




文章目录
- 1. 如何将一列的所有值转换为Pandas DataFrame中的列名
- 2. python判断文件夹是否存在并且删除/建立
- 3. pip下载时改源
- 4. scipy学习手册
- 5. python实现将excel文件转化成CSV格式
- 6. python中用pandas进行数据分析
- 7. python中将科学计数法表示的数值的字符串转换成数值型数据
- 8. python中不以科学计数法输出
- 9. AttributeError: module 'scipy.sparse' has no attribute 'csgraph'
- 10. python统计字符串中汉字个数
- 11. pandas一列拆成多列
- 12. 解决UnicodeDecodeError: 'ascii' codec can't decode byte 0xe9 in position 0: ordi和reload(sys)后print失效问题解决
- 13. anaconda2下安装python3
- 14. 使用pandas和pyodps的DataFrame对一列数字列表字符串进行求均值
1. 如何将一列的所有值转换为Pandas DataFrame中的列名
原来数据:
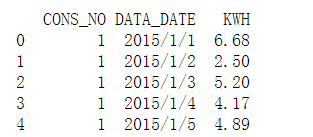
想要数据:

实现代码:
data = pd.read_csv('./data.csv', encoding='utf8') # (149185, 3)
data2 = data.reset_index().pivot('CONS_NO','DATA_DATE','KWH')
print(data2)
http://www.it1352.com/605624.html
2. python判断文件夹是否存在并且删除/建立
os.path.exists(path)
# 删除文件夹
import shutil
# 文件夹路径
shutil.rmtree(path)
#建立文件夹
os.makedirs('d:/assist/set')
https://www.jianshu.com/p/32b02c135fba
https://www.cnblogs.com/aaronthon/p/9509538.html
3. pip下载时改源
# -i 指定pip安装源
pip install numpy -i https://pypi.douban.com/simple
豆瓣源: https://pypi.douban.com/simple
清华源:https://pypi.tuna.tsinghua.edu.cn/simple
tuna源:https://pypi.tuna.tsinghua.edu.cn/simple
4. scipy学习手册
https://wizardforcel.gitbooks.io/scipy-lecture-notes/content/index.html
5. python实现将excel文件转化成CSV格式
import pandas as pd
data = pd.read_excel('123.xls','Sheet1',index_col=0)
data.to_csv('data.csv',encoding='utf-8')
https://blog.youkuaiyun.com/sharonITlion/article/details/78693660
6. python中用pandas进行数据分析
https://blog.youkuaiyun.com/liufang0001/article/details/77856255
https://blog.youkuaiyun.com/qq_42732026/article/details/82532886
https://blog.youkuaiyun.com/qq_43283527/article/details/82898490
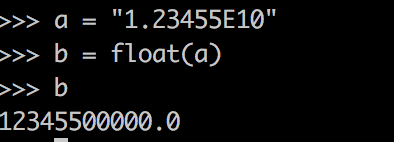
7. python中将科学计数法表示的数值的字符串转换成数值型数据
直接使用float
https://www.cnblogs.com/lucky-heng/p/9998099.html
8. python中不以科学计数法输出
import numpy as np
np.set_printoptions(suppress=True)
https://blog.youkuaiyun.com/Andrew_jdw/article/details/82350041
9. AttributeError: module ‘scipy.sparse’ has no attribute ‘csgraph’
from scipy.sparse.csgraph import connected_components
https://blog.youkuaiyun.com/mr_muli/article/details/84791047
10. python统计字符串中汉字个数
import string
def str_count(str):
'''找出字符串中的中英文、空格、数字、标点符号个数'''
count_en = count_dg = count_sp = count_zh = count_pu = 0
for s in str:
# 英文
if s in string.ascii_letters:
count_en += 1
# 数字
elif s.isdigit():
count_dg += 1
# 空格
elif s.isspace():
count_sp += 1
# 中文
elif s.isalpha():
count_zh += 1
# 特殊字符
else:
count_pu += 1
print('英文字符:', count_en)
