




截断策略迭代算法(Truncated Policy Iteration Algorithm)是强化学习中一种结合策略迭代(Policy Iteration)和值迭代(Value Iteration)思想的优化算法,通过截断策略评估步骤在计算效率与收敛性之间取得平衡。
目录:
- value iteration& policy iteration
- Truncated Policy Iteration算法原理
- Truncated Policy Iteration 优缺点分析
- 三种算法比较 Python 例子
一 value iteration& policy iteration
1.1 Policy iteration

给定一个初始的policy
step1: PE( Policy evaluation) :
固定策略,进行max_iterations次迭代 验证对应策略下面的state value
step2: PI(Policy improvement)
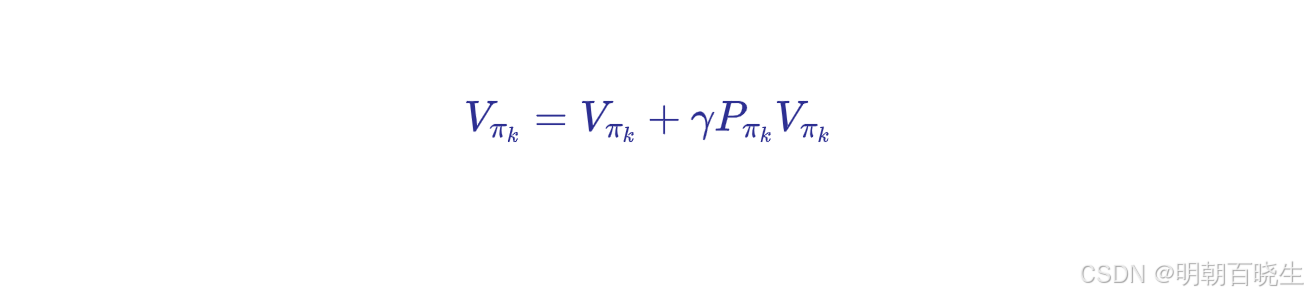
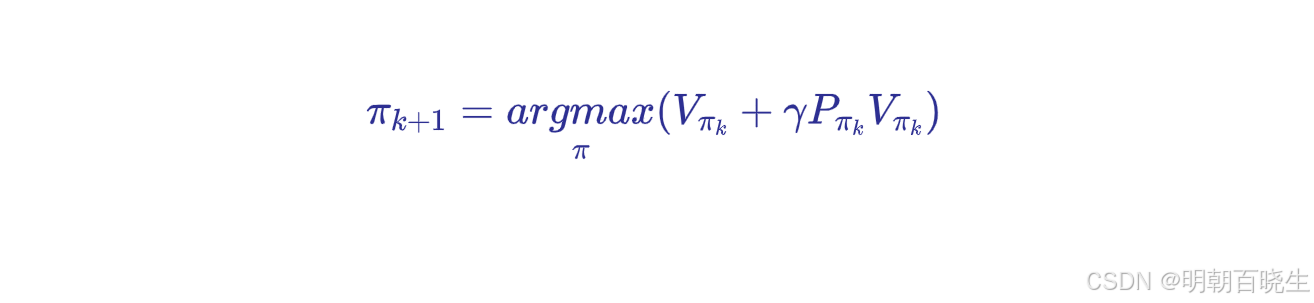
1.2 Value iteration:

