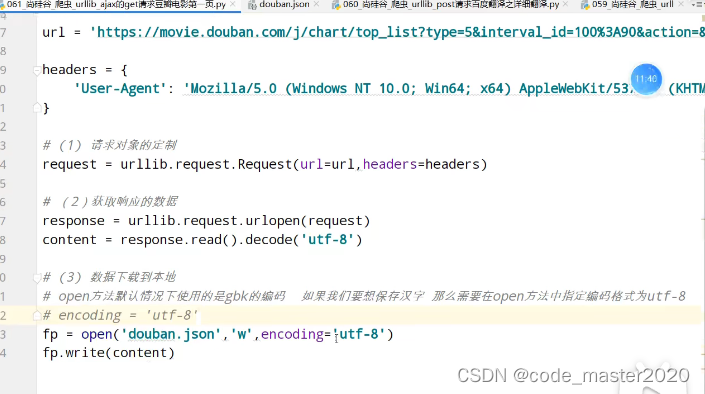
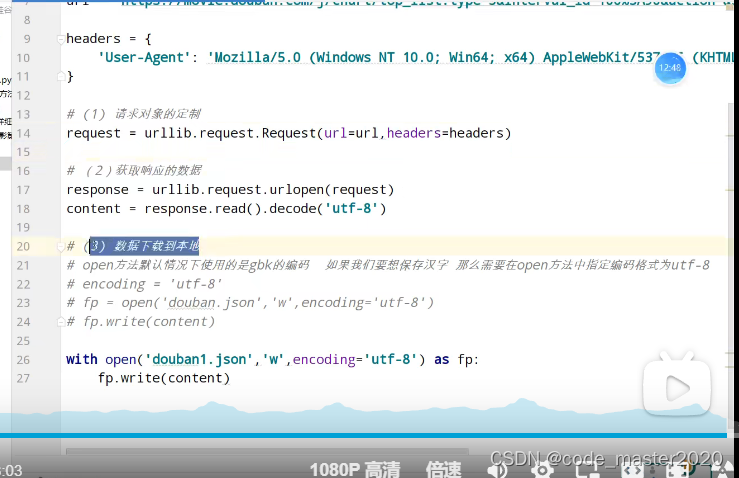
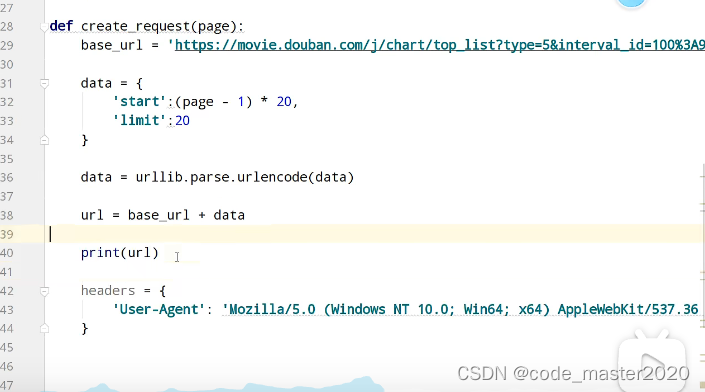
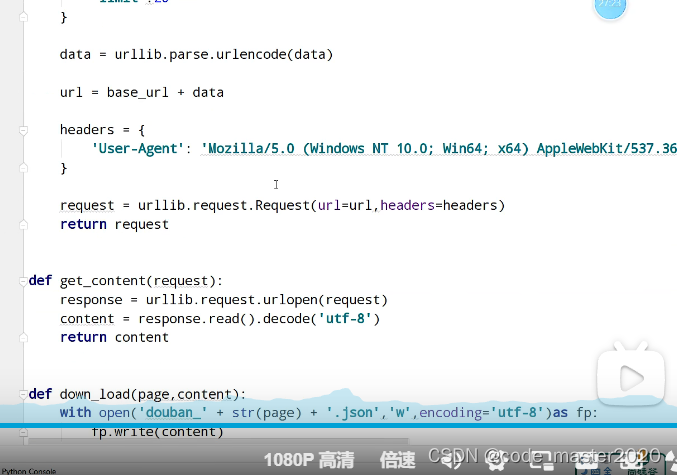
9.ajax的get请求豆瓣电影的前十页
