



Instructor:58种Prompt技术让 LLM输出更加结构化和可控
让 LLM 结构化输出,一直是个热点关注的问题。在之前介绍过一些库旨在解决这些问题,比如:Outlines:让LLM结构化输出可控,提升LLM应用的稳定性
Instructor[1] 也是目标解决这个问题的 Python 库,并且更进一步,以简单而强大的方式来定义、验证和控制 AI 输出的结构,可直接返回可操作的的 pydantic 对象,Instructor 提它支持 OpenAI、Anthropic、Cohere 等多种主流 LLM 提供商,极大地简化了开发者与 AI 交互的工作流程。
核心功能包括:
-
使用 Pydantic 模型精确定义输出结构
-
自动响应验证和重试机制
-
支持流式响应处理
-
提供灵活的多后端集成
通过简单的代码示例,开发者可以快速实现结构化输出:
import instructor
from pydantic import BaseModel
from openai import OpenAI
# Define your desired output structure
class UserInfo(BaseModel):
name: str
age: int
# Patch the OpenAI client
client = instructor.from_openai(OpenAI())
# Extract structured data from natural language
user_info = client.chat.completions.create(
model="gpt-4o-mini",
response_model=UserInfo,
messages=[{"role": "user", "content": "John Doe is 30 years old."}],
)
print(user_info.name)
#> John Doe
print(user_info.age)
#> 30
在实现上,instructor 针对于不同的 LLM 编写了依赖 json 进行格式化的实现。
mode_handlers = { # type: ignore
Mode.FUNCTIONS: handle_functions,
Mode.TOOLS_STRICT: handle_tools_strict,
Mode.TOOLS: handle_tools,
Mode.MISTRAL_TOOLS: handle_mistral_tools,
Mode.JSON_O1: handle_json_o1,
Mode.JSON: lambda rm, nk: handle_json_modes(rm, nk, Mode.JSON), # type: ignore
Mode.MD_JSON: lambda rm, nk: handle_json_modes(rm, nk, Mode.MD_JSON), # type: ignore
Mode.JSON_SCHEMA: lambda rm, nk: handle_json_modes(rm, nk, Mode.JSON_SCHEMA), # type: ignore
Mode.ANTHROPIC_TOOLS: handle_anthropic_tools,
Mode.ANTHROPIC_JSON: handle_anthropic_json,
Mode.COHERE_JSON_SCHEMA: handle_cohere_json_schema,
Mode.COHERE_TOOLS: handle_cohere_tools,
Mode.GEMINI_JSON: handle_gemini_json,
Mode.GEMINI_TOOLS: handle_gemini_tools,
Mode.VERTEXAI_TOOLS: handle_vertexai_tools,
Mode.VERTEXAI_JSON: handle_vertexai_json,
Mode.CEREBRAS_JSON: handle_cerebras_json,
Mode.CEREBRAS_TOOLS: handle_cerebras_tools,
Mode.FIREWORKS_JSON: handle_fireworks_json,
Mode.FIREWORKS_TOOLS: handle_fireworks_tools,
Mode.WRITER_TOOLS: handle_writer_tools,
}
具体的解析实现。
def handle_json_modes(
response_model: type[T], new_kwargs: dict[str, Any], mode: Mode