这是一种迭代算法解Bellman公式
给定一个初始的状态值
值迭代过程中:
每次更新 Vk+1(s) 时,step1: PU(Policy update)
实际代码实现中这一步是并没有,策略在每次价值函数更新时已被间接确定,无需显式存储或输出。
step2: Value update
代码是通过后面q(s,a)得到的
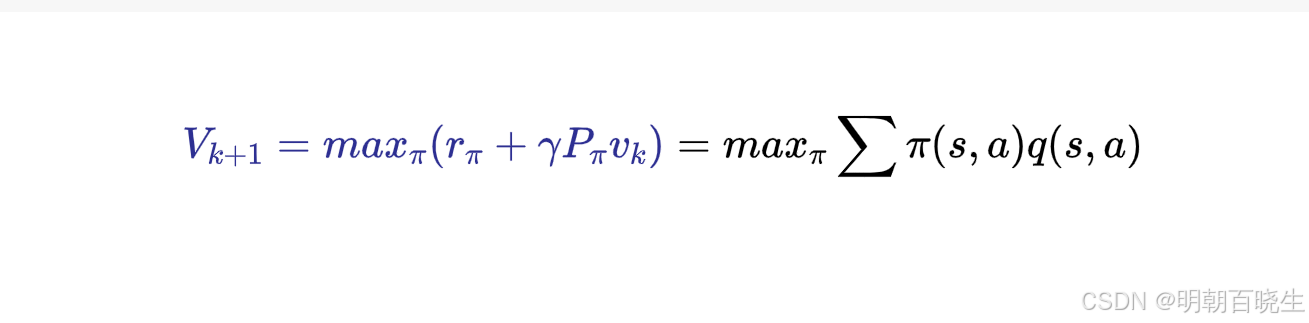
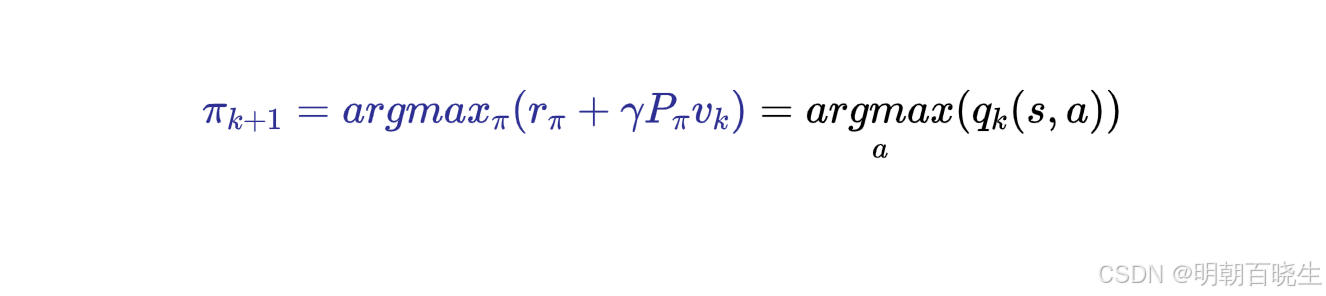
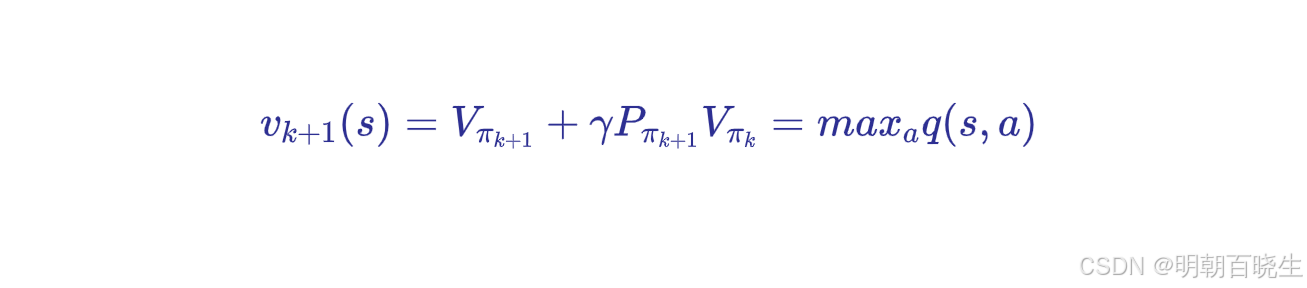
二 Truncated Policy Iteration 算法
策略迭代包含两个交替步骤:
- 策略评估(Policy Evaluation):计算当前策略下的状态价值函数 Vπ(s),通常需多次迭代直至收敛。
- 策略改进(Policy Improvement):基于当前价值函数,通过贪心策略更新策略 π(s)=argmaxaQπ(s,a)。
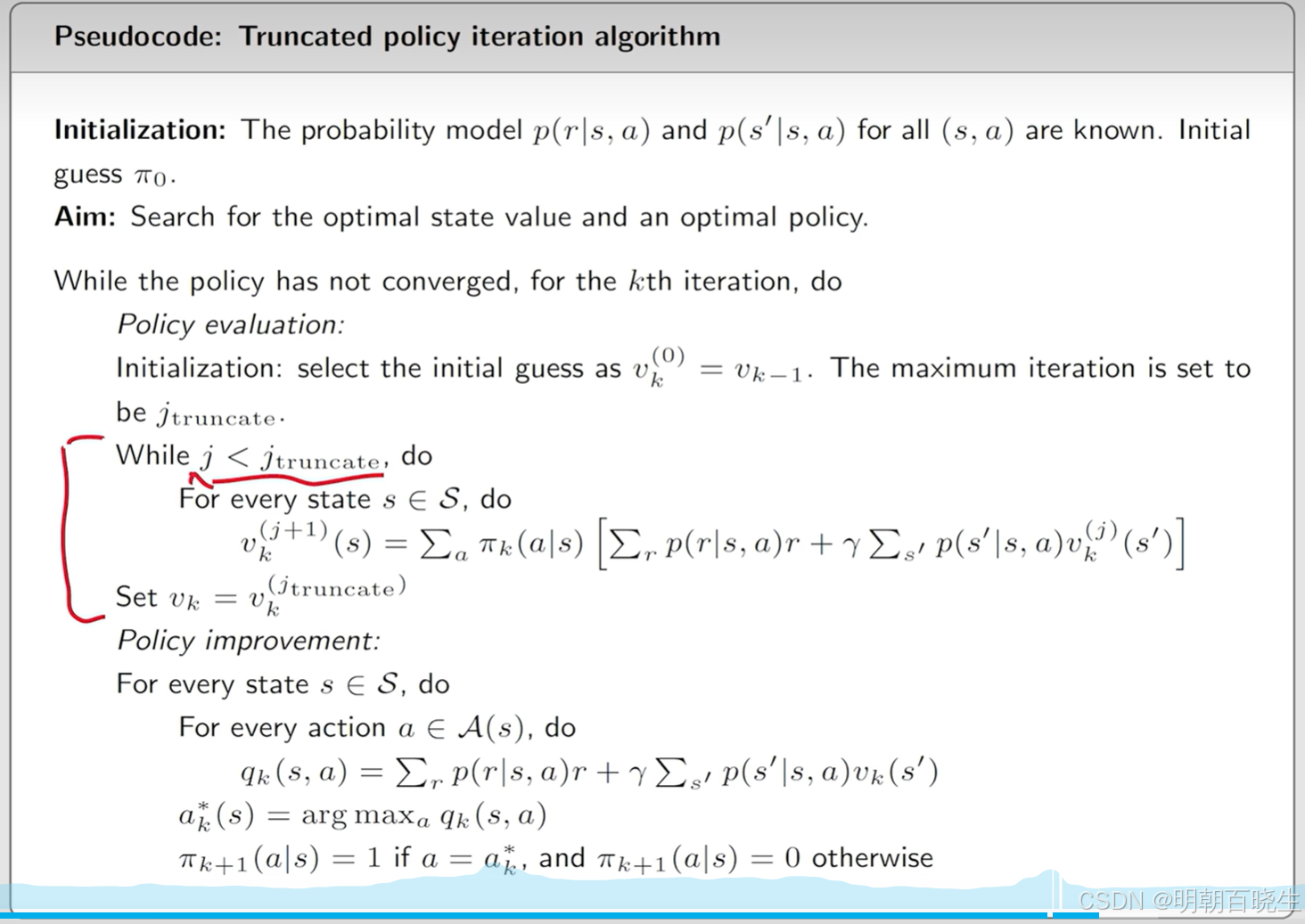
截断策略迭代的核心思想:在策略评估阶段不进行完整迭代,而是仅执行有限次(如 k 次)更新后即进入策略改进。这减少了计算量,同时保留了收敛性保证。
