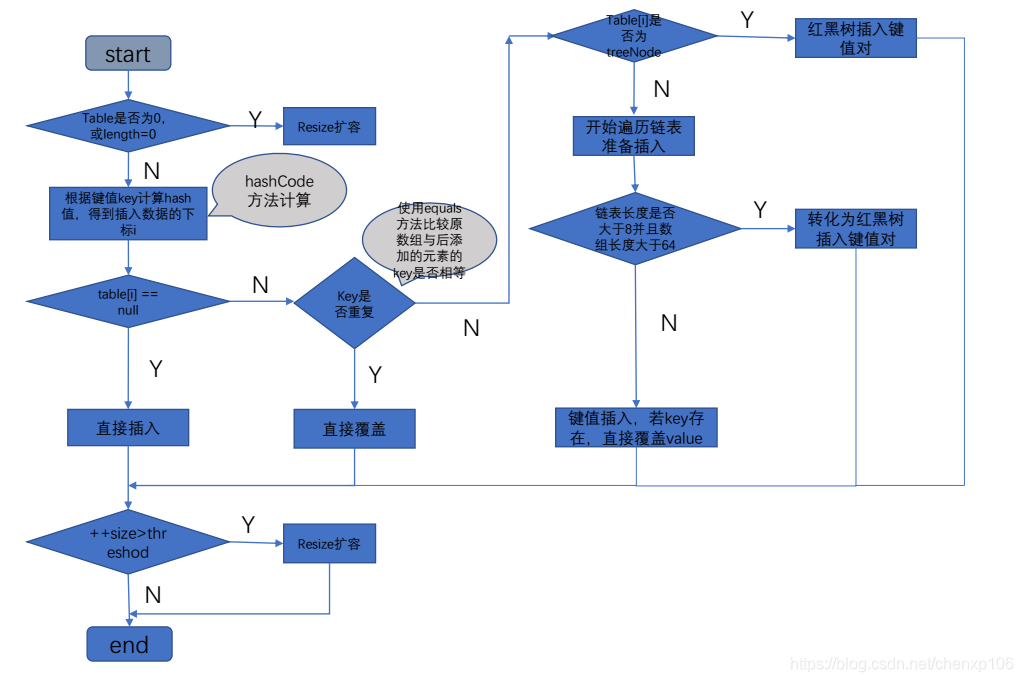
HashMap中put方法流程图
最新推荐文章于 2024-12-19 19:38:43 发布





 博客内容提及插入图片描述,但未给出更多关键信息。
博客内容提及插入图片描述,但未给出更多关键信息。
博客内容提及插入图片描述,但未给出更多关键信息。
博客内容提及插入图片描述,但未给出更多关键信息。
 1884
392
315
938
1884
392
315
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























{kind=link}