10.微博的cookie登录
11.handler处理器的基本使用
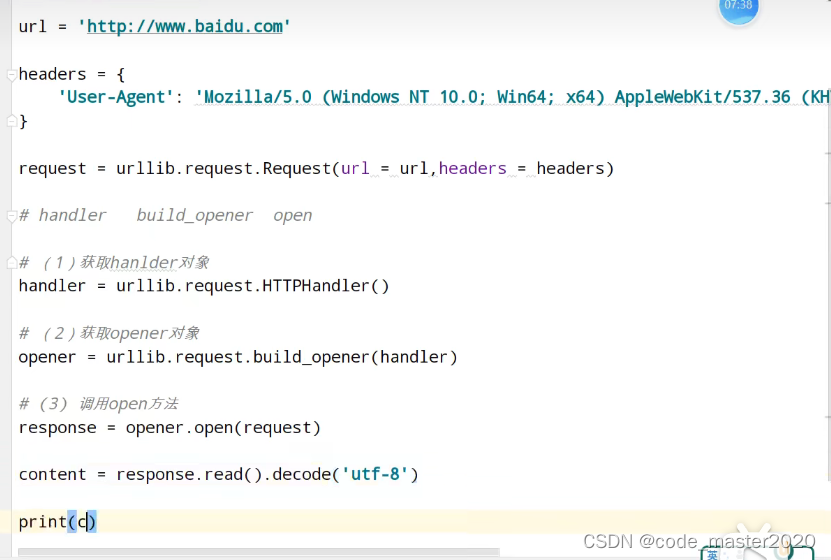
12.代理
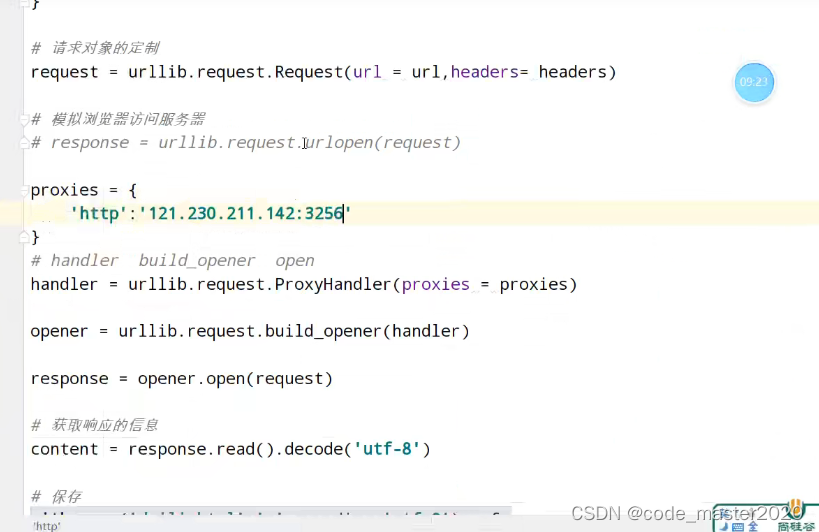
13.代理池
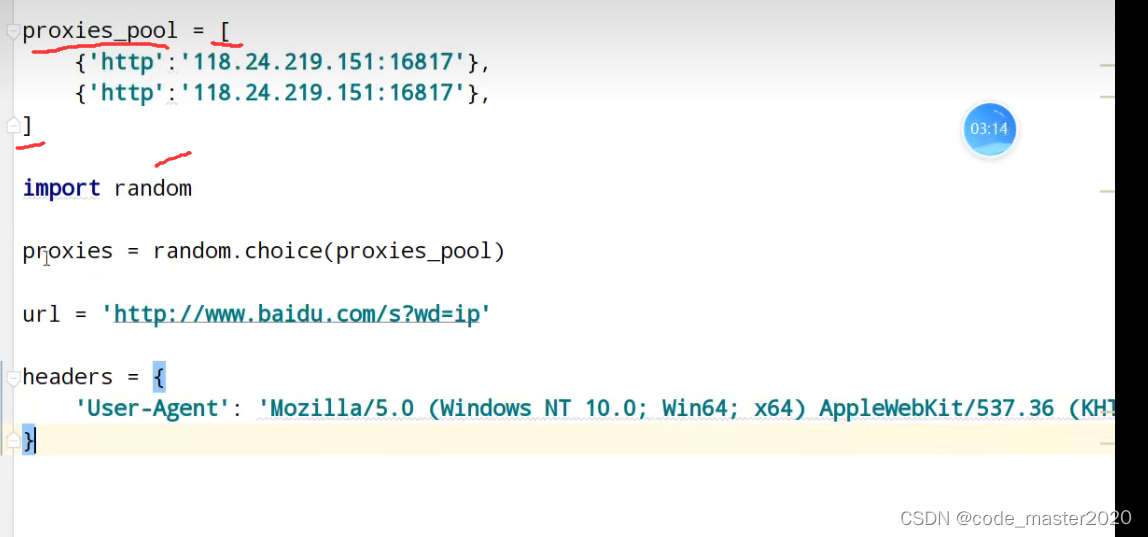
