






 这篇博客记录了一段Python代码,用于数据清洗,将原始数据中包含 '[', ']' 的字符串替换为空,通过split(',')进行列展开,并使用pandas的concat函数重组数据。该方法适用于频繁切换代码编辑环境的开发者,避免重复编写相同的数据预处理代码。
这篇博客记录了一段Python代码,用于数据清洗,将原始数据中包含 '[', ']' 的字符串替换为空,通过split(',')进行列展开,并使用pandas的concat函数重组数据。该方法适用于频繁切换代码编辑环境的开发者,避免重复编写相同的数据预处理代码。
这次完全是为了备注一个自己常用的代码,由于经常换写代码的终端,所以有些代码真的不想重写了,所以就在这里备注一下有关数据清洗的一些代码:
原始数据是
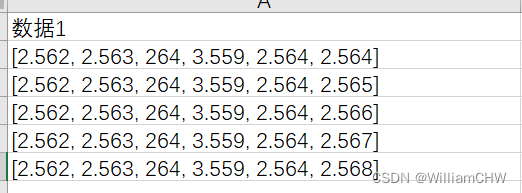
想要变成
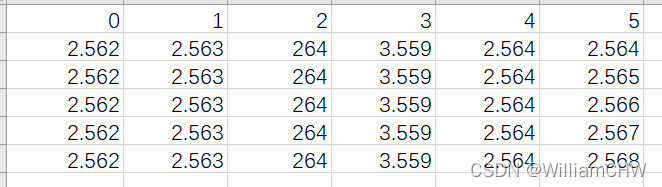
python 代码如下:
new_data = data_one.str.split(',',expand=True)
new_first = new_data.iloc[:,0].apply(lambda x: x.replace('[',''))
new_last = new_data.iloc[:,-1].apply(lambda x: x.replace(']',''))
all_new_voltage = pd.concat((new_first,new_data.iloc[:,1:-1],new_last),axis=1)

















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