三 Truncated Policy Iteration 优缺点分析
| 优点 | 缺点 |
|---|---|
| 计算效率高:通过截断策略评估减少单次迭代时间,尤其适用于大规模状态空间。 | 收敛速度可能较慢:截断可能导致价值函数估计不精确,需更多迭代达到收敛。 |
| 灵活性:可通过调整 k 平衡计算量与精度,适应不同场景需求。 | 参数选择敏感:k 的选择需权衡效率与精度,缺乏通用最优值。 |
| 理论保证:在有限马尔可夫决策过程(MDP)中,仍能收敛到最优策略。 | 实现复杂度略高:需显式管理截断次数和终止条件。 |
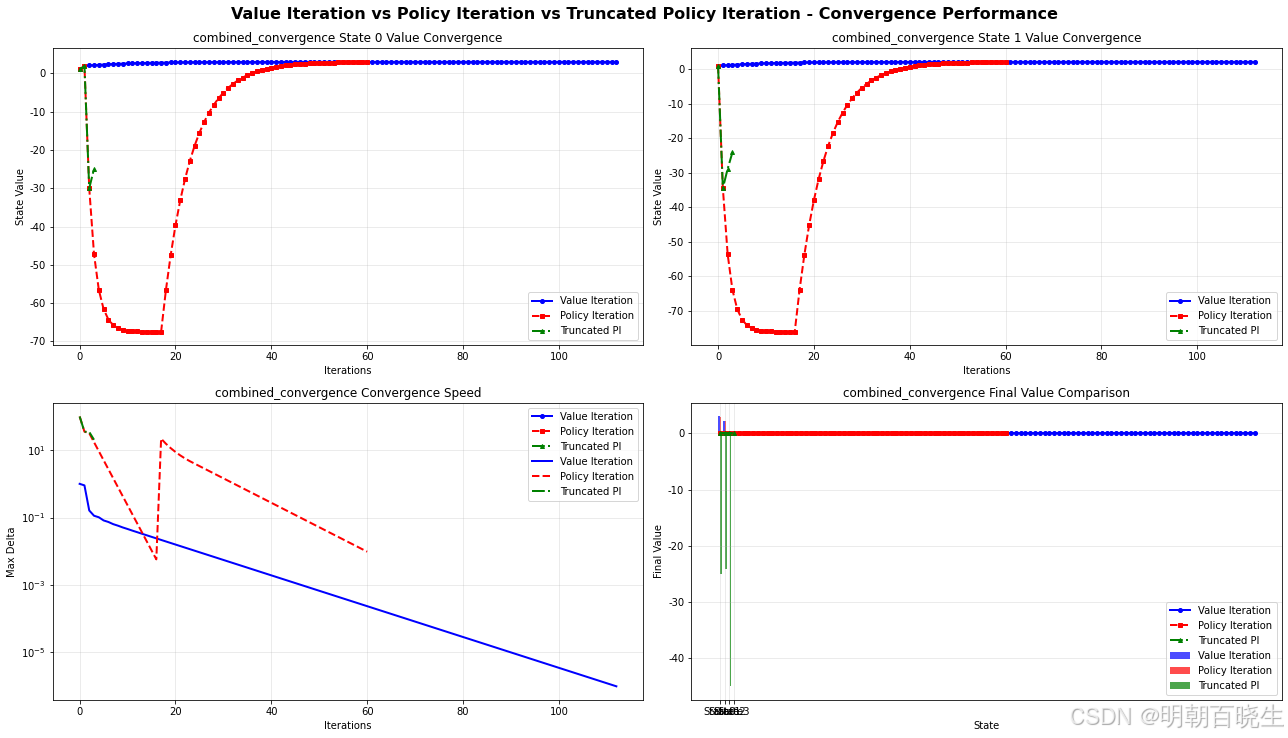
四 三种算法比较python 例子(西瓜书)
6.1 值迭代 (ValueIterationSolver) ✅
-
每次迭代对所有状态进行价值更新:
new_values[state] = max(q_values) -
使用贝尔曼最优方程进行更新
-
最后提取最优策略:
self.policy = self.extract_policy() -
收敛条件:价值函数变化小于阈值theta
