




 本文探讨了SpaceNet模型的调参过程及其在功能磁共振数据处理中的应用。作者对比了不同方法的准确率,并提出了针对3D数据转换到2D数据的问题解决方案。此外,文章还介绍了如何通过调整参数提高模型准确率。
本文探讨了SpaceNet模型的调参过程及其在功能磁共振数据处理中的应用。作者对比了不同方法的准确率,并提出了针对3D数据转换到2D数据的问题解决方案。此外,文章还介绍了如何通过调整参数提高模型准确率。
前面对SpaceNet进行调参,发现最高才89%,我的直觉告诉我还是低了点,为了证明,我决定调用常规的方法,如svm,logistics等,来验证这个分数。
上一个章节对SpaceNet进行cv=10的操作,准确率是-89%和86%,再验证集是62.5%。
SpaceNet模型接受的数据是3D的数据,而scikitlearn是2D数据,所以需要降维,即使用nilearn的NiftiMasker函数,Nifti Masker,这个函数是用来把三维数据变成二维数据的,如下图:
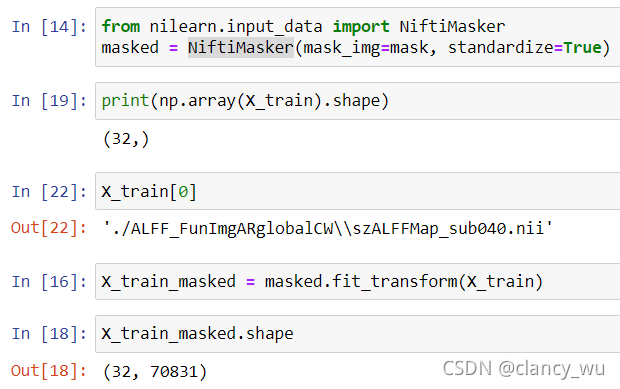
当然了,这个70831是用group mask屏蔽了brain bet之外的体素,值得注意的是,这个二维数组虽然可以用于scikitlearn,但是不能用于SpaceNet模型。
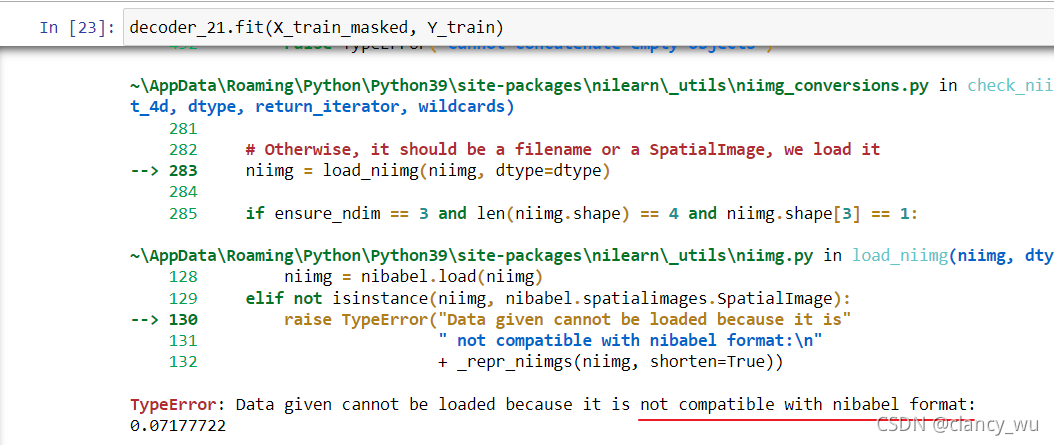
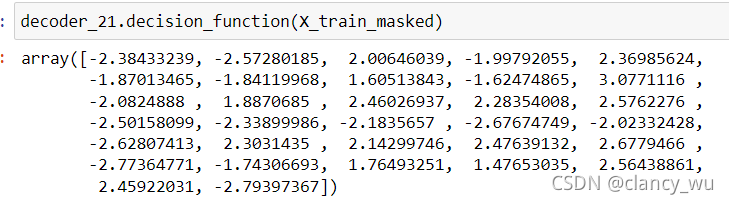
还有一点需要注意的是,SpaceNet本身是没有threshold的,但是没有这个就不能画AUC,其实是有办法的,就是SpaceNet有一个专门的函数是decision_function,它>0代表正类,它小于0代表负类,有了这个函数,就有了threshold,就可以画AUC了,很棒。这个是重点,记笔记。
那么SpaceNet的cv准确率只有89%和86%,test accuracy也只有62.5%,是不是数据就是这样子呢?下面就试试其他的model,需要注意的是,这里调用model以后,model有3个方法,fit、predict和transform。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1325
1325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











