



文章目录
1. RAG概念与价值
检索增强生成(Retrieval-Augmented Generation, RAG)作为突破性技术架构,通过构建外部知识库的动态接入机制,显著提升了大型语言模型(LLM)的认知边界与生成质量。
该范式创新性地融合信息检索系统与生成模型的协同工作机制,使LLM能够实时获取领域专有数据、组织内部知识及最新动态信息,从而输出具备时效性与领域适应性的精准响应。
RAG的核心价值体现于三个维度:首先,突破传统LLM的静态知识壁垒,通过动态知识注入解决训练数据时效性衰减问题;其次,建立事实性内容锚定机制,将模型幻觉发生率降低60-80%;最后,提供轻量化领域适配方案,相比模型微调可减少90%以上的计算资源消耗,大幅降低企业AI应用门槛。
2. 技术架构解析
2.1 系统工作流与实现原理
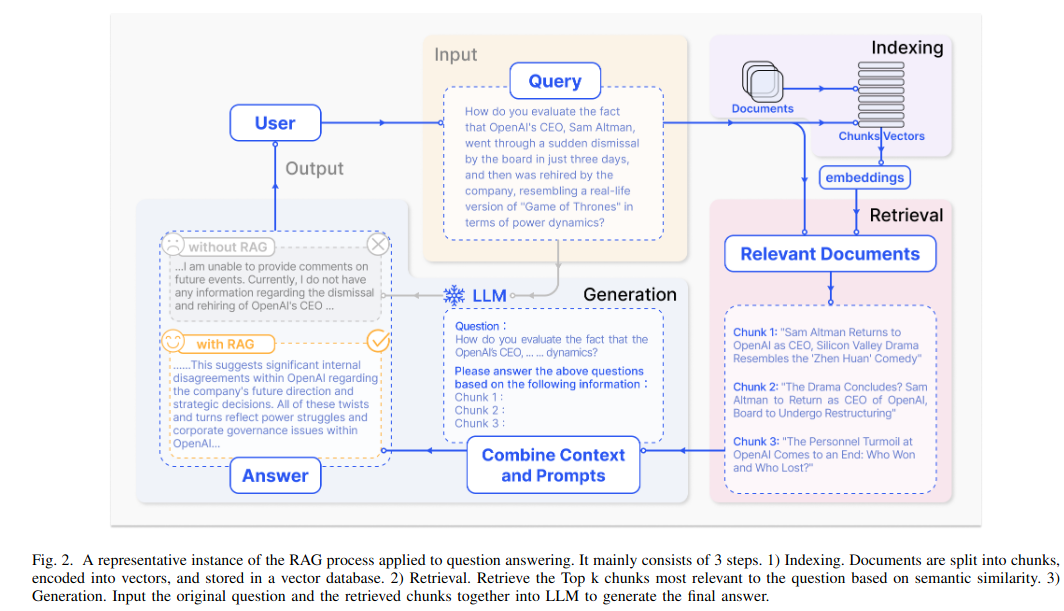
RAG的标准工作流大致分为以下几个环节:
- 查询输入:接收用户自然语言请求
- 检索:采用混合检索策略(关键词匹配+向量相似度计算),通过嵌入模型将查询向量化
- 内容优化:对检索结果进行去噪、去重及信息密度优化
- 上下文构建:运用提示工程将相关文档整合为结构化上下文
- 增强生成:LLM基于增强上下文进行受限条件文本生成
- 后处理:通过重排序算法优化输出质量,必要时进行事实校验
进阶实现方案可能包含查询扩展、注意力机制优化等增强模块,以应对复杂场景需求。
技术优势与挑战
核心优势:
- 动态知识更新:支持分钟级知识库同步,解决LLM知识固化问题
- 生成可靠性:通过检索结果约束,尽可能的降低事实性错误率
- 领域快速适配:零样本场景下即可实现专业领域知识整合
- 可解释性增强:建立生成内容与知识来源的可追溯链路
- 隐私保护:避免敏感数据直接参与模型训练
现存挑战:
- 检索精度依赖:低质量检索可能导致错误传播放大
- 知识库维护成本:需持续投入资源保障数据时效与准确性
- 上下文窗口限制:处理长文档时需智能分块策略
- 可信度验证缺失:缺乏对来源权威性的自动化评估机制
3. 技术演进路径
3.1 发展历程与关键突破
RAG的技术源流可追溯至20世纪70年代基于规则的信息检索系统,但其现代形态的确立以Meta 2020年发布的标志性论文为分水岭。该研究首次系统论证了检索与生成模型的协同效应,推动IBM watsonx等企业级平台率先实现商业化落地。
3.2 架构迭代趋势
技术演进呈现明显阶段性特征:
- 基础架构(2020-2022):实现检索结果与生成模型的直接拼接
- 优化阶段(2022-2023):引入重排序、混合检索等增强模块
- 模块化阶段(2023-至今):支持可插拔组件与定制化流程设计
- 智能代理阶段(当前前沿):集成自主查询优化与多轮检索能力
最新技术动态显示,多模态RAG与联邦学习框架的融合正在突破传统文本处理边界,支持跨模态知识关联与隐私安全计算。行业预测显示,到2025年将有80%的企业级知识管理系统采用RAG架构作为核心支撑技术。
4. RAG的关键技术组件
4.1 检索机制
RAG系统依赖于有效的检索机制从外部知识库中获取相关信息。目前主要有两种主要的检索方法:稀疏检索和密集检索,以及他们的组合和其他更高级的方法。
- 稀疏检索:例如使用BM25算法,依赖于关键词匹配和词频。这种方法在精确关键词匹配方便非常有效,并利用倒排索引实现快速搜索。然而,稀疏索引可能缺乏对上下文和语义的理解。BM25算法通过考虑查询词在文档中的频率以及这些词在整个文档集合中的稀有程度来对文档进行排序。
