






以下是一些目前顶尖的OCR算法:
深度学习类
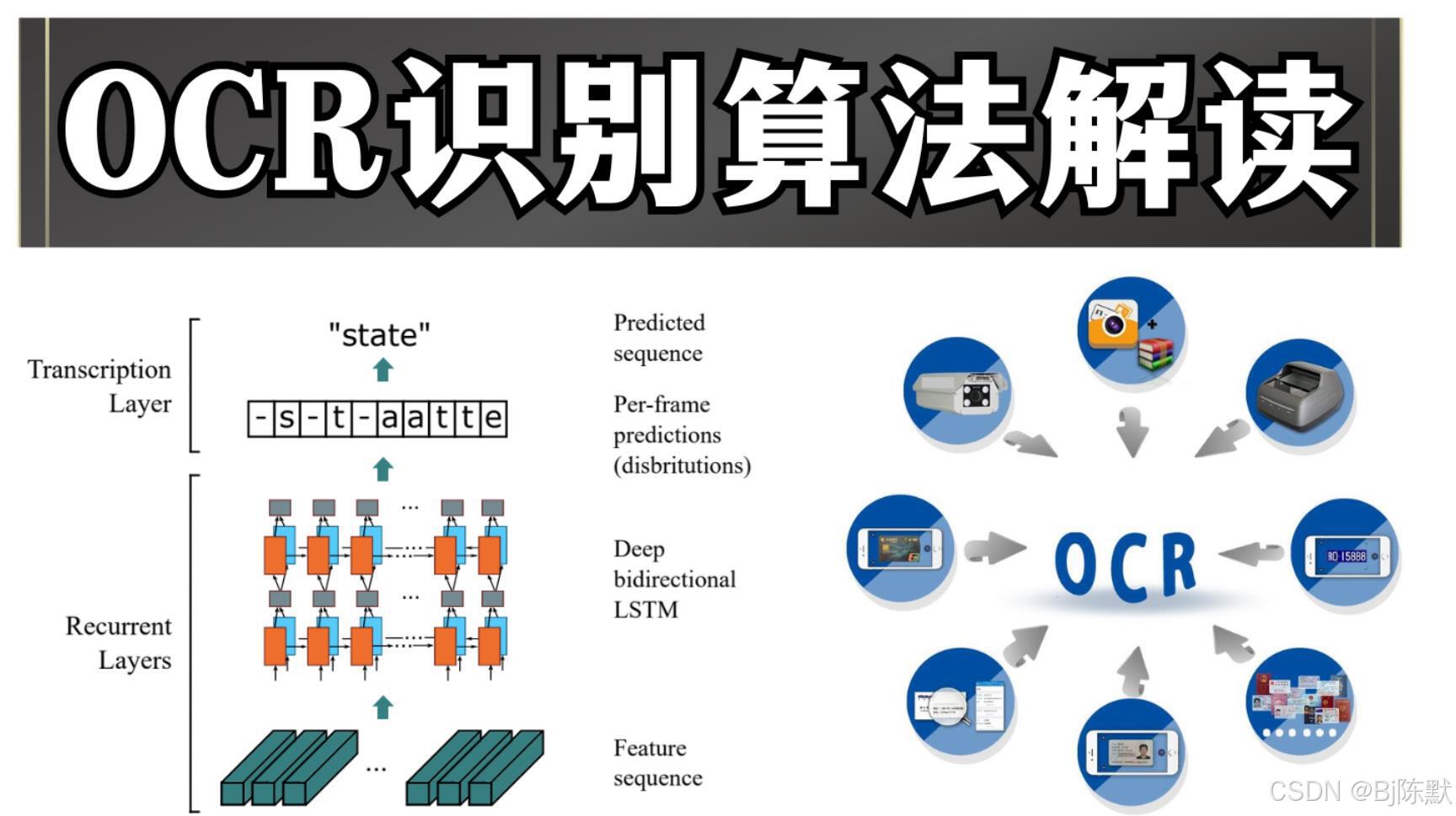
CRNN(Convolutional Recurrent Neural Networks):
原理:结合了卷积神经网络(CNN)和循环神经网络(RNN)。CNN负责从输入图像中提取特征,将图像中的文字信息转化为特征向量序列;RNN则对这些特征向量序列进行处理,以捕捉文字的序列信息,从而识别出不定长的文本。通常还会结合连接时序分类(CTC)损失函数,用于处理序列对齐问题,使得模型在不需要手工对齐的情况下,能够对文字进行准确识别。
优势:对各种场景下的文本,包括手写体、印刷体等都有较好的识别效果,尤其是对于不规则、模糊或倾斜的文字具有较强的鲁棒性;不需要对字符进行预先分割,能够直接对整段文本进行识别,提高了识别效率和准确性。
应用场景:广泛应用于文档识别、车牌识别、票据识别等场景。
EAST(Efficient and Accurate Scene Text detection):
原理:一种端到端的场景文本检测算法,采用特征金字塔和自顶向下的单次检测策略。它通过在不同尺度的特征图上进行文本检测,能够检测出不同大小和形状的文本区域。
优势:在处理速度和识别精度上取得了很好的平衡,能够快速准确地检测出图像中的文本区域;对各种复杂背景下的文本具有较好的检测效果,如自然场景中的文本、扭曲或变形的文本等。
应用场景:主要应用于场景文本检测任务,如街景文字识别、图像中的文本定位等。
CTPN(Connectionist Text Proposal Network):
原理:基于深度学习的文字检测算法,采用CNN+LSTM网络架构。首先利用CNN提取图像的特征,然后通过LSTM对特征进行序列建模,以预测文本区域的位置和得分。
优势:可以快速高效地检测出文本,尤其是对于长文本和弯曲文本的检测效果较好;能够生成较为准确的文本框,为后续的文本识别提供了良好的基础。