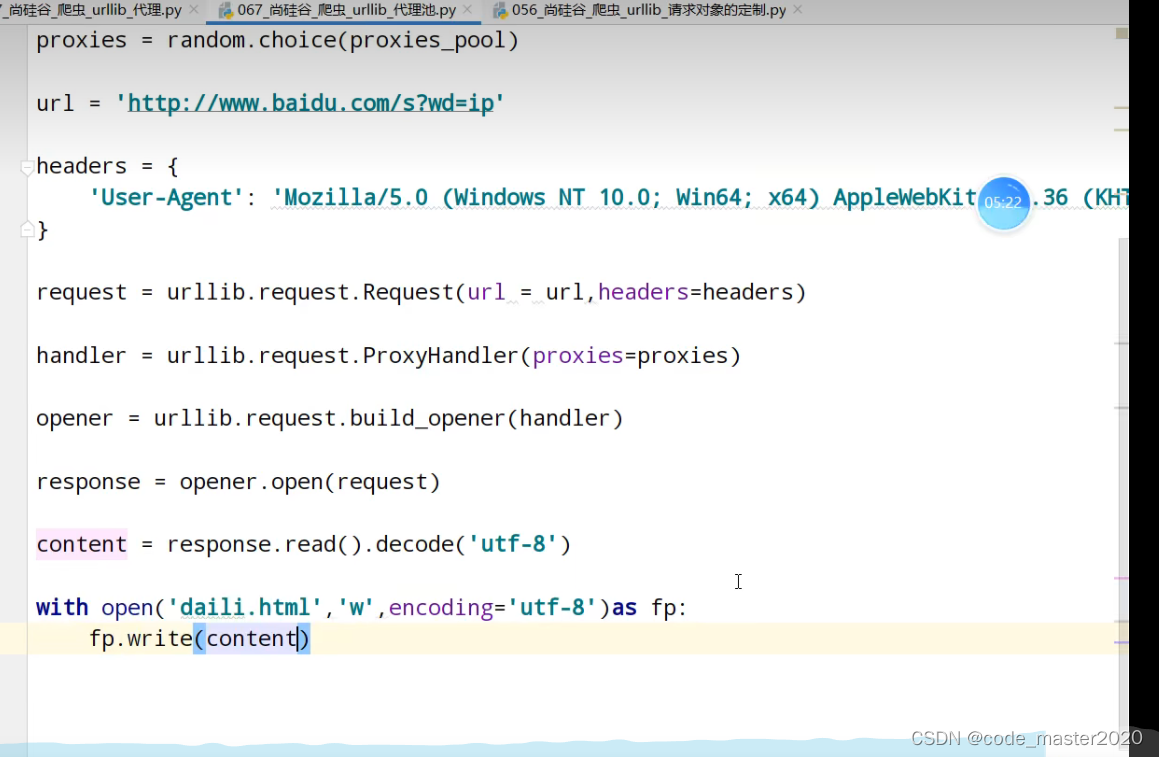
yong代理必须要用handler
14.解析_xpath插件的安装
帮助我们获取网页源码中部分数据的一种方式
15.解析_解析百度网站的百度一下

















 1497
1497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