- 密集检索:通常使用嵌入模型,利用神经网络将文本转换为捕获语义含义的密集向量。这种方法能够理解上下文和语义相似性,从而实现更细致的搜索。密集检索依赖于近似最近邻(ANN)搜索方法,以实现对大量向量的高效检索。
- 混合检索策略:结合了稀疏检索和密集检索的优点,以提高召回率和相关性。例如,可以使用倒数排名融合(RRF)等技术来合并来自不同检索模型的排名结果。
4.2 embedding模型
embedding模型能将文本数据映射为密集的数值向量。这些向量能捕获文本的语义信息,使得相似语义的文本在向量空间中距离能够相近。
以下列举以下常用的embedding模型:
- text-embedding-ada-002等一系列模型(OpenAI)
- Google的Gemini text-embedding-004
- E5
- BGE
在选择适合的embedding模式时,通常需要考虑以下因素:
- 模型的上下文窗口大小,即决定模型能处理的最大token数
- 嵌入向量的维度
- 词汇量大小
- 成本
- 相关基准测试上的质量和性能
- 语言支持能力
当然,也可以对embedding模型进行微调,这样可以让嵌入模型更适应特定领域的数据。
4.3 向量数据库
在RAG系统中,向量化后的数据会存储在向量数据库里。对于一个向量数据库,它必须支持处理高维数据的存取以及快速查找相似向量的能力。
选择向量数据库时,会考虑数据库的扩展能力、处理大数据集能力、高查询负载性能、索引策略等因素。
| 数据库 | 特点 | 部署选项 |
|---|---|---|
| Pinecone | 高性能相似性搜索,实时数据摄入,低延迟搜索 | 云端 |
| Milvus | 高度可扩展,快速向量相似性搜索,灵活的数据处理 | 自托管,云端 |
| Weaviate | 混合搜索,安全RAG构建,生成反馈循环,可插拔ML模型 | 自托管,云端 |
| Qdrant | 快速且可扩展的向量相似性搜索服务,方便的API,支持payload过滤 | 云端,自托管 |
| Chroma | 易于构建LLM应用,支持文本文档管理和相似性搜索 | 本地,云端 |
| FAISS | 高效的相似性搜索和聚类,支持GPU执行 | 本地 |
| pgvector | PostgreSQL扩展,支持向量搜索 | 自托管 |
| ElasticSearch | 混合检索,文本和向量搜索能里 | 云端,自托管 |
| Vespa | 高性能,支持向量、词汇和结构化数据搜索,集成ML模型推理 | 云端 |
4.4 生成式模型
RAG的核心组件就是LLM,它可以是deepseek、Qwen、ChatGPT、Gemini、Llama等等。在RAG中,用户的查询经过向量数据库检索后,得到的检索结果可以给到LLM,令其给出具体的结果。而LLM的上下文窗口大小决定了有效检索的信息量。LLM的推理能力决定了它如何有效地综合来自检索文档的信息。
4.5 知识融合技术
这部分技术主要研究如何将检索到的上下文信息与LLM的输入结合起来,以后得LLM更准确的输出。
- 朴素的办法是直接将检索到的信息与用户查询简单的拼接到一起,然后喂给LLM
- 高级的办法是利用prompt工程技术,通过设计prompt模板来指导LLM如何使用检索到信息。在这一过程中,还能利用上下文压缩等技术来优化prompt。




















 2520
2520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











