




 探讨使用XPath在Web自动化中定位页面元素的两种方法,一种使用contains函数,另一种直接匹配文本。通过对比发现不同写法可能导致的错误及正确用法。
探讨使用XPath在Web自动化中定位页面元素的两种方法,一种使用contains函数,另一种直接匹配文本。通过对比发现不同写法可能导致的错误及正确用法。
关于web自动化xpath定位页面文本信息的问题
最近在学习web自动化的过程中,遇到了一个比较棘手的问题,在网上搜索了很久也没有找到相关答案,所以想把问题发出来,希望看到的各位大佬可以指导一下。
测试网页源码如下:
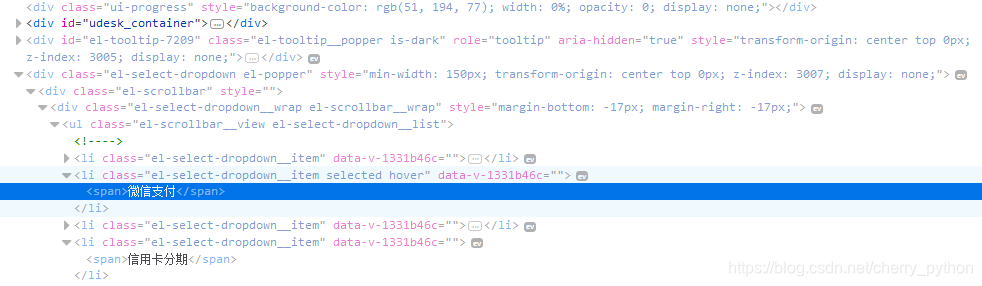
在通过xpath定位微信支付时,browser.find_element(By.XPATH("//span[contains(text(),‘微信支付’)]")).click(),系统报Traceback (most recent call last):
File “E:/Program Files/PythonTest/WebDriver/By_xpath_p1.py”, line 24, in
broser.find_element(By.XPATH("//span[contains(text(),‘微信支付’)]")).click()
TypeError: ‘str’ object is not callable
但是修改为browser.find_element_by_xpath("//*[text()=‘微信支付’]").click()定位就没有问题了。
不知道第一种写法和第二种写法之前是不是有什么区别或者是少导入了什么包之类的,还请路过的大佬们给予指导,拜谢!

















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









