



Selective Context:上下文压缩神器,突破 LLM 长文本处理瓶颈
在处理长文档和对话时,受限于上下文窗口的限制,大型语言模型(LLM)常面临性能下降和信息丢失的挑战。那么,如何能够在不更换大模型的情况下,又能够将更多的上下文信息传给大模型呢?今天就介绍一个很不错的 Prompt 压缩的项目——Selective_Context[1],通过压缩提示和上下文,使 LLMs 能够高效处理双倍内容,同时保持性能不下降。
Selective_Context 核心介绍

Selective Context 完成压缩的核心技术在于自信息测量。在信息论中,自信息衡量与一个事件相关的惊讶或不确定性水平;罕见事件传递更多信息,因此具有更高的自信息,而常见事件传递较少信息,自信息较低。在语言建模中,自信息可以用来评估词汇单元(如单词、短语或句子)的信息量。自信息较低的词汇单元信息量较少,更可能从上下文中推断出来,因此在 LLM 推理过程中,这些输入部分可以被视为冗余。
Selective Context 的实现分为三个关键步骤:首先,使用因果语言模型(如 GPT 、OPT 或 LLaMA)计算每个 token 的自信息;其次,将 token 及其对应的自信息值合并成词汇单元,这些可以是短语或句子;最后,消除被认为最不必要的内容,使输入更加紧凑。
Selective Context 技术已在 arXiv 论文、 BBC 新闻文章和对话记录等三个数据源上进行了评估,并在四个 NLP 任务(摘要、问答、原始上下文重建和对话)中表现出色。通过实际案例,我们可以看到 Selective Context 技术在 summarization 和 QA 等任务中的应用效果,显著提高了 LLMs 的输入效率和处理能力。它的实现思路给大家一个很大的启发,prompt 不一定越长越好,信息量才是关键,最近利用编程语言的方式编写 Prompt 获得了惊艳的效果,某种层面也是这一理论的很好佐证。
实际应用中,使用 Selective Context 非常简单。研究者们提供了一个名为 selective-context 的 Python 包,可以通过 pip 轻松安装。使用时,只需几行代码就可以压缩输入文本:
from selective_context import SelectiveContext
sc = SelectiveContext(model_type='gpt2', lang='en')
context, reduced_content = sc(text)
用户还可以根据需要调整压缩比例:
context, reduced_content = sc(text, reduce_ratio=0.5)
研究团队在 huggingface 上提供了测试的服务[2],感兴趣的朋友可以测试验证。
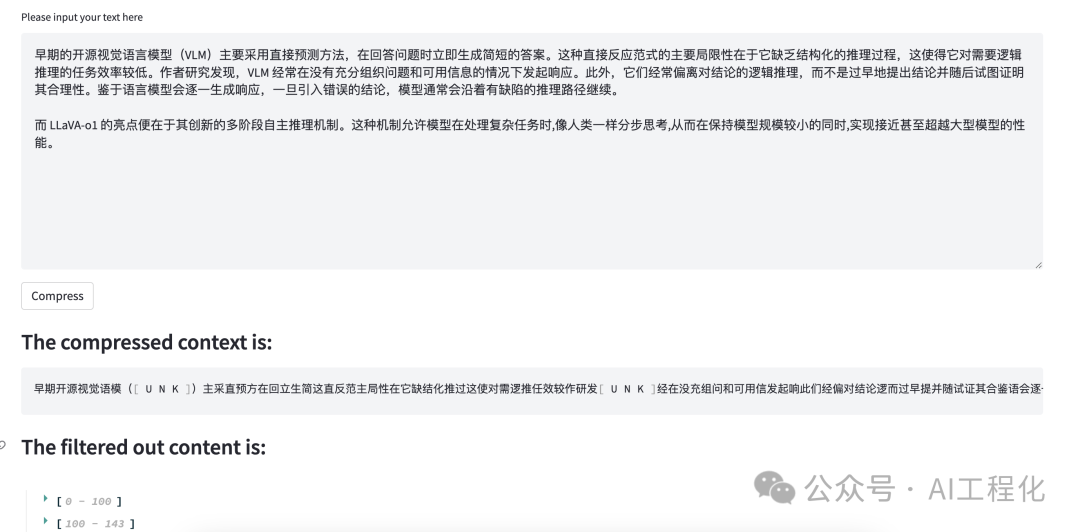
下面是笔者文章《LLaVA-o1:国产开源小型多模态AI模型获得超越GPT-4o-mini 大模型的性能》中的一段文字压缩后的结果,原文265,压缩后仅144,压缩效果明显:
小结
Selective Context 技术通过智能压缩,有效地解决了 LLMs 在处理长文档和对话时的性能瓶颈问题。它的出现为解决 LLMs 处理长文本的瓶颈提供了一种创新方案。需要指出的是如何在保留关键信息的同时最大化压缩效果是一个需要权衡的问题,另外,不同类型的文本可能需要不同的压缩策略,这要求算法具有更高的适应性。同时,在压缩过程本身的计算开销也需要考虑,可以预见,未来这一领域将会有更多更精细化的方案出现。
参考资料
[1]
Selective_Context: https://github.com/liyucheng09/Selective_Context/
[2]
服务: https://huggingface.co/spaces/liyucheng/selective_context

















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









