




大家好,我是微软学生大使 Jambo。在我们申请好 Azure 和 Azure OpenAI 之后,我们就可以开始使用 OpenAI 模型了。如果你还没有申请 Azure 和 Azure OpenAI,可以参考 注册 Azure 和申请 OpenAI。
本文将会以 Azure 提供的 Openai 端口为例,并使用 OpenAI 提供的 Python SDK 进行模型的调用。
创建工作区
进入 Azure 首页,在搜索栏中输入 OpenAI,点击进入 OpenAI 页面。
点击创建。
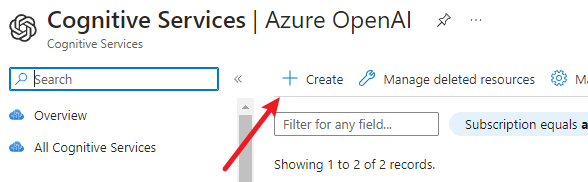
选择订阅,资源组,工作区名称,工作区地区,点击创建。这里我们地区选择 “美东” ,因为目前只有这个地区支持 chatgpt 对话模型。如果你不需要对话模型,可以选择其他模型种类更多的 “西欧”。
选择下一步,确认无误后点击创建。
等他创建完成后,点击 “探索” 进入工作区。
模型介绍
在使用模型之前,我们先来了解一下 Azure 提供了哪些 OpenAI 模型。Azure 提供的模型从功能上可以分为三大类:补全(completion)、对话(chat)、嵌入(embeddings)。
补全模型可以根据输入的文本,补全剩余的文本。这类模型顾名思义,就是根据前文续写后续的部分。他可以用来续写文章,补全程序代码。不仅如此,你其实也可以通过固定的文字格式来实现对话的效果。
对话模型相信有使用过 ChatGPT 的同学应该很熟悉。对话模型可以根据输入的文本,生成对话的回复。这类模型可以用来实现聊天机器人,也可以用来实现对话式的问答系统。在调用方面,对话模型与补全模型最主要的区别是:你需要一个列表来存储对话的历史记录。
