




 本文介绍了Negative Sampling模型的工作原理,包括如何通过带权采样选取负例样本,并结合CBOW模型详细阐述了如何通过最大化正例概率和最小化负例概率来训练词向量。
本文介绍了Negative Sampling模型的工作原理,包括如何通过带权采样选取负例样本,并结合CBOW模型详细阐述了如何通过最大化正例概率和最小化负例概率来训练词向量。
前面讲了Hierarchical softmax 模型,现在来说说Negative Sampling 模型的CBOW和Skip-gram的原理。它相对于Hierarchical softmax 模型来说,不再采用huffman树,这样可以大幅提高性能。
一、Negative Sampling
在负采样中,对于给定的词www,如何生成它的负采样集合NEG(w)NEG(w)NEG(w)呢?已知一个词www,它的上下文是context(w)context(w)context(w),那么词www就是一个正例,其他词就是一个负例。但是负例样本太多了,我们怎么去选取呢?在语料库C\mathcal{C}C中,各个词出现的频率是不一样的,我们采样的时候要求高频词选中的概率较大,而低频词选中的概率较小。这就是一个带权采样的问题。
设词典D\mathcal{D}D中的每一个词www对应线段的一个长度:
len(w)=counter(w)∑u∈Dcounter(u)(1)
len(w) = \frac{counter(w)}{\sum_{u \in \mathcal{D}}counter(u)} (1)
len(w)=∑u∈Dcounter(u)counter(w)(1)
式(1)分母是为了归一化,Word2Vec中的具体做法是:记l0=0,lk=∑j=1klen(wj),k=1,2,…,Nl_0 = 0, l_k = \sum_{j=1}^{k} len(w_j), k=1,2, \dots, Nl0=0,lk=∑j=1klen(wj),k=1,2,…,N,其中,wjw_jwj是词典D\mathcal{D}D中的第jjj个词,则以{lj}j=0N\{l_j\}_{j=0}^{N}{lj}j=0N为点构成了一个在区间[0,1]非等距离的划分。然后再加一个等距离划分,Word2Vec中选取M=108M=10^8M=108,将M个点等距离的分布在区间[0,1]上,这样就构成了M到I之间的一个映射,如下图所示:
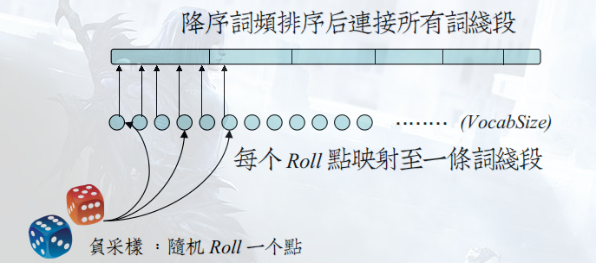
图例参考:http://www.cnblogs.com/neopenx/p/4571996.html ,建议大家读下这篇神作。
选取负例样本的时候,取[M0,Mm−1][M_0, M_{m-1}][M0,Mm−1]上的一个随机数,对应到I上就可以了。如果对于词wiw_iwi,正好选到它自己,则跳过。负例样本集合NEG(w)NEG(w)NEG(w)的大小在Word2Vec源码中默认选5.
二、CBOW
假定关于词www的负例样本NEG(w)NEG(w)NEG(w)已经选出,定义标签LLL如下,对于 ∀w~∈D\forall \widetilde{w} \in \mathcal{D}∀w∈D:
Lw(w~)={1,w~=w;0,w~≠w;
L^w(\widetilde{w}) = \Bigg\{ \begin{array} {ll}
1, & \widetilde{w} = w ;\\
0, & \widetilde{w} \ne w;
\end{array}
Lw(w)={1,0,w=w;w=w;
对于给定的一个正例样本(context(w),w)(context(w), w)(context(w),w), 要求:
maxg(w)=max∏u∈{w}∪u∈NEG(w)p(u∣context(w))
\max g(w) = \max \prod_{u \in \{w\} \cup u \in NEG(w)} p(u|context(w))
maxg(w)=maxu∈{w}∪u∈NEG(w)∏p(u∣context(w))
其中,
p(u∣context(w))={σ(xwTθu),Lw(u)=11−σ(xwTθu),Lw(u)=0
p(u|context(w)) = \Bigg \{ \begin{array}{ll}
\sigma(\boldsymbol{x}_w^T \theta^u), & L^w(u) = 1\\
1-\sigma(\boldsymbol{x}_w^T \theta^u), & L^w(u) = 0
\end{array}
p(u∣context(w))={σ(xwTθu),1−σ(xwTθu),Lw(u)=1Lw(u)=0
把它写成一个式子:
p(u∣context(w))=σ(xwTθu)Lw(u)+(1−σ(xwTθu))1−Lw(u)
p(u|context(w)) = \sigma(\boldsymbol{x}_w^T \theta^u)^{L^w(u)} + (1-\sigma(\boldsymbol{x}_w^T \theta^u))^{1-L^w(u)}
p(u∣context(w))=σ(xwTθu)Lw(u)+(1−σ(xwTθu))1−Lw(u)
下边解释为什么要最大化g(w)g(w)g(w),
g(w)=∏u∈{w}∪u∈NEG(w)p(u∣context(w))=∏u∈{w}∪u∈NEG(w)σ(xwTθu)Lw(u)+(1−σ(xwTθu))1−Lw(u)=σ(xwTθw)∏u∈NEG(w)(1−σ(xwTθu))