6.2 策略迭代 (PolicyIterationSolver) ✅
-
策略评估阶段:在固定策略下评估价值函数
self.evaluate_policy() -
策略改进阶段:提取贪婪策略
self.extract_policy() -
收敛条件:策略不再变化
截断策略迭代 (TruncatedPolicyIterationSolver) ✅
-
策略评估阶段只进行有限次迭代 (
truncation_limit) -
其他逻辑与完整策略迭代相同
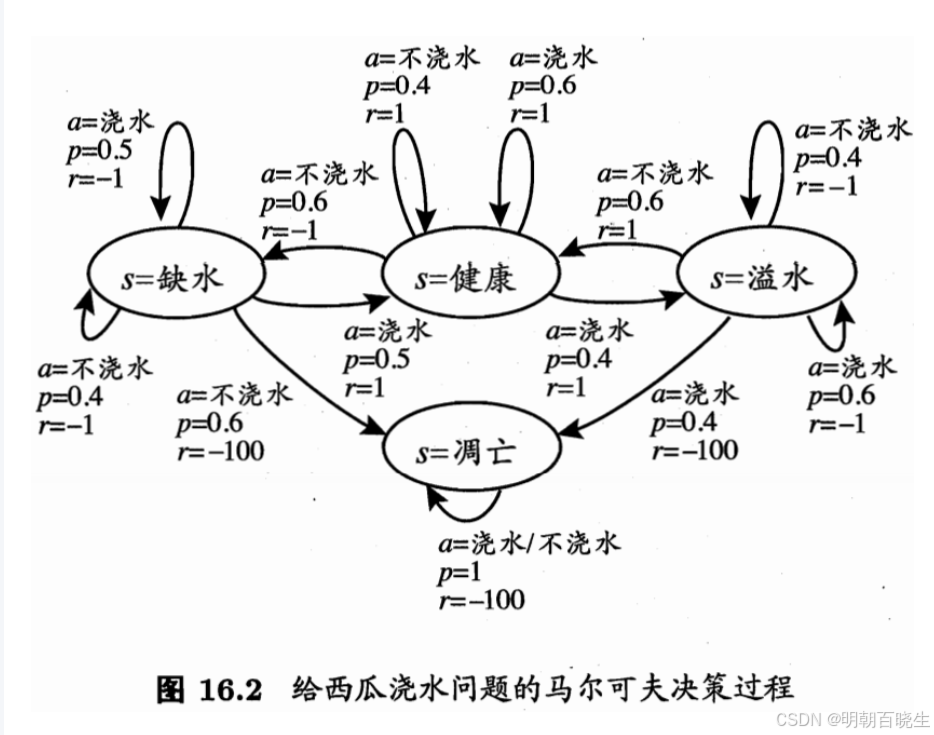
以下面为例
# -*- coding: utf-8 -*-
"""
MDP求解器增强版:包含值迭代、策略迭代和截断策略迭代
比较三种算法的收敛性能
Created on Fri Sep 12 15:36:54 2025
@author: chengxf2
"""
import locale
import sys
from dataclasses import dataclass, field
from enum import Enum
from typing import Dict, List, Tuple
import matplotlib as mpl
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
import numpy as np
class State(Enum):
"""状态枚举"""
DEHYDRATED = 0 # 缺水
HEALTHY = 1 # 健康
WATERLOGGED = 2 # 溢水
WITHERED = 3 # 凋亡
class Action(Enum):
"""动作枚举"""
DO_NOT_WATER = 0 # 不浇水
WATER = 1 # 浇水
class Config:
"""配置常量类"""
OUTPUT_DIR = "results/"
GAMMA = 0.9
THETA = 1e-6
MAX_ITERATIONS = 300
TRUNCATION_LIMIT = 3
FONT_CONFIG = {
"preferred_fonts": ["DejaVu Sans", "Arial", "Helvetica", "Liberation Sans", "sans-serif"],
"m 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