没接触过过 NLP(自然语言处理) 的同学可能会对 “嵌入” 这个词感到疑惑。“嵌入” 实际上就是将文本转换为向量的操作,而这个向量可以用来表示文本的语义信息,这样就可以方便地比较语义的相似度。而嵌入模型就是用来实现这个操作的。
大部分模型拥有多个能力等级,能力越强能处理的文字也就越复杂,但相对的处理速度和使用成本也就越高。通常有 4 个等级:Davinci > Curie > Babbage > Ada ,其中 Davinci 最强而 Ada 是最快的(有兴趣的同学可以查一下这 4 位名人)。在使用模型时,你可以根据自己的需求选择合适的等级。
具体的模型介绍可以参考 Azure OpenAI 服务模型。
部署模型
在了解了模型的功能和等级之后,我们就可以开始使用模型了。在使用模型之前,我们需要先部署模型。在 Azure OpenAI 工作区中,进入 “部署” 页面。
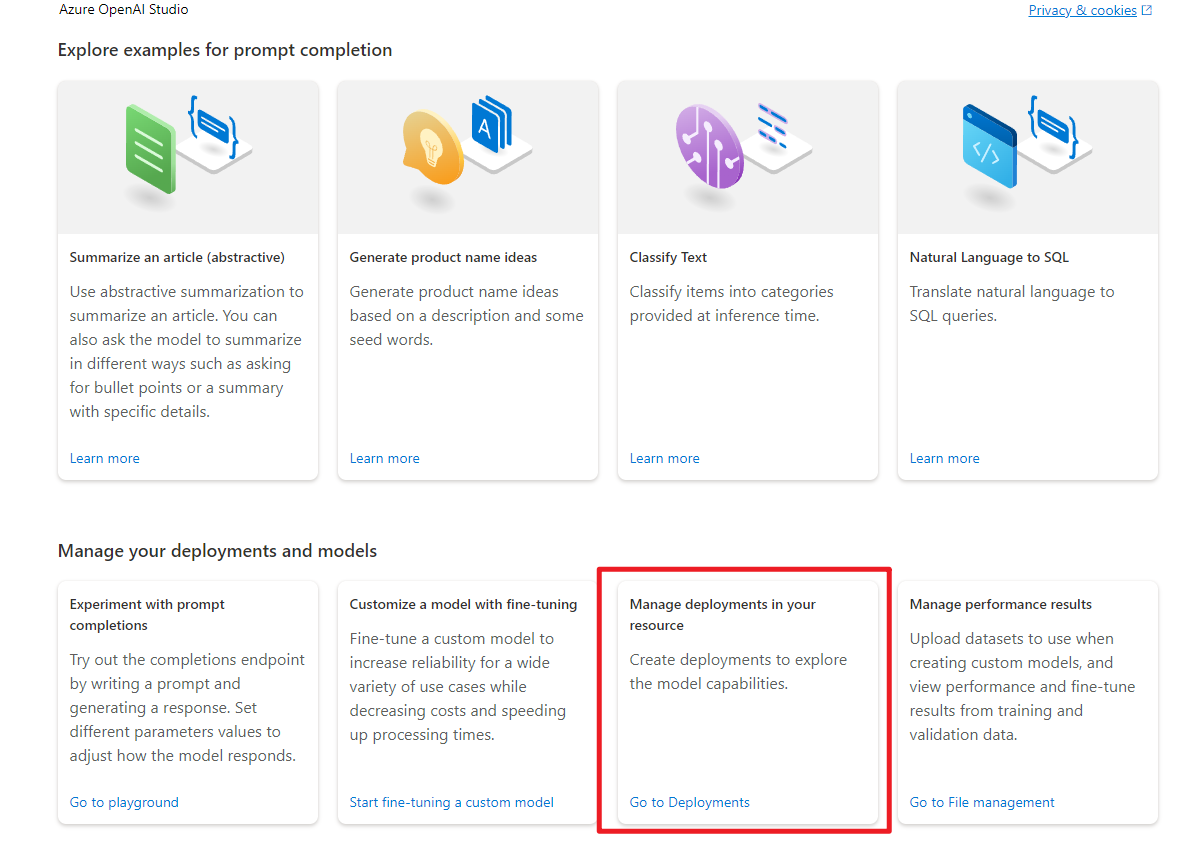
选择模型,点击创建。这里我部署了一个补全模型和对话模型。
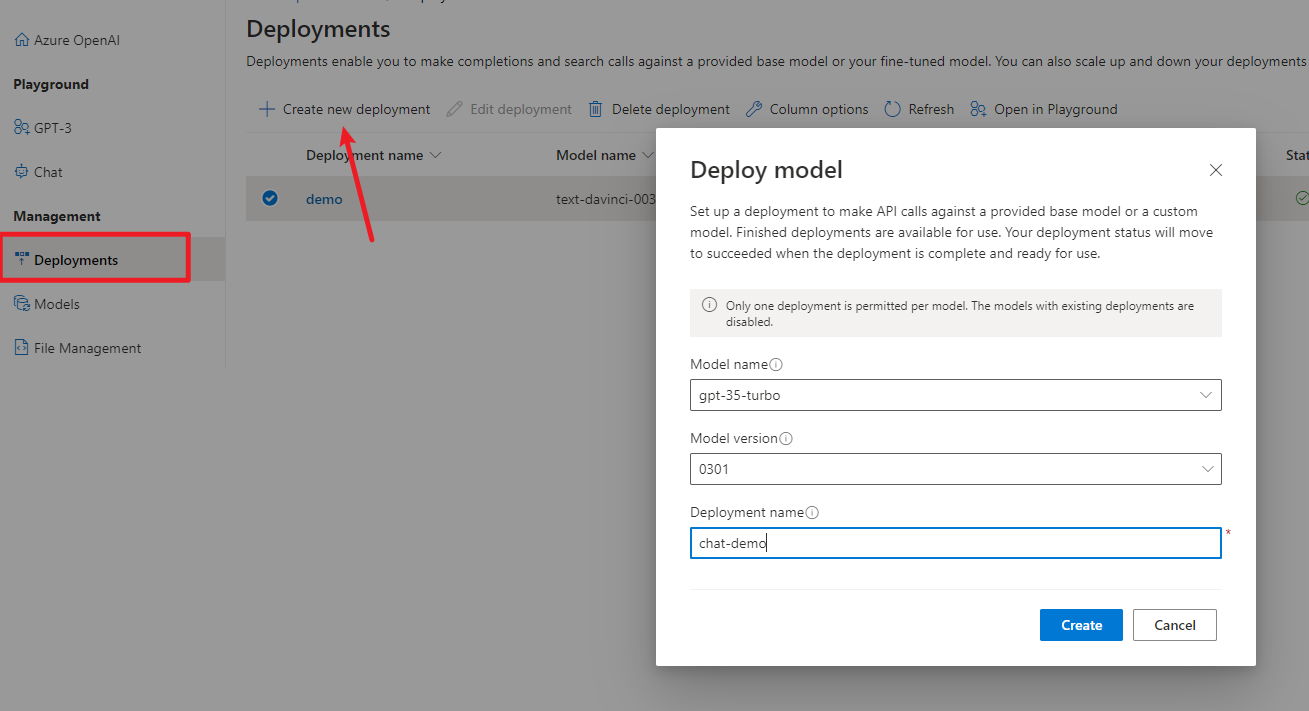
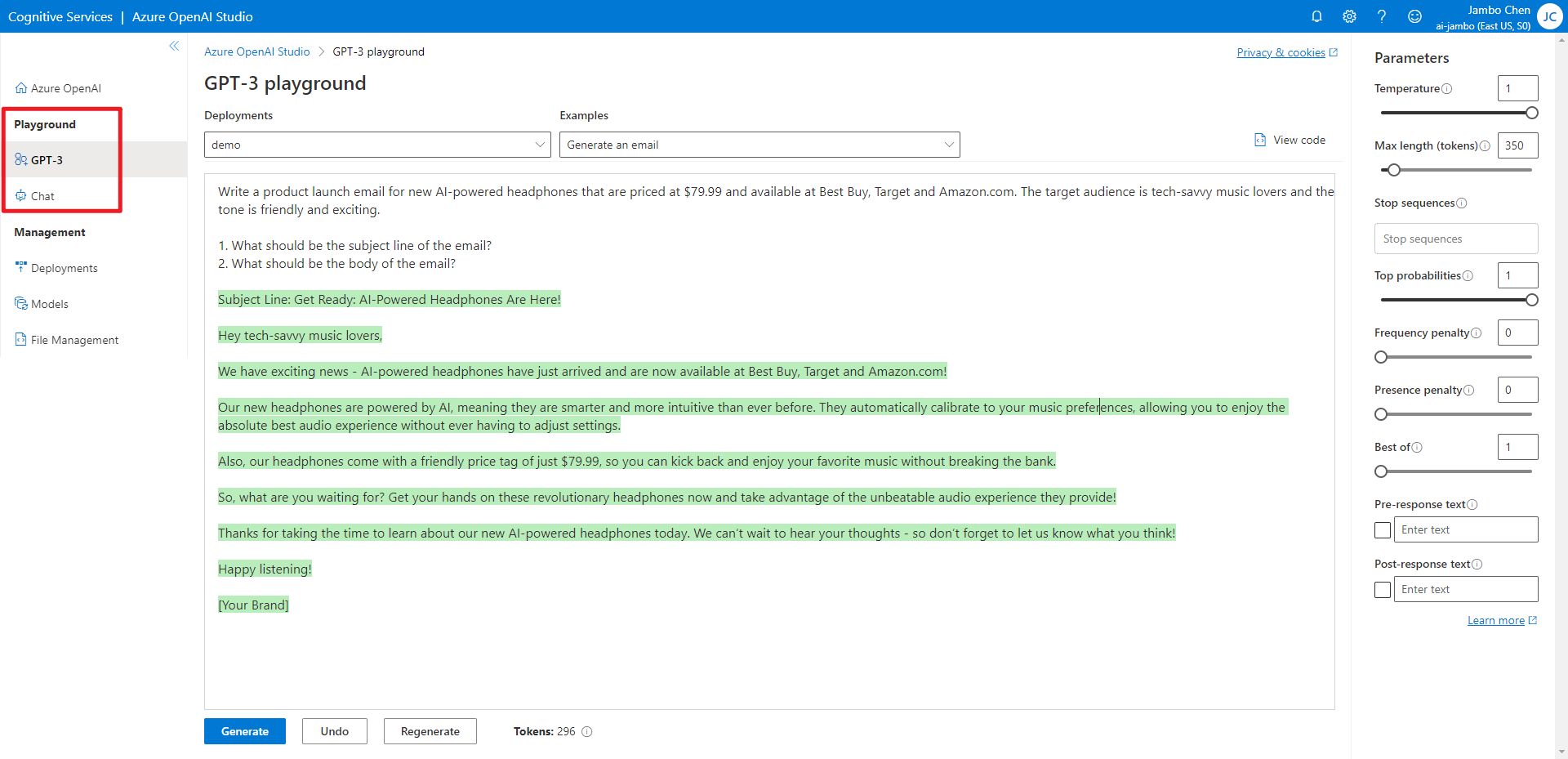
部署后你就可以用 API 调用模型了,当然你也可以现在 Playground 中测试一下。
API 参数
在 Playground 中测试模型时,我们可以看到 API 的参数。这里我们来介绍一下这些参数。具体的参数细节可以参考 API Reference。