应用场景:常用于文档分析、图像文字提取等需要先定位文本区域的场景。
Densenet -OCR:
原理:采用密集连接卷积神经网络(DenseNet)和序列转录器(Transducer)。DenseNet能够有效地利用特征信息,减少梯度消失问题,提高模型的训练效率和准确性;序列转录器则用于对文本序列进行建模和识别。
优势:提高了文本识别精度,在处理复杂图像和多种语言文本时表现出色;模型的泛化能力较强,能够适应不同的数据集和应用场景。
应用场景:适用于对多种语言和复杂图像中的文本进行高精度识别的场景,如多语言文档处理、古籍数字化等。
其他类
PaddleOCR:
原理:百度公司推出的OCR工具,集合了当前OCR领域的一系列尖端算法,如SVTRv2和SLANet-LCNetV2等,还引入了“PP-OCR”产业级特色模型。它支持多种OCR相关前沿算法,打通了数据生产、模型训练、压缩、预测部署全流程。
优势:具有高精度、多语种支持(约80种语言)、高效性、易用性和鲁棒性等特点。其训练和推理过程采用高效的并行计算方法,轻量化设计使其能在移动设备上部署,还提供丰富的API接口和文档说明。
应用场景:涵盖金融、零售电商、教育出版、医疗健康等多个行业和领域,如自动化票据处理、商品标签识别、文档自动整理、医疗记录电子化等。
Surya OCR:
原理:基于先进的深度学习技术,通过图像预处理、文本检测、特征提取、字符识别和后处理等步骤实现文本识别。
优势:支持90多种语言的字符识别,能够满足全球用户的需求;在处理复杂文本图像时具有较高的识别率,能准确识别手写体、印刷体、混合体等多种文本形式;还能进行文档布局分析、表格识别和读取顺序检测等。
应用场景:可应用于文档数字化、数据提取、科研与教育、自动化办公等场景。


















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