print('数字:', count_dg)
print('空格:', count_sp)
print('中文:', count_zh)
print('特殊字符:', count_pu)
https://blog.youkuaiyun.com/xiamoyanyulrq/article/details/81504114
11. pandas一列拆成多列
# 数据拆分、拼接
new_names = ['gjj_pro_' + str(x + 1) for x in range(12)] # 为新生成的列取名
gjj_pro = gjj_pboc['YEAR_UNIT_DEPOSIT_PRO'].str.split('|', expand=True) # 将数据按‘|’拆分
gjj_pro.columns = new_names # 重命名新生成的列名
gjj_pboc = gjj_pboc.join(gjj_pro) # 数据合并
https://blog.youkuaiyun.com/opp003/article/details/105995386
12. 解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe9 in position 0: ordi和reload(sys)后print失效问题解决
import sys #这里只是一个对sys的引用,只能reload才能进行重新加载
stdi,stdo,stde=sys.stdin,sys.stdout,sys.stderr
reload(sys) #通过import引用进来时,setdefaultencoding函数在被系统调用后被删除了,所以必须reload一次
sys.stdin,sys.stdout,sys.stderr=stdi,stdo,stde
sys.setdefaultencoding('utf-8')
统一用上述方法,因为本来第一个问题可以直接通过reload(sys)解决的,但是会引起无法使用print,只能通过上述方法解决,原因如参考链接
https://www.cnblogs.com/huangbiquan/p/7812005.html
https://www.cnblogs.com/CasonChan/p/4669799.html
http://www.coin163.com/it/x969203250418110897/ascii-python-unicode
https://www.cnblogs.com/muchengnanfeng/p/9590404.html
13. anaconda2下安装python3
打开anaconda软件,新增python3的env,然后安装tensorflow,默认可能是1.10.0
如果要升级tensorflow可以使用下述命令
pip install -i https://pypi.douban.com/simple/ --upgrade tensorflow
14. 使用pandas和pyodps的DataFrame对一列数字列表字符串进行求均值
即进行列运算,内容是该列都是数字列表字符串,比如该列内容 ‘-0.11 1.23 -2.43’等等
需求是对该列的数字列表每个维度求均值,变成’-0.011 0.6 -0.46’这样的
第一种方法,使用pandas时
pd_df2 = pd_df['col'].str.split(' ',expand=True)
cols_len = pd_df2.shape[1]
new_col_names = ['col_' + str(x + 1) for x in range(cols_len)] # 为新⽣成的列取名
pd_df2.columns = new_col_names # 重命名新⽣成的列名
pd_df3 = pd_df2[new_col_names].astype('float')
list4 = pd_df3.mean().values
res_str = ' '.join(str(i) for i in list(list4))
print(res_str)
第二种方法,使用pyodps时
编写自定义的聚合函数
#参考Agg的例子,自定义,这个格式其实就是参考的pandas。。
#下面类中的函数名称不可以改变,类名自定义
class Agg(object):
def buffer(self):
#注意初始值的定义类型,可以自定为字典dict和列表list
return [0.0, 0]
def __call__(self, buffer, val):
#注意第一次初始值的累加,如果为dict类型,需要处理下第一次累加逻辑
buffer[0] += val
buffer[1] += 1
def merge(self, buffer, pbuffer):
#注意第一次初始值的合并,如果为dict类型,需要处理下第一次的合并逻辑
buffer[0] += pbuffer[0]
buffer[1] += pbuffer[1]
def getvalue(self, buffer):
if buffer[1] == 0:
return 0.0
return buffer[0] / buffer[1]
#注意下面的execute调用,不然返回的就是执行逻辑拓扑图,如果是jupyter notebook情况下才会自动执行结果
res = pd_fd.目标列名.agg(Agg).execute()
pyodps官方文档介绍的agg
阿里云odps调用UDAF时的详细原理介绍,和上面的agg十分类似
阿里云开发者社区的介绍pyodps的apply行处理和写表操作


















 4155
4155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