model指定使用的模型。prompt是输入给模型的文本。temperature控制了生成文本的随机程度,值越大,生成的文本越随机,值越小,生成的文本越稳定。这个值的范围在 0.0 到 2.0 之间(虽然在 Playground 中最高只能设为 1)。top_p与temperature类似,也是控制生成文本的随机程度。但这个参数简单的说是控制候选词的范围,值越大,候选词的范围越大,值越小,候选词的范围越小。这个值的范围在 0.0 到 1.0 之间。通常来说,这两个参数只需要设置一个就可以了。max_tokens是模型生成的文本的最大长度,这其中的 “token” 不是指字符长度,你可以把他理解为模型眼中的 “词”。Token 与我们所使用的词不一定是一一对应的。stop是生成文本的停止条件,当生成的文本中包含这个字符串时,生成过程就会停止,最终生成的文本中将不包含这个字符串。这个参数可以是一个 string,也可以是一个长度至多为 4 的 string 列表。presence_penalty控制生成文本的多样性。他会惩罚那些在生成文本中已经出现过的 token,以减小未来生成这些 token 的概率。这个值的范围在 -2.0 到 2.0 之间。如果设为负值,那么惩罚就会变为奖励,这样就会增加生成这些 token 的概率。frequency_penalty与presence_penalty类似,也是控制生成文本的多样性。但不同的是,presence_penalty是一次性惩罚,而frequency_penalty累计惩罚。如果一个词在生成文本中出现了多次,那么这个词在未来生成的概率就会越来越小。这个值的范围同样在 -2.0 到 2.0 之间。
计算 Token
GPT 模型使用 token 来表示文本,而不是使用字符。模型能处理的文本长度是有限的,而这个长度指的是 token 的数量,而不是字符的数量,并且 OpenAI 使用模型的计费方式也是按照生成 token 的数量计算。因此为了能够更好地使用模型,我们需要知道生成的文本究竟有多少 token。
OpenAI 提供了一个 Python 库 tiktoken 来计算 token。
pip install tiktoken
导入 tiktoken 库。
import tiktoken
不同模型使用不同的编码来将文本转换为 token。
| Encoding name | OpenAI models |
|---|---|
cl100k_base |
gpt-4, gpt-3.5-turbo, text-embedding-ada-002 |
p50k_base |
Codex models, text-davinci-002, text-davinci-003 |
r50k_base (or gpt2) |
GPT-3 models like davinci |
我们可以使用 tiktoken.get_encoding() 来获取编码对象。也可以使用 tiktoken.encoding_for_model() 通过模型名自动获取编码对象。
encoding = tiktoken.get_encoding("cl100k_base")
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
然后用 .encode() 方法将文本 token 化。返回的 token 列表的长度,就是这段文本的 token 数量。
encoding.encode("tiktoken is great!")