g(w) = \prod_{u \in \{w\} \cup u \in NEG(w)} p(u|context(w)) \\
=\prod_{u \in \{w\} \cup u \in NEG(w)} \sigma(\boldsymbol{x}_w^T \theta^u)^{L^w(u)} + (1-\sigma(\boldsymbol{x}_w^T \theta^u))^{1-L^w(u)} \\
=\sigma(\boldsymbol{x}_w^T \theta^w)\prod_{u \in NEG(w)} (1-\sigma(\boldsymbol{x}_w^T \theta^u))
g(w)=u∈{w}∪u∈NEG(w)∏p(u∣context(w))=u∈{w}∪u∈NEG(w)∏σ(xwTθu)Lw(u)+(1−σ(xwTθu))1−Lw(u)=σ(xwTθw)u∈NEG(w)∏(1−σ(xwTθu))
上式中连乘号前边的式子可以解释为最大化正例样本概率,连乘号后边解释为最小化负例样本概率。
同样的,针对于语料库,令:
G=∏w∈Cg(w)
\mathcal{G} = \prod_{w \in \mathcal{C}} g(w)
G=w∈C∏g(w)
可以将上式作为整体的优化目标函数,取上式的最大似然:
L=logG=∑w∈Clogg(w)=∑w∈C∑u∈{w}∪u∈NEG(w)Lw(u)log[σ(xwTθu]+[1−Lw(u)]log[1−σ(xwTθu)]
\mathcal{L} = \log\mathcal{G} = \sum_{w \in \mathcal{C}} \log g(w) \\
=\sum_{w \in \mathcal{C}} \sum_{u \in \{w\} \cup u \in NEG(w)}L^w(u)\log[\sigma(\boldsymbol{x}_w^T \boldsymbol{\theta}^u] + [1-L^w(u)]
\log [1-\sigma(\boldsymbol{x}_w^T \boldsymbol{\theta}^u)]
L=logG=w∈C∑logg(w)=w∈C∑u∈{w}∪u∈NEG(w)∑Lw(u)log[σ(xwTθu]+[1−Lw(u)]log[1−σ(xwTθu)]
和之前的计算过程一样,记
L(w,u)=Lw(u)log[σ(xwTθu]+[1−Lw(u)]log[1−σ(xwTθu)]L(w,u) = L^w(u)\log[\sigma(\boldsymbol{x}_w^T \theta^u] + [1-L^w(u)]\log [1-\sigma(\boldsymbol{x}_w^T \boldsymbol{\theta}^u)]
L(w,u)=Lw(u)log[σ(xwTθu]+[1−Lw(u)]log[1−σ(xwTθu)]
然后分别求:∂L(w,u)∂Xw\frac{\partial L(w,u)}{\partial\boldsymbol{X}_w}∂Xw∂L(w,u)和∂L(w,u)∂θu\frac{\partial L(w,u)}{\partial\boldsymbol{\theta}^u}∂θu∂L(w,u),求解过程略过:
∂L(w,u)∂Xw=[Lw(u)−σ(xwTθu)]θu∂L(w,u)∂θu=[Lw(u)−σ(xwTθu)]Xw
\frac{\partial L(w,u)}{\partial\boldsymbol{X}_w} = [L^w(u)-\sigma(\boldsymbol{x}_w^T \boldsymbol{\theta}^u)]\boldsymbol{\theta}^u \\
\frac{\partial L(w,u)}{\partial\boldsymbol{\theta}^u} = [L^w(u)-\sigma(\boldsymbol{x}_w^T \boldsymbol{\theta}^u)]\boldsymbol{X}_w
∂Xw∂L(w,u)=[Lw(u)−σ(xwTθu)]θu∂θu∂L(w,u)=[Lw(u)−σ(xwTθu)]Xw
则,可得到如下更新公式:
θu:=θu+η[Lw(u)−σ(xwTθu)]Xwv(w~):=v(w~)+∑u∈{w}∪u∈NEG(w)[Lw(u)−σ(xwTθu)]θu
\boldsymbol{\theta}^u:=\boldsymbol{\theta}^u+\eta [L^w(u)-\sigma(\boldsymbol{x}_w^T \boldsymbol{\theta}^u)]\boldsymbol{X}_w \\
v(\boldsymbol{\widetilde{w}}):=v(\boldsymbol{\widetilde{w}}) + \sum_{u \in \{w\} \cup u \in NEG(w)} [L^w(u)-\sigma(\boldsymbol{x}_w^T \boldsymbol{\theta}^u)]\boldsymbol{\theta}^u
θu:=θu+η[Lw(u)−σ(xwTθu)]Xwv(w):=v(w)+u∈{w}∪u∈NEG(w)∑[Lw(u)−σ(xwTθu)]θu
其中, w~∈context(w)\boldsymbol{\widetilde{w}} \in context(w)w∈context(w).

















 3619
3619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