) -> tuple[type[T], dict[str, Any]]:
message = dedent(
f"""
As a genius expert, your task is to understand the content and provide
the parsed objects in json that match the following json_schema:\n
{json.dumps(response_model.model_json_schema(), indent=2, ensure_ascii=False)}
Make sure to return an instance of the JSON, not the schema itself
"""
)
if mode == Mode.JSON:
new_kwargs["response_format"] = {"type": "json_object"}
elif mode == Mode.JSON_SCHEMA:
new_kwargs["response_format"] = {
"type": "json_object",
"schema": response_model.model_json_schema(),
}
elif mode == Mode.MD_JSON:
new_kwargs["messages"].append(
{
"role": "user",
"content": "Return the correct JSON response within a ```json codeblock. not the JSON_SCHEMA",
},
)
new_kwargs["messages"] = merge_consecutive_messages(new_kwargs["messages"])
if new_kwargs["messages"][0]["role"] != "system":
new_kwargs["messages"].insert(
0,
{
"role": "system",
"content": message,
},
)
elif isinstance(new_kwargs["messages"][0]["content"], str):
new_kwargs["messages"][0]["content"] += f"\n\n{message}"
elif isinstance(new_kwargs["messages"][0]["content"], list):
new_kwargs["messages"][0]["content"][0]["text"] += f"\n\n{message}"
else:
raise ValueError(
"Invalid message format, must be a string or a list of messages"
)
return response_model, new_kwargs
可以看出,这种利用 LLM 解决 LLM 的问题的方式值得借鉴,这也是笔者介绍这个项目的目的。官方与 OpenAI、微软和谷歌的研究人员合作发布了名为《The Prompt Report: A Systematic Survey of Prompting Techniques[2]》的报告,该报告调研了超过 1500 篇有关Prompt技术论文,并将发现总结为 58 种不同的提示技术。他们将这些技术应用在 Instructor 这个项目中,形成了有关结构化 LLM 输出的Prompt 最佳实践[3],可以参考学习。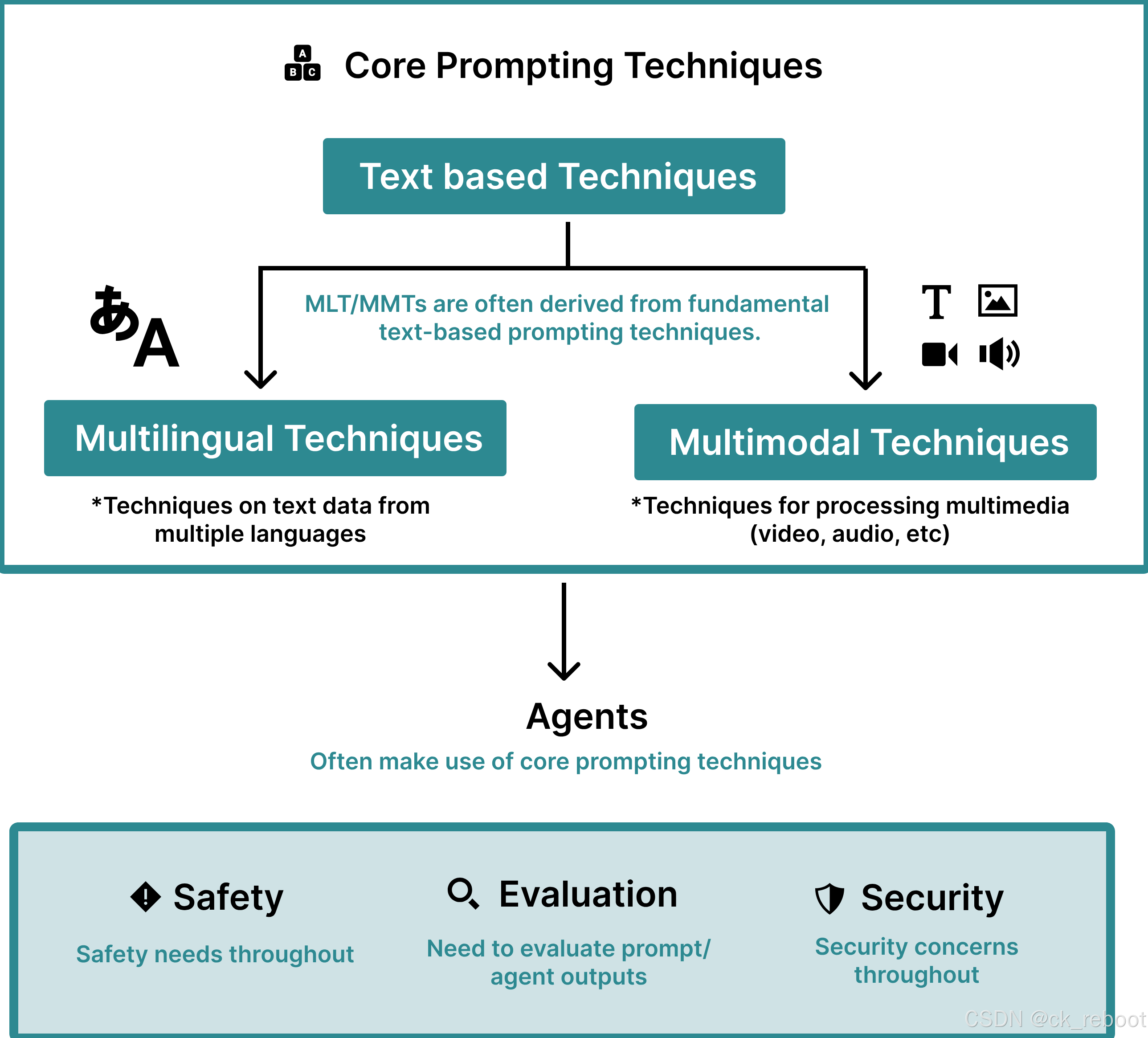
除此之外,Instructor 还提供了很多工程层面的改进和优化,并且支持多种语言,包括 Python、TypeScript、Ruby、Go 等。该项目获得了已获得 8.4k 收藏,每月60万下载,并持续在 GitHub 上活跃更新,感兴趣的开发者可以关注学习。
[1] Instructor: https://github.com/instructor-ai/instructor
[2] The Prompt Report: A Systematic Survey of Prompting Techniques: https://trigaten.github.io/Prompt_Survey_Site/
[3] Prompt 最佳实践: https://python.useinstructor.com/prompting/

















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