[83, 1609, 5963, 374, 2294, 0]
我们还可以使用 .decode() 将 token 列表转换为文本。
encoding.decode([83, 1609, 5963, 374, 2294, 0])
'tiktoken is great!'
使用 Python SDK
我们首先需要到 Azure 的 “密钥” 页面获取密钥和终结点,两个密钥只要其中一个即可。
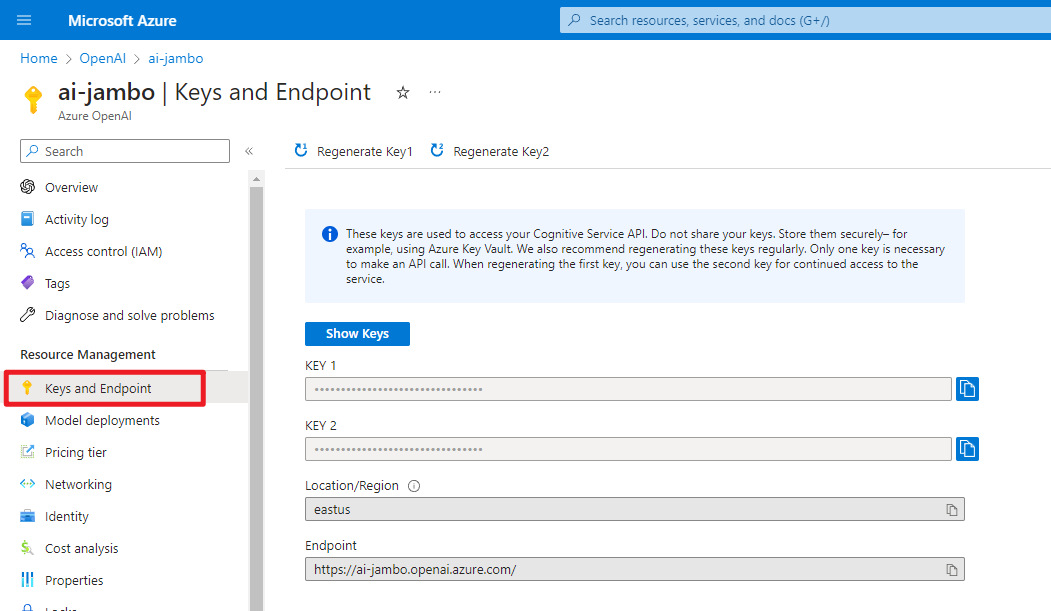
然后安装 openai 库。注意,Python 版本需要大于等于 3.7。我们这里使用官方提供的 Python SDK,其他语言的 SDK 可以在 OpenAI Libraries 找到。
另外,因为这个库没有专门的文档参考,所以我们需要查看库的源码和 API 参考。
pip3 install openai
更具先前获取的密钥和终结点初始化 SDK:
import openai
openai.api_key = "REPLACE_WITH_YOUR_API_KEY_HERE" # Azure 的密钥
openai.api_base = "REPLACE_WITH_YOUR_ENDPOINT_HERE" # Azure 的终结点
openai.api_type = "azure"
openai.api_version = "2023-03-15-preview" # API 版本,未来可能会变
model = "" # 模型的部署名
调用补全模型
补全模型使用的是 openai.Completion.create 方法,使用的参数在上面已经介绍过了,但因为我使用的是 Azure 的 API,所以指定模型的参数名是 engine。下面是一个简单的例子:
prompt = "1, 2, 3, 4, "
response = openai.Completion.create(
engine=model, prompt=prompt, max_tokens=50, temperature=0.0
)
print(response)
它打印出的内容就是 API 返回的 json 结果。其中 text 就是模型生成的文本,可以看到它将数列续写下去。但他只停在 21,是因为我设置了 max_tokens=50
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